現在、機械学習が大ブームを巻き起こしており、各種ビジネスへ応用拡大の勢いはとどまるところを知りません。一方で、「“機械学習”という名前は聞くけど、よくわからない…。」、「“機械学習”について学んでみたいけど、プログラミングに自信はない…。」などと考えている方も少なくないはずです。そこで本記事では、煩わしいプログラミングなしで機械学習が学べる「Machine Learning Using SAS Viya」という学習コースについてご紹介します。
「Machine Learning Using SAS Viya」は、オンライン学習プラットフォーム、「Cousera」のコースの一つです。SAS Viya for LearnersというSAS の教育用環境を使用し、オンライン上で実際に手を動かしながら機械学習の基礎を学べます。GUIでの操作が基本であるため、プログラミングに自信のない方でも取り組めることが特徴です。本コースは六週間分のパートに分かれており、無料で教材の内容全ての閲覧が可能です。また、コースを購入すると採点機能の利用や修了証の発行などの機能も利用可能です。コースの言語は英語で、コース内動画は英語字幕に対応しています。
シラバスは以下のとおりです。
- Week1:Getting Started with Machine Learning using SAS® Viya®
- Week2:Data Preparation and Algorithm Selection
- Week3:Decision Tree and Ensembles of Trees
- Week4:Neural Networks
- Week5:Support Vector Machine
- Week6:Model Deployment
本記事ではWeek1・Week2の内容を各セクションごとにご紹介します。
Week1:Getting Started with Machine Learning using SAS® Viya®
・Course Introduction and Logistics
まずは本講座で使用するSAS® Viya® for Learnersへ登録についてご説明します。Courseraのアカウントに登録したものと同じメールアドレスを使い、 こちらからSAS Profile を作成します。作成後、コース内の「ツールを開く」というボタンからSAS® Viya® for Learnersにアクセスし、先ほど作成したSAS Profileを使ってログインします。推奨ブラウザは、Chrome・Firefox・Safariです。本講座はデモの実演動画を参考にGUI上で実際に操作ながら学習を進める形式ですので、教材を参考に自分でモデルを構築したり各種設定を変更したりしながら理解を深めていきましょう。
・Machine Learning in Business Decision Making

本コースでは通信事業会社の事例を題材とします。新規顧客の獲得に比べ既存顧客の契約継続は低コストで実現できるため、顧客の解約率を下げることは重要なビジネス課題です。そのためには、どのような顧客が解約しやすく、どうすればその顧客を維持できるかを理解する必要があります。そのため本コースでは、使用製品データ・利用方法データ・支払いデータなど、計128項目のデータに基づき、顧客の解約可能性を予測するモデルを作成することが最終的な目標です。ここでは、その基礎となるSAS Viya の基本事項と機械学習のビジネスへの応用例について学習します。データ分析において重要なData, Discovery, DeploymentからなるAnalytics Life Cycleについて学び、デモを参考に必要な下準備を行いましょう。
・Supervised Prediction: Preparing the Data and Building the Initial Model
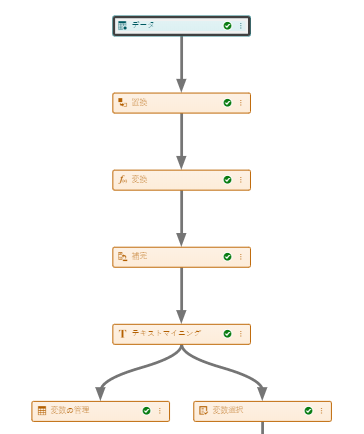
最初にAnalytics Life CycleにおけるDataの段階を学習します。データの前処理は予測モデル作成において非常に重要な段階で、データ分析者が一番時間をかける作業だと言われています。本セクションでは、モデルのバイアス・バリアンスの考え方とそれに対応するデータの分割や、欠損値の各種処理方法を学習します。また、データ前処理からモデル構築、モデルの評価までをひとまとめにしてつなぐパイプラインをテンプレートから作成し、ロジスティック回帰を使ったモデル構築を実践しましょう。教材内でのBasic template for Class Targetは、SAS® Viya® for Learners上では「分類尺度のターゲット変数の基本テンプレート」と訳されていますのでご注意ください。
・A Closer Look at SAS® Viya®
SAS® Viya® の仕組みについて詳しく学習します。GUIの後ろで動いているCAS(Cloud Analytics Services)システムの動作原理や、SAS® Viya® の基本的特徴についておさえましょう。
Week2:Data Preparation and Algorithm Selection
Week2ではデータの前処理についてさらに深く学び、また、モデル作成とモデル選択を実践します。
・Exploring Data and Incorrect Values
データの内容をより深く理解することはデータ分析において最も重要なポイントの一つです。グラフや各種統計量を用いて各要素の特徴や要素間の関係を実際に把握してみましょう。その過程で、正しくないデータの存在に気付くことがあります。もちろん、何が正しくないデータで、それらを何で置換すべきかは実際のビジネスとの関連で決めなくてはなりません。モデルの性能向上のため、各種手法を学びそれらを適切なものに置き換えてみましょう。
・Creating Features
既存の変数から新たな変数を作成すれば、隠れた特徴を見出せるかもしれません。テキストマイニングの手法を用いて新たな特徴量を作成し、モデルの性能が改善できたか確かめましょう。また、SVD分解・PCA・RPCA・単層オートエンコーダー・多層オートエンコーダーについての理論も学習します。
・Transforming Inputs
データの中には、誤りではないものの極端なデータが入っていることがあります。モデルに過度に影響を及ぼす可能性が考えられるため、バイアスを最小化するよう補正を行います。例として標準化やビニングなどの手法が紹介されていますが、その他にも様々な手法が使用可能です。実際に手を動かして試してみましょう。
・Selecting Features
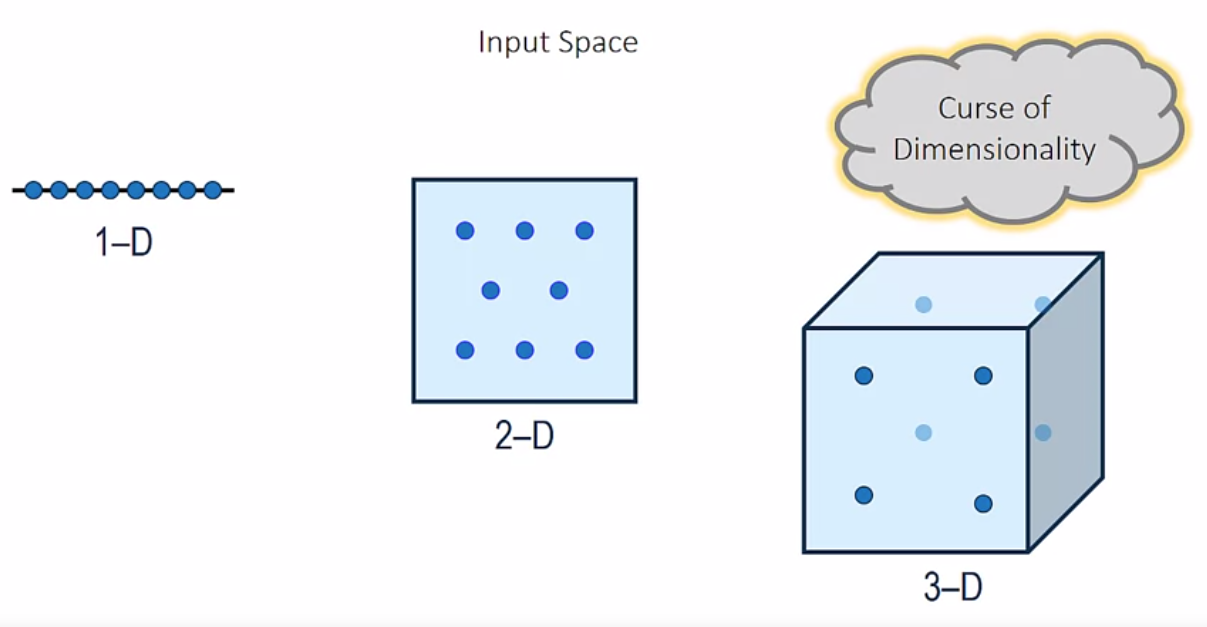
高次元の入力データに対しては組み合わせ数が膨大になり、機械学習アルゴリズムが十分な性能を示せなくなることがあります(次元の呪い)。まったく関係のない変数や、他の変数とほぼ同じ情報をもつ変数(情報の無駄)を削減し、重要な変数のみを抽出する手法を学習しましょう。
・Best Practice in Data Preparation
データ前処理についてこれまで学習したことの総まとめのセクションです。データにはどのような問題が潜んでいるのか、また、それらを補正するにはどの手法を用いればいいのか、再度整理しましょう。
・Selecting an Algorithm
 データ前処理について一通り学び終えました。いよいよAnalytics Life CycleのDiscoveryの段階に入ります。本格的な内容は第三週以降学習しますが、ここでは、モデル選択時に考慮すべき観点について学びます。ビジネスへの応用の場面では、データのサイズや特徴・プロジェクトの期間・必要な制度・解釈可能性などを踏まえて最適なモデルを採用する必要があります。それぞれのモデルの長短を学習しましょう。
データ前処理について一通り学び終えました。いよいよAnalytics Life CycleのDiscoveryの段階に入ります。本格的な内容は第三週以降学習しますが、ここでは、モデル選択時に考慮すべき観点について学びます。ビジネスへの応用の場面では、データのサイズや特徴・プロジェクトの期間・必要な制度・解釈可能性などを踏まえて最適なモデルを採用する必要があります。それぞれのモデルの長短を学習しましょう。
以上がWeek1・2の内容になります。Week3・4については次回の記事で、Week5・6についてはこちらの記事でご紹介しておりますので、併せてご参照ください。Machine Learning Using SAS Viyaにはこちらからアクセスできますので、どうぞご活用ください。