PythonからSAS Viyaの機能を利用するための基本パッケージであるSWATと、よりハイレベルなPython向けAPIパッケージであるDLPyを使用して、Jupyter NotebookからPythonでSAS Viyaの機能を使用して一般物体検出(Object Detection)を試してみました。
今回は、弊社で用意した数枚の画像データを使用して、処理の流れを確認するだけなので、精度に関しては度外視です。
大まかな処理の流れは以下の通りです。
1.必要なパッケージ(ライブラリ)のインポートとセッションの作成
2.一般物体検出向け学習用データの作成
3.モデル構造の定義
4.モデル生成(学習)
5.物体検出(スコアリング)
1.必要なパッケージ(ライブラリ)のインポートとセッションの作成
swatやdlpyなど、必要なパッケージをインポートします。
from swat import * import sys sys.path.append(dlpy_path) from dlpy.model import * from dlpy.layers import * from dlpy.applications import * from dlpy.utils import * from dlpy.images import ImageTable from dlpy.splitting import two_way_split from dlpy.blocks import * import cv2 import numpy as np import pandas as pd import random import matplotlib.pyplot as plt from PIL import Image from IPython.display import display |
次にSAS ViyaのインメモリーエンジンであるCAS(Cloud Analytic Services)に接続しセッションを作成し、必要なアクションセットをロードし、ライブラリを作成します。
s = CAS(host, port, user, password) s.loadactionset('image') s.loadactionset('deepLearn') s.table.addcaslib(activeonadd=False,datasource={'srctype':'path'}, name='dnfs',path=path,subdirectories=True) |
2.一般物体検出向け学習用データの作成
DLPyに搭載されているcreate_object_detection_table()メソッドを使用することで、一般物体検出向けに、必要なフォーマットの学習用データを簡単に作成することができます。
create_object_detection_table()メソッドに関しては、こちらのブログも参照ください。
object_detection_targets = create_object_detection_table(s, data_path = '/opt/sasinside/DemoData/DeepLearning/object_detection_dlpy/trainData/', coord_type = 'yolo', output = 'detTbl') |
'/opt/sasinside/DemoData/ DeepLearning/object_detection_dlpy/trainData/'ディレクトリ内には、画像データ(.jpg)と注釈(annotation)データ(.xml)が格納されています。
このメソッドを実行するだけで、以下のようなフォーマットの学習用データが出来上がります。簡単ですね!
s.columninfo('dettbl') |
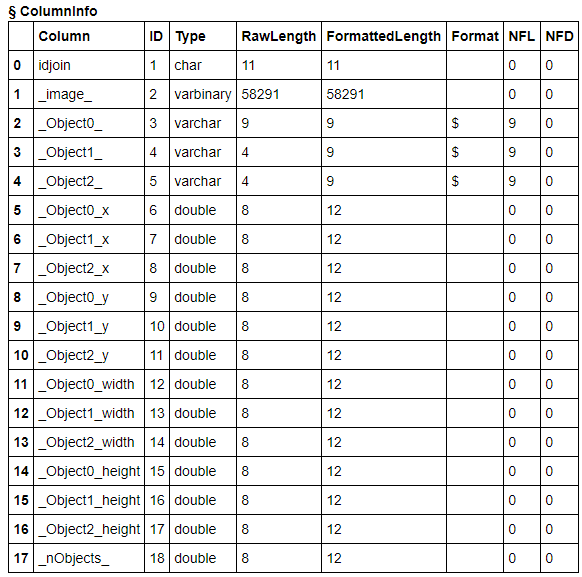
idjoin: 画像ごとのユニークID
_image_: 画像データ
_Objectn_: 物体のカテゴリ名
_ Objectn_x: バウンディングボックスのX軸座標
_ Objectn_y: バウンディングボックスのY軸座標
_ Objectn_width: バウンディングボックスのxy座標からの幅
_ Objectn_height: バウンディングボックスのxy座標からの高さ
_ nObjects_: 画像内の物体の数
作成された学習用のデータに含まれる画像をDLPyに搭載されているdispaly_object_detections()メソッドを使用して表示してみましょう。
display_object_detections(s, 'detTbl', 'yolo', max_objects=3, num_plot=6, n_col=3) |

3.モデル構造の定義
入力変数(カラムリスト)とターゲット変数(カラムリスト)を定義します。
targets = ['_nObjects_']; for i in range(0,3): targets.append('_Object%d_'%i) for sp in ["x", "y", "width", "height"]: targets.append ('_Object%d_%s'%(i, sp)) inputVars = [] inputVars.insert(0, '_image_') print ("targets") print (targets) print ("inputVars") print (inputVars) |
targets ['_nObjects_', '_Object0_', '_Object0_x', '_Object0_y', '_Object0_width', '_Object0_height', '_Object1_', '_Object1_x', '_Object1_y', '_Object1_width', '_Object1_height', '_Object2_', '_Object2_x', '_Object2_y', '_Object2_width', '_Object2_height'] inputVars ['_image_'] |
ご覧の通り、2.項で作成したデータセット内の画像データが入力変数で、その他の項目がターゲット変数になります。
次にアンカーボックスを定義します。
DLPyに搭載されているget_anchors()メソッドを使用し、トレーニングデータセット内の複数のオブジェクトに対する最も代表的な形状(アンカーボックス)を自動的に見つけ出してくれます。
以下の例では、アンカーボックスを3つ生成しています。
dettbl = s.CASTable('detTbl') anchors = get_anchors(s, data='detTbl',coord_type='yolo', n_anchors=3) anchors |
(1.1121093750000002, 2.3765625, 0.8246875000000001, 0.9127083333333335, 1.3431640624999999, 2.9927083333333337) |
いよいよ、モデル構造を定義します。
DLPyに搭載のTiny_YoloV2()メソッドを使用し、必要なパラメータを指定して、Object DetectionのためのTiny YoloV2モデル、つまりYOLOV2の非常に小さなモデル構造が生成されます。
model = Tiny_YoloV2(s, n_classes=3, width=416, height=416, predictions_per_grid=3, anchors = anchors, coord_type='yolo', max_label_per_image = 3, class_scale=1.0, coord_scale=1.0, prediction_not_a_object_scale=1, object_scale=5, detection_threshold=0.2, iou_threshold=0.2) |
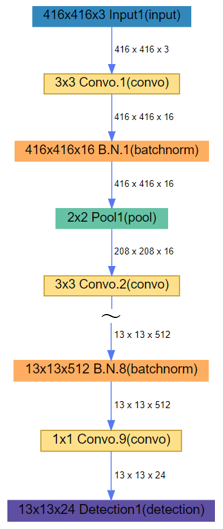
生成されたモデル構造をビジュアライズしてみましょう。
DLPyに搭載のplot.network()メソッドを使用し、モデルのネットワーク構造をグラフィカルなネットワーク図として可視化することができます。
model.plot_network() |
4.モデル生成(学習)
まず、事前に学習済みのweightをロードします。
s.table.loadtable(casout={'name':'jersey_ball_obj_det_initweights','replace':True}, caslib='dnfs',path="jersey_ball_obj_det_initweights.sashdat"); |
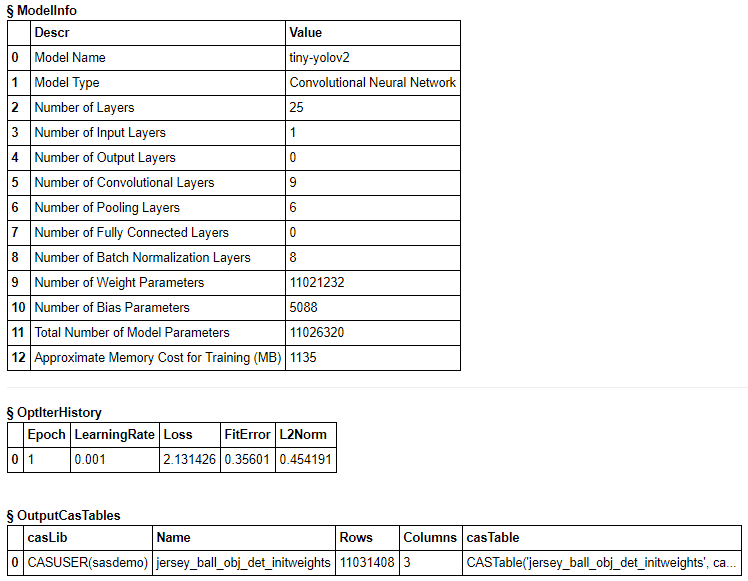
最適化パラメータを設定し、モデルを生成(学習)します。
今回は、精度は度外視なので、最短で処理が完了するようにミニバッチサイズ=1、エポック=1、としています。
solver = MomentumSolver(learning_rate=0.001, clip_grad_max = 100, clip_grad_min = -100) optimizer = Optimizer(algorithm=solver, mini_batch_size=1, log_level=2, max_epochs=1, reg_l2=0.0005) data_specs = [DataSpec(type_='IMAGE', layer='Input1', data=inputVars), DataSpec(type_='OBJECTDETECTION', layer='Detection1', data=targets)] model.model_weights = s.CASTable('jersey_ball_obj_det_initweights') model.fit(data='dettbl', optimizer=optimizer, force_equal_padding = True, record_seed = 13309,data_specs=data_specs, seed=13309, n_threads=5) |
NOTE: Training based on existing weights. NOTE: The Synchronous mode is enabled. NOTE: The total number of parameters is 11026320. NOTE: The approximate memory cost is 1134.00 MB. NOTE: Loading weights cost 0.97 (s). NOTE: Initializing each layer cost 0.47 (s). NOTE: The total number of threads on each worker is 5. NOTE: The total mini-batch size per thread on each worker is 1. NOTE: The maximum mini-batch size across all workers for the synchronous mode is 5. NOTE: Epoch Learning Rate Loss Fit Error Time (s) NOTE: 0 0.001 2.1314 0.356 1.39 NOTE: The optimization reached the maximum number of epochs. NOTE: The total time is 1.39 (s). |
5.物体検出(スコアリング)
生成されたモデルに当てはめるテストデータをロードします。今回はトレーニング用と同じ画像をテスト用として使用し、サイズを調整します。
test = ImageTable.load_files(s, '/opt/sasinside/DemoData/DeepLearning/object_detection_dlpy/trainData/', casout={'name':'test'}) test.resize(height=416, width=416, inplace=True) |
テスト用の画像データを表示してみます。
test.show(ncol=3) |

モデルにテストデータを当てはめて、予測(スコアリング)を実行します。
model.predict(data=test,layer_out='predict_res_tbl') |
最後に、物体検出の結果を表示してみましょう。
display_object_detections(conn=s, coord_type='yolo', max_objects=3, table=model.valid_res_tbl, num_plot=5, n_col=3) |

精度は度外視とは言え、「ボール」はだいたい認識できているようです。
DLPyパッケージを使用することで、より簡潔なコーディングで、一般物体検出(Object Detection)が実施可能であることを感じ取ってもらえたでしょうか!?
※上記コードを実際に実行している動画は、オープン・AIプラットフォーム「SAS Viya特設サイト」で公開しています。
※物体検出の仕組みについては、「ディープ・ラーニングにおける物体検出」 もご参照ください。
