反省&改善プラン中
SAS JapanのWebサイトにある「機械学習」特集ページは、サーチ・エンジンやバナー広告などから日々、多くの方々にご覧いただいています。昨年後半からは爆発的に訪問者数が増えており、機械学習への関心の高まりを感じている一方で、弊社としては実はこのページは改善が必要と考えています。なぜなら、機械学習の特徴だけが書かれていて、それをどのように利用すれば皆様のビジネス課題を解決できるか、という次のステップをご案内していないからです。これまで、アナリティクスの世界に携わってきた方にとっては、最近バズワード的に使用され始めた感のある「機械学習」というキーワードの特徴が書かれているこのページを見ることで、「なんだざっくりえば、いつも使用している予測モデルのことか」とすっきりしますが、昨今のビッグデータや機械学習ブームで機械学習について突然学ぶ必要が生じた方々にとっては、あまり役立たなかったのではないかと反省中です。
昨今の機械学習ブームは、これからデータを活用してビジネスに役立てようとしている方には実は情報が不足していると感じています。新しいテクノロジーをどのようなプロセスで活用すれば良いのかという指南が不足しています。これは、それを以前から知っていたのに周知できていなかった弊社の努力不足でもあります。
今回は、少し長くなりますが、SASとしては、企業の経営課題をアナリティクスで解決するという視点から機械学習を活用するためのビジネスプロセスについての話をします。簡単に機械学習、予測、アナリティクスを定義した上で、一番大事な活用するためのビジネスプロセスについて、全貌を一気にご紹介します。
機械学習とは
機械学習についての一般的な見解については、また別途詳しくお伝えしたいと思います。ここでは簡単に統計解析、データマイニング、機械学習の違いから、機械学習を理解していただきます。何事も対象を理解するためには、対象そのものを詳細に記述するよりは、他と比較するほうが理解しやすいためです。
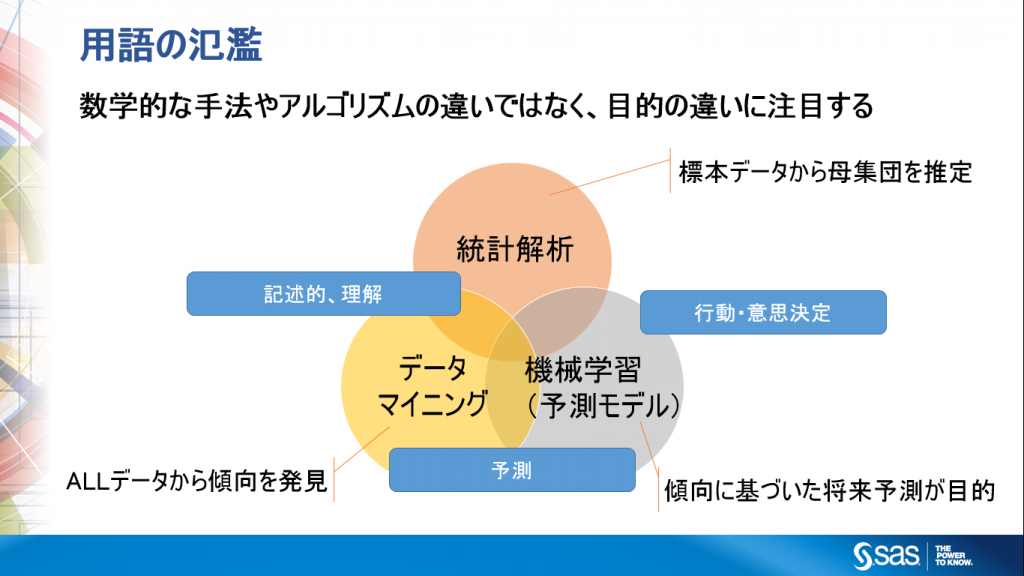
- 統計解析
標本データ(一部のサンプリングデータ)から母集団を推定することを主目的として使用される。限られたデータから世の中を理解したりモデル化するとも言える。
- データマイニング
「鉱山から金塊を見つける」という直接的の意味のように、大量データから意味のあるパターンを発見することを目的とする。データからパターンを見出すため、後述の機械学習の学習フェーズそのものと重なるところが多い。
- 機械学習
既知のデータ、すなわち過去のデータからパターンを見出し、それを将来を予測することを目的に使用する。その目的から、従来は「予測モデル」という言葉で表されることが多かった。
実は、これらは使用している数学的な手法やアルゴリズムはほとんど同じです。もちろん各目的に対して適不適はありますが、まずは、総じて目的が異なるだけだと理解してください。例えば、伝統的な統計解析の手法を工夫しながらビッグデータに適用し予測モデルとして活用するケースもありますし、SASではデータマイニングの結果、使用したアルゴリズムと学習の結果をそのまま、予測モデルとして使用することが可能となります。また、コンピューターの性能向上に伴って脚光をあびるようになった手法もあります。
世の中を理解するためにデータを使用するところから、一歩進んで、その理解に基づいて、次に何が起こりそうなのかを予測し、ビジネスにおいて次に何をすべきかを決定していくといった使い方に変わってきたのです。昨今、機械学習アルゴリズムは多数ありますが、市民データサイエンティスト(Gartner 2015)の方は、その細かいアルゴリズムを理解するところからスタートするのではなく、何のために使用するのかをというビジネス上の目的からスタートすることを推奨します。細かいところは歴史的な流れと共に理解しないと本質がわからないこともあり、いきなり機械学習アルゴリズムの理解からスタートする方法は、学習方法としては非効率です。
アナリティクスにおける予測とは
データを活用して統計解析やデータマイニング、機械学習といった手段を用いながら、ビジネスにおいてよりよい意思決定をする、言い換えれば、よりよいアクションを実施することをアナリティクスと言います。アナリティクスはその語源をたどると、不確実性を伴う将来に対して勇気を持って踏み出すと意味があります。データに基づいて意思決定をするということは不確実性、すなわち、確率にもとづいて行動することです。予測結果はどこまでいっても確率的にしか表されませんが、「より起こりやすい」ことを見出すことが可能です。これがよりよい意思決定につながります。
「より起こりやすい」ということを、すでにアナリティクスを実践している人々は、「予測精度が高い」と表現したりします。予測精度をあげることで、売り上げ向上やコスト削減の期待効果が大きくなります。それをわかりやすく表現すると、「予測精度を上げることで売り上げが向上する」となるわけです。将来は、(預言者でないかぎり)確率的にしか予測できないので、あえて表現していませんが、「予測」の裏には確率的な要素が常に含まれています。
チャーン分析やキャンペーンの反応率の分析などでは、ある顧客が解約しそうな・反応しそうな確率を算出するので、確率という考え方が理解しやすいと思います。このタイプを英語ではPredictionと言います。将来のある時点の状態を予測するタイプです。一方で、Forecastingというタイプがあり将来の一定期間の数や量を予測するタイプのものです。そのひとつ、需要予測の値も実は確率的な予測です。需要予測の場合には、予測値そのものの絶対値が注目されがちですが、その予測値がどの程度の確率の幅におさまるかを算出し、その確率の幅すなわち、リスクに対してどのように対処するかどうかが、本当はポイントになります。製品やサービスの特性に応じて、リードタイムを小さくしたり、あるいは確率の幅に応じた安全在庫を持ち、欠品率という顧客サービスレベルのコントロールに役立てます。需要予測のポイントは、予測値の絶対値をピタッと当てることではなく、この確率の幅を定量的に管理することだと言っても過言ではありません。在庫や輸送コストと顧客満足度とのトレードオフを扱う最適化問題でもあります。
企業が利用できるリソースには限りがあります。したがって、この確率の幅が無限大では意味がありません。つまり、100%的中する「0以上」という予測結果には意味がありません。制約のあるリソースで、効果を最大化する必要があります。したがって、この確率の幅を出来るだけ狭めることが重要になります。さらには、その作業にかける時間はすなわち意思決定の時間になりますので、予測結果を出すまでの時間が長ければ意思決定が遅れることになります。
「予測」というと、日本ではまだまだ十分に理解・活用されていないと感じます。市場動向の予測や売り上げ予測といった「参考資料」のようなものとしか位置づけていない定義も多く、それでは正しく理解していないだけでなく、価値をほとんど享受できていません。アナリティクスにおいては、予測結果は単なる「参考資料」ではなく、その予測結果に基づいて直接的に意思決定を行うためのものであるということがポイントです。「次にこういうアクションをするとこういう結果が得られるだろう」という将来の見込みを確率的に定量的に算出することがアナリティクスにおける「予測」です。アナリティクスで競争優位に立っている企業では、予測モデルに基づいたアクションの方が、従来の経験と勘に基づいていたときよりも、スピード・精度ともに勝っていることを証明しています。言い換えると、人の意思決定を自動化しています。自動化というと機械やシステムのみに適用されがちですが、例えば自動発注システムも、本来は人が発注数を決めるという人の意思決定を自動化しているように、日々の人のビジネス上の意思決定を自動化するという感覚がアナリティクスでは重要です。
実際には、コールセンターで人間が画面を見て予測結果に基づいて対応している例もあれば、オンラインストアのレコメンデーションや広告配信システムの様にシステムに予測モデルが組み込まれ、すなわち業務プロセスに組み込まれて意思決定が自動化されているケースもあります。
アナリティクス・ライフサイクル(簡潔版)
SASでは、40年間アナリティクスで世界中の企業を支援してきました。その中で出来上がったベストプラクティスの一つに、「アナリティクス・ライフサイクル」というものがあります。これは、企業組織が機械学習すなわち予測分析を用いてアナリティクスを実践する、すなわち、データを活用してよりよい意思決定をすることで競争優位性を身につけるために実践すべきプロセスです。SAS主催イベント「ビッグデータ活用の新しいカタチ」(2015年12月8日開催)のデモンストレーションで紹介したサイクルは以下のようなものです。
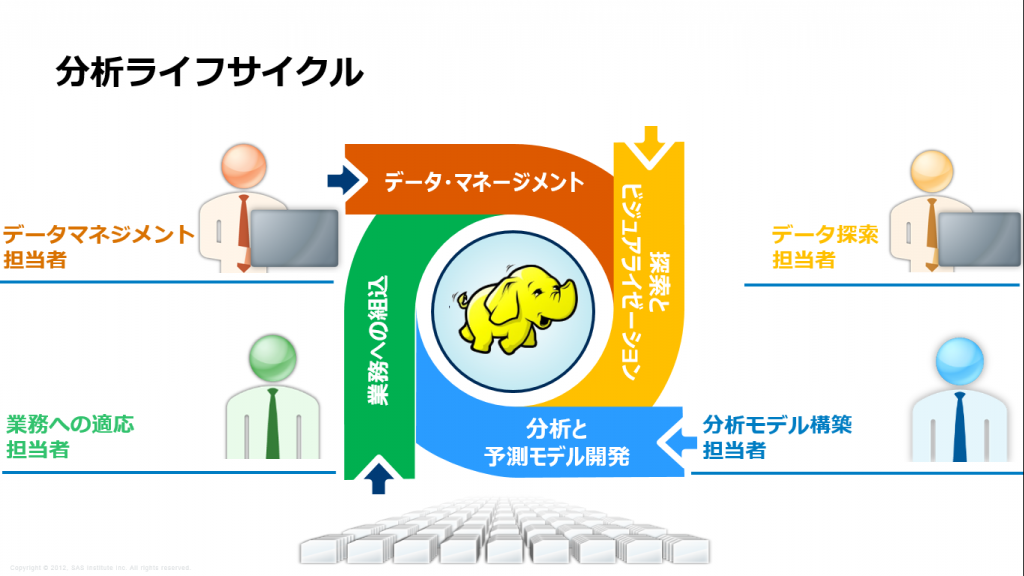
このときには、簡潔性を重視したため、4つのプロセスだけで構成されています。
- データマネージメント
必要なデータを収集・統合して必要な品質・形に変換する。昨今では、このプロセスをデータ・キュレーションと称することもあるようです。ご存知のとおり、全体のプロセスのうち約80%がこのプロセスに費やされていると言われています。下記のブログもご参照ください。
ブログ:アナリティクスの効果を最大化するデータマネージメント勘所
- データの探索とビジュアライゼーション
データの基本性質を確認したり、パターンや関連性などを見出し洞察を得る。近年、セルフサービスBIツールによるデータ探索が流行しています。操作性ばかりが注目されがちですが、実は、主観や仮説に基づく探索作業は網羅的ではないため、真の傾向や真の問題点の発見には方法としては十分ではありません。そういった主観に依存した視点の偏りを防ぎ網羅的な探索をするためには、統計的・数学的手法やデータマイニング手法が活躍します。以下のブログでは紹介していませんが、SASの探索・ビジュアライゼーションツールに統計解析やデータマイニング手法が含まれているのは、まさにそのためです。
ブログ:SAS Visual Analyticsによるパス分析
- 分析と予測モデル開発
データマイニングや機械学習アルゴリズムを使用して、将来を確率的に予測する「モデル」を作成する。過去のデータを使用してパターン化(学習)するところは様々な数学的アルゴリズムが使用できますが、ソフトウェアがやってくれます。昨今は進化したソフトウェアでより簡単に精度の高いモデル開発が可能となっています。
- 業務への組み込み
作成した予測モデルを使用して意思決定、すなわちアクションを実践する。例えば、顧客スコアを算出しキャンペーンを実施したり、コールセンターでの応対を変えたり、レコメンデーションに役立てたり、不正な金融取引を検出したり、設備の異常を検知するなどの、意思決定プロセスに活用します。
このプロセスを素早くまわすこと、それは意思決定のスピードに直結することを意味します。また、データを適切に準備し、全件データを使って精緻な予測モデリングをすることで、精度の高い予測モデルを作ることができ、それはすなわちよりよい意思決定を意味します。スピードが増せばその分PDCAサイクルがたくさん回ることになるので、それは結果の質の向上につながります。したがって、アナリティクスのためのIT環境をアセスメントする際には、ビジネス上の価値の視点から、まず、このサイクルが効率的に・高速にまわせるかどうかということが評価の基準になります。
アナリティクス・ライフサイクル(詳細版)
実はアナリティクス初心者には前述の簡易版は適切ではありません。重要なプロセスが暗黙的になっているからです。弊社のアナリティクス・ライフサイクル、完全バージョンは以下のようになります。
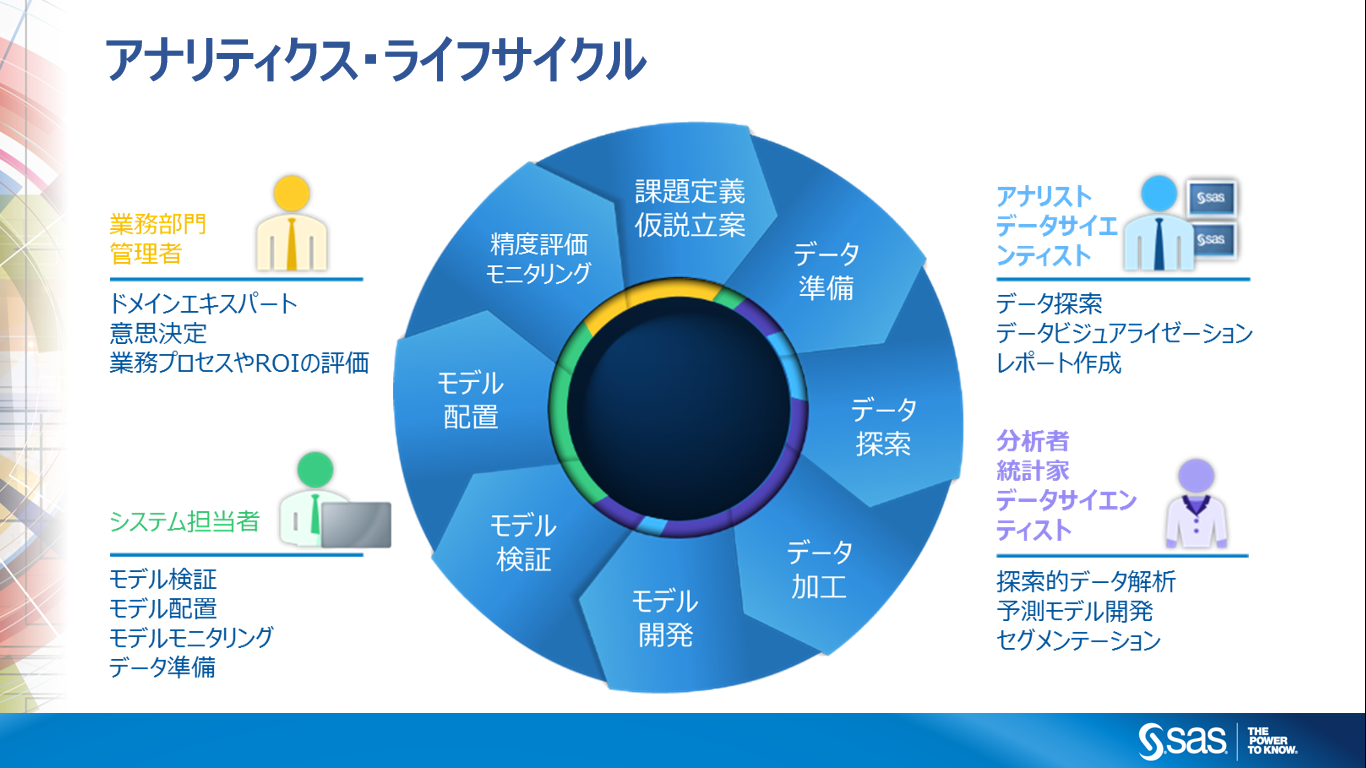
今回取り上げたい重要なポイントは、
- 課題定義
まず最初にすべきことはデータ分析・予測モデルの活用で解決したいビジネス上の課題定義
- 精度評価・モニタリング
データ活用は、アクション⇒検証プロセスを経るサイクルであることと、評価の方法に注意すべき
の二つです。データ分析が広まる中、データ分析そのものが目的化している残念なケースが多く見受けられますが、データの活用はあくまでビジネス課題(売り上げの増加、コストの削減、リスクの管理)を解決することを目的としています。したがって、「データ分析をしたがビジネスに役立たない」という表現は、そもそもおかしいことになります。多くの場合、そこで使われている「データ分析」は単なる見える化(ビジネス・インテリジェンス)を指しています。現状の把握です。それだけでは現状がわかるだけですので、もちろん売り上げは増大しません。セルフサービス型BIツールを使用して起きたことに対するパターンの発見があっても、それだけでは意思決定するためには不十分です。次にどのようなアクションをとれば、どの程度売り上げ増大が期待できるのか?という問いに答えることで初めて経営指標に貢献できます。つまり、目的ありきで、データを分析する必要があるのです。そして、そのためには、予測モデルを作成する必要があります。
ただし、ビッグデータさらにはIoT時代に突入し、この「目的ありき」も少し様相が変わってきました。それは後述します。
一方で、アナリティクスは継続的な改善を続ける作業です。わかりやすく言うとPDCAサイクルをまわすことで、精度を上げていくことが重要です。特に顧客とのコミュニケーションにアナリティクスを活用する際には、アクションを実施した後のフィードバックがとても大事です。それにより、新たなデータが取得でき、予測モデルに反映することができます。
結果の評価は、これもまた確率で捕らえる必要があります。個々のデータであるAさんに対する予測結果があたったか外れたかを見ることには意味がありません。全体として確率的にどうであったかを見る必要があります。
スピードと精度が競争優位に直結する
企業においてこのプロセスを回すためには、複数の役割・部門が関わってきます。その部門間・役割間をまたがるこの一連のサイクルを効率的にまわすことができるかどうか、それが競争優位性に直結します。
従来このサイクルは、週・月単位でしたが、昨今ではこのサイクルを一晩でまわす必要に迫られている競争が激しい市場もあります。一方で、データは増大しているため、それを支えるテクノロジーとアーキテクチャーが重要になってきます。
業種や業務によっては、予測モデルの更新時の社内承認プロセスが非効率だったり、データがすぐに利用可能な状態になっていなかったり、データの品質が良かったり・悪かったり、データの処理そのものが遅いなどボトルネックは様々です。このサイクルに沿って現在のプロセスを見直して見ることで、ボトルネックを発見し、改善に向かうことができるようになります。
アナリティクス・ライフサイクル(ビッグデータ・IoT時代用)
従来のデプロイメントプロセス(業務への適用)は、多くはバッチ処理型のテクノロジーで実施していました。これが近年のビッグデータのVである、Velocityという特徴によって変わりつつあります。ストリーミングデータの出現です。予測モデルによるスコアリング処理をストリーミングデータに適用したいという需要が出現してきており、既にそのような使い方をしているお客様が登場しています。このような背景から、アナリティクス・ライフサイクルのうち、探索や予測モデル開発、および業務への組み込みプロセスにおいて、変化が起きています。
アナリティクス・ライフサイクルにみる近年の変化
- 探索と予測モデル開発プロセス
ビッグデータ時代においては、予測モデリングにおいて、Hadoopやインメモリアナリティクス技術が必要とされています。アナリティクスはスピードと精度が収益に直結するからです。世の中が依然としてこのような新しい技術の理解や試行段階にある企業が多い中、SASユーザーは既に実際のビジネス課題の解決にSAS製品を利用して同様の技術を活用しています。
- 業務への組み込みプロセス
ビッグデータ・IoT時代での新しい変化は、このプロセスがリアルタイム化-すなわち意思決定がリアルタイム化されたことです。すなわち、絶え間なく発生するストリーミングデータに対してリアルタイムに予測モデルを適用してスコアリングが行われます。これをストリーミング・アナリティクスと呼んだりします。
これら二つのプロセスは、必要とされる実行環境・テクノロジーと、実行タイミング・求められるスピードが異なります。例えば、ストリーミング環境へデプロイされたスコアリング処理は絶え間なく実行されますが、そのための予測モデルの再作成・再学習はそのモデルが陳腐化したタイミングで実施するため、絶え間なく実行するとは限りません。それを業務プロセスとして考慮すると、アナリティクス・ライフサイクルは以下の様にしたほうが実情に近いのではないかと弊社では考え始めています。
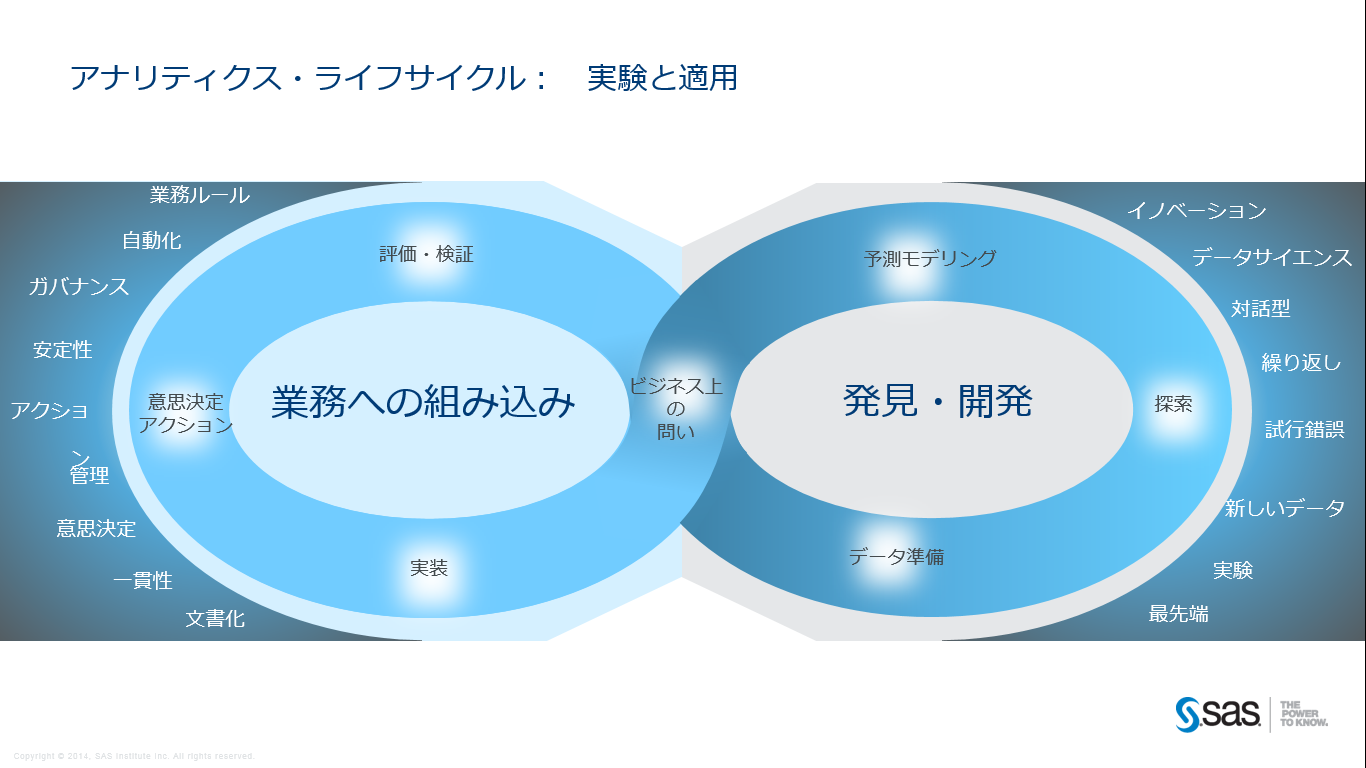
ビッグデータ・IoT時代には、これら二つのプロセスそれぞれの性質に合わせたテクノロジーを適材適所で利用し、全体として経済的合理性を意識したシステム投資が求められます。
一方、デベロップメントプロセスにおいて、業種や業務によっては、新しく取得可能になったデータを活用して、新しいビジネス・モデルを生み出したいというイノベーションへの期待が高まっており、弊社にもそういった相談が増えています。が、その話はまた別の機会にしたいと思います。
まとめ
ところどころ寄り道が多く、焦点が定まらない回になってしまったかもしれません。
まずは自社のデータ活用プロセス、アナリティクスプロセスをご紹介したアナリティクス・ライフサイクルに当てはめてみてください。そして以下のことをチェックしてみてください。
- 各プロセスがもれなく実践されているか
- 各プロセスが質・スピードともに十分に機能しているか
- 各プロセスがシームレスにつながっているか
- ライフサイクル全体のスピードはビジネスの要求に応えられているか
- ライフサイクル全体が統制・管理・レビューされているか
これらのなかで見つかった課題を解決することで、データ活用やアナリティクスの取り組みの経営課題解決への貢献度を高めることになります。皆さんの企業・組織におけるアナリティクスに関連するIT環境や分析ツールの現状、IT投資・分析ツールへの投資のプラン、協力会社からの提案内容をこれらのチェックポイントに当てはめることで、その投資がビジネス価値を生むかどうかをはかることも可能となります。
弊社でもそのようなアセスメントをサービスとして提供しておりますので、ご興味のある方は是非お声掛けください。
