変わ(る・るべき・れる)データマネージメント
データ、さらにはビッグデータを使用して競争優位性を獲得しようとするにつれて、企業・組織はよりスピード感をもって、試行錯誤を繰り返す必要にせまられおり、データマネージメント戦略やアプローチについても従来とは異なる方法にシフトしつつあります。
-
これまでのアプローチ
従来のアプローチでは、まず、ビジネスユーザー部門が「問い」を決めた上で、IT部門が「問いへの答え」のためのインフラとデータを準備していました。例えば、「先月の地域別、製品別、チャネル別の売り上げはどうなっているか?」や、顧客へのアンケートに基づいて、「顧客は何を考えているか?」などです。このような過去や現状を把握するための「問い」は、ほとんどの企業・組織で共通している、基本的な業務プロセスを実行するために適した方法です。
この方法では、ユーザー部門が本当に欲しい答えを得るまでにはIT部門と何度もやり取りを繰り返す(Iteration)必要があります。その作業には数週間要するケースも少なくありません。ビジネスユーザーにとっては、事前に完璧な「問い」をシステム的な要件として定義することは困難であり、一方でIT部門は業務に対する理解が100%完全ではないためです。しかし、ひとたび、ITインフラやデータが用意されると、その後は、「決まりきった反復的な(Repeatable)」分析、すなわち現状を把握するための分析(これはAnalysisです)ビジネス・インテリジェンスという目的に使用されます。
-
アナリティクスおよびビッグデータ時代のアプローチ
新たな洞察の発見や予測モデルを作成し、よりよい意思決定やアクションを実践することを主目的とするアナリティクスにおいては、このプロセスが極端に言えば逆になります。まず、IT部門が収集したデータを蓄積する基盤を構築し、その後にビジネスユーザーがその基盤を利用して新しいアイディアや問いを探索するという順序です。この作業は、創造的な発見的プロセスであり、ビジネスユーザーは使用しているデータが特定の目的にあっているかどうかを自身で判断することができると同時に、これまで知らなかった傾向や関係性を明らかにしたり、更なる深い分析のために役立つかもしれないデータを見つけたりします。
この新しいアプローチの特徴は、ユーザー自身でデータ加工やその先の分析を繰り返し実施(Iterative)することに適しているということです。アナリティクスにおいては、仮説検証、試行錯誤、さらには失敗をいかに高速に実施するかが重要なため、この繰り返し作業(Iterative)をユーザー自身で迅速に行う必要があるのです。
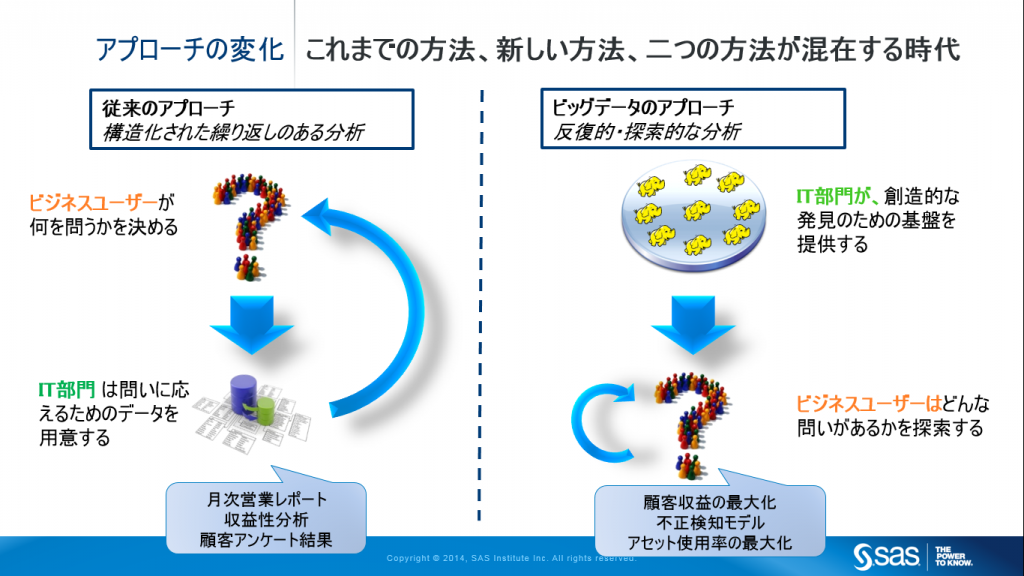
RepeatableとIterationとの違い
同じ動作を繰り返す、例えば毎月同じ種類のデータに対して同じクエリーを実行しレポートを作成するようなことがRepeatableです。それに対してIterationとは、異なる動作を繰り返す事を指し、データや見方を変えながらデータを探索しつつ仮説検証を繰り返したり、予測モデル作成や機械学習アルゴリズムのための説明変数や特徴量を探索しながら作成していくことを意味しています。BIレポーティングは、 Repeatable, アナリティクスはIterativeと覚えておいてください。
Iterativeなデータ加工プロセスでは以下のように、SQLだけでは困難な処理が多く含まれます。
- 集約(合計や平均などだけではなく、中央値や標準偏差などを含む)
- 転置(下記ABTにも関連)
- 統計的判断(ある事象、たとえば売り上げの減少が、単なる偶然のバラツキの範囲なのかなのかそうでないか)
- 欠損値や異常値の検出と補完(0で補完するだけでなく、平均値や中央値など)
- 新しい変数(カラム、列、特徴量とも言います)の作成
- 重複データの検出と対応
- クレンジングや表記をあわせる標準化
- SQLジョイン
- マージ(SQLジョインでは不可能な複雑な条件でデータを結合)
- 数値データの変換(対数変換や標準化)
- 次元圧縮
よく見かける現場の状況
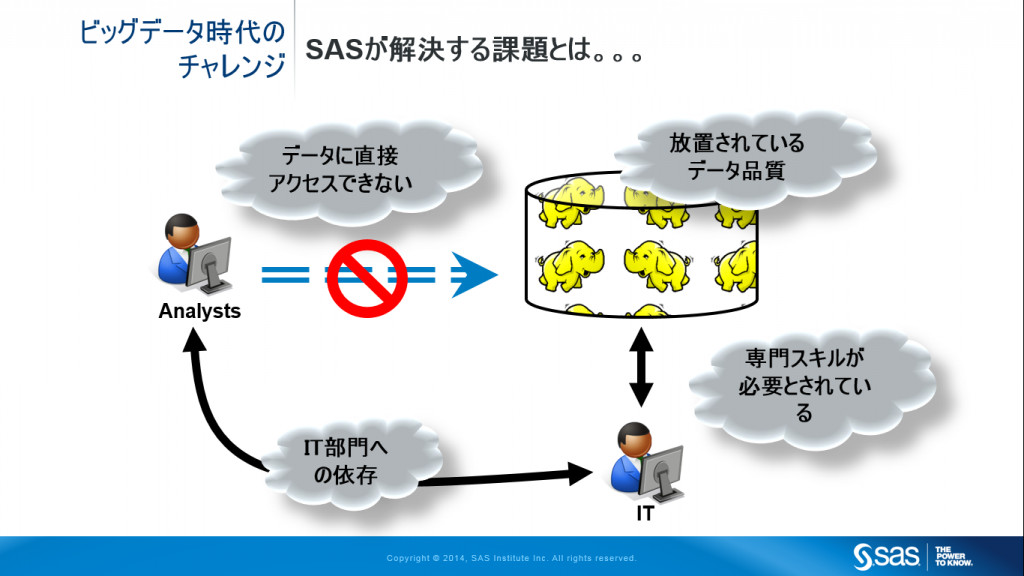
これら2つのアプローチの違いは、従来活用していなかった履歴データや、ビッグデータ、非構造化データと呼ばれるような装置からのログデータやテキストデータを活用しはじめようとする際に顕著になります。業務システムや既にデータウェアハウスに格納されている、主キーやカラム構造がわかりやすいデータとは異なり、このような新しいデータは、行を特定するためのID項目。がなかったり、論理的な1行が複数行にまたがっていたり、欠損値が多い、そもそもどんな値が格納されているべきかを業務ルールから特定できるわけではないなど、必ずしもRDBMSに格納しやすいデータとはいえません。このようなデータを、キー構造や値の制約などを厳格に管理することに重きを置く従来型のRDBMSに格納しようとすると、IT部門は、まずユーザー部門に対しして、「どのような種類のデータをどのように使用するのか」といった目的定義からスタートします。わかりやすくいうと、どのようなSQLを投げるかが決まらないとテーブル構造やリレーションシップなどのデータモデル設計ができないからです。しかし、「アナリティクス」においては、どのようにデータを加工するかは、分析のプロセス中に考えることですし、分析が進むにつれて加工の仕方も変わってくるため、あらかじめ用法を明確に定義しておくことはできません。データを触ってみないと加工の仕方は決まりませんし、将来的に別の活用方法になることもあります。同じデータであっても、データを縦方向に長くする方が良いのか、横方向に長くのが良いかは、そのときどきのデータの見方によって変わります。従来のデータマネージメントのアプローチでは、この瞬間に「卵とニワトリ」の問題が発生し、アナリティクスの取り組みの大幅なスピードダウンを招くことになります。
なぜ従来型のアプローチになるのか?
IT部門がこのような従来型のデータマネージメント・アプローチを取ろうとするのには、理由があります。RDBMSを利用する場合、さらにはHadoopを利用する場合には特に、ビジネスユーザーが生データを加工することはIT技術的・スキル的に困難だと考えており、なんらかの「おぜんだて」をしてユーザーに使いやすいソフトウェア環境とともに「公開」しようとする意識があるためです。実際にそのとおりであり、高度な分析をするためには、さすがにSQL程度は使えるor考え方がわかる必要はありますが、HadoopのMapReduceはハードルが高すぎます。しかし、アナリティクスにおいてSQLは道具として不十分であり、必要なデータ加工をするためにはMapReduceやその他のデータ加工言語を駆使して、場合によっては分散コンピューティングを意識しながら使いこなさないと実現できないデータ加工要件が存在します。この部分のスキルを獲得したり人材を確保するのはコスト高であるだけでなく、ビジネス・スピードを損ないます。
先行してビッグデータアナリティクスで競争優位性を築いている企業・組織はここの事情が少し異なります。彼らにとってアナリティクスの活用はビジネスモデルの根幹であるため、スキル獲得(教育、学習、採用)はコストがかかってもMUSTであると考えています。ただ、それでも、分析組織として拡大・成熟してきたチームの管理者は、昨今のデータ分析人材難もあいまって、自分の抱えるチームの生産性に課題を感じ始めています。
最新のテクノロジーがアプローチ方法の変革を可能にします
実は、このようなIT部門の懸念はすでに過去のものとなっています。テクノロジーは進化しソフトウェアは成長しています。いまや、データサイエンティストのような「分析もITもこなすスーパーマン」ではない「ビジネスユーザー出身の分析者」(ガートナーはこれを市民データサイエンティストと呼んでいます)であっても、Hadoopの技術的なスキルなくとも、グラフィカルなユーザーインターフェースや分析者が通常分析に使用する言語で、Hadoop上のデータを自由自在に加工できる手段が存在します。つまり、ビッグデータ時代においては、データは基本的な欠損値の補完などのクレンジング処理だけを施した生データを置いておくだけで、データ分析者が、高度なITスキルを持たなくともハイパフォーマンスに分析処理を実行することができるのです。

アナリティクス担当者(誤解しないでください。レポーティングしたい分析者とは異なります)が考えていることは、
「データの形式や品質はさておき、とにかくデータにアクセスできるようにして欲しい。加工は自分たちでできるから、とにかくスピード優先で」
となります。このような要望にこたえるためには、従来型のテクノロジーを使用したデータウェアハウスの改修という方法では困難です。様々な形式のデータを、データモデル設計をすることなく、適切なコストで、まずは蓄積するということが必要になり、そこは今の時代においてはHadoopが最適です。また場合によって、既存のシステムとの連携においては、フェデレーション技術のように仮想的に集めたかのように見せる必要があるケースもあります。このような環境では、従来のデータウェアハウスのように整ったデータが準備されているわけではなく、使用する際に整えることになるため、分析者がデータ品質を目的に応じて整える必要があり、Hadoop上でデータプロファイリングやクレンジングを自身で実施します。さらには、あらかじめ直近使用する予定のないデータをも捨てずに蓄積しておくデータレイクという戦略をとる企業・組織も出てきました。
最初のゴールはABT作成である
IT部門が、このアナリティクスにおけるデータ加工の最初のゴールを理解すると、企業・組織におけるアナリティクスの取り組みが飛躍的に加速し、IT部門のビジネスへの貢献の仕方も理にかなったものになり、IT投資の目的や方向性を設定しやすくなります。
アナリティクスが欲しているのは、BIクエリーに適している正規化データモデルやスタースキーマ・データモデルではありませんし、また「目的特化型のデータ・マートが欲しい」というわけでもありません。まず最初の目的は、ABTすなわち、Analytical Base Tableを整えることです。ABTとは、15年以上前からある考え方で、アナリティクスにおいてデータの分布の確認や傾向の探索、予測モデルの作成のための基本テーブルのようなものです。
顧客の購買行動を予測する際を例に考えてみましょう。当時はそのまま「1顧客1レコード」と呼んでいましたが、最近ではSASジャパンでは「横持ちテーブル」ということが普通です。対して、履歴データを縦に持ったものを「縦持ち」と言います。簡単に言うと、顧客に関する全てのデータ、顧客マスターにある属性情報に始まり、契約情報、購買履歴、コミュニケーション履歴、キャンペーンへの反応履歴、店舗やWeb上での行動履歴、など、最近の言葉で言えば、顧客の360度ビューをデータとして表現し、1人の顧客につき1行使用し、これら情報を列方向に持たせたデータです。ご想像の通り、このテーブルは時には列数が数百、数千、数万になったりすることもあります。ただ単に履歴を横に持つから横に長くなるというよりは、顧客を特徴づける説明変数や特徴量を作成していくことでも、その数が増えていきます。単にAという商品を買ったというだけでなく、何曜日の何時にどの店舗に来店したのか、来店頻度は? 金額は? 金額の合計は? など、その顧客がどのような行動、嗜好をもつ顧客なのかを特徴づけるデータを作成します。どのような列、説明変数や特徴量を作成するのが良いかは、今回の趣旨ではないので省略しますが、これまでの業務上の勘と経験、ノウハウ、そして一番重要なのは、企業が顧客とどのような関係を気づきたいかという顧客戦略、これらがあれば、おのずと決まってきます。また、ある程度世の中にベストプラクスもあるので、書籍や弊社コンサルタントに期待することもできます。
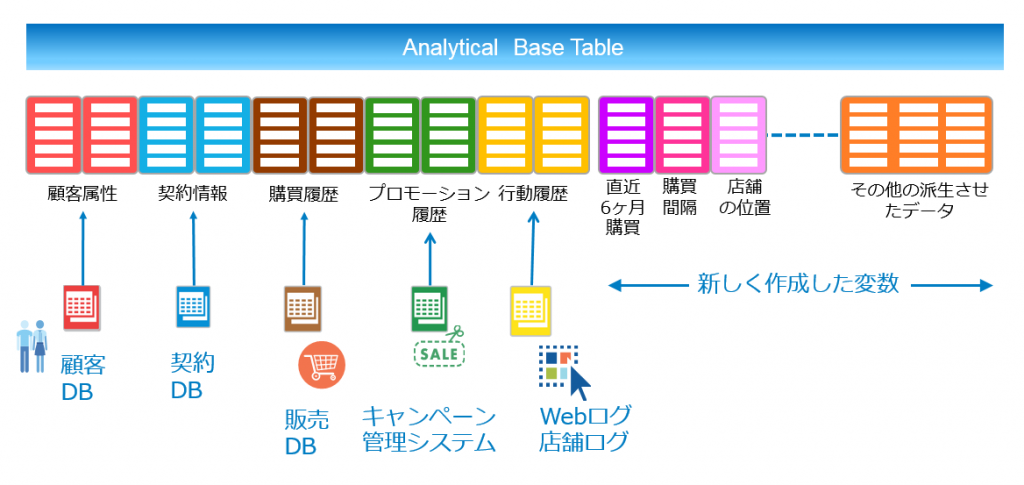
なんだ、全てのデータをくっつけたデータマートを作ってあげればいいのではないかと思うかもしれませんが、ABTを作成する作業は前述の通り分析作業をしながらのIterativeなプロセスのため、分析者自身が作っていく必要があります。アナリティクスの活用成熟度の高い分析チームになると、データの一貫性を理由として、複数のテーマでこのABTの一部の列を共有するようになります。この段階になって初めて、ある程度仕様が固定化されたデータマートのようになりますが、ビジネスの変化に応じて柔軟・迅速に変更していく必要があるという性質は変わりません。
IT部門の新たな役割:データスチュワード
このように、アナリティクスのためのデータマネージメントプロセスを実践するためには、アナリティクスという具体的なビジネス価値を創出するための要求とスピードに対して、迅速に対応する必要があります。その主たる役割は、従来型のシステム開発データベース構築やデータモデルの設計ではなく、「ユーザーの使いたいデータはどこにあるのか?」、「社外データはどのように調達できるかどうか?」、「他部門ではどのようにそのデータを活用しているのか?」といった疑問に答える役割で、一般的には、「データスチュワード」として定義されている役割です。データスチュワードという役割は、約10年前にその必要性が叫ばれたBIをサポートするBICC(ビジネス・インテリジェンス・コンピテンシー・センター)でも定義されていましたが、昨今、アナリティクスの広まりによって、その役割の重要性が再認識され始めています。部門横断的に業務とアナリティクスおよびITに対する一定の理解とスキルを有しつつ、主たる役割はアナリティクスとそれに必要なデータやスキルを効果的・効率的にマッチングすることです。最近では、必要な全てのデータやスキルを組織内で準備することが現実的ではなくなってきており、その解決策の一つである、「オープンイノベーション」の事務局的な役割を担っているケースもあります。
まとめ
データが単なる業務アプリケーションの「付属生成物」という立場から、企業の業績を把握するための「事実」という立場を経て、さらにはアナリティクスによるよりよい意思決定のための「戦略的な資産」へと変貌と遂げるにしたがって、データマネージメントの役割も変わってきています。まだまだ、「IT部門のビジネス業績への貢献」が課題となっている企業・組織が多い中、ビジネス業績に直結する「アナリティクス」に従来と異なるデータマネージメント・アプローチのサポートあるいはデータ・スチュワードといった新しい役割によって貢献できるのは、まさに全社横断的な知見と外部ナレッジに一番近い位置にいる、IT部門が最適ではないでしょうか。
