ビジネスに使える「良い予測結果」を得るために
今回は、8月にリリースされたSAS Forecast Serverの新しい機能を紹介しながら、データが理想どおりに画一的にはなっていない実際のビジネスの現場で「良い予測結果」を得るために必要な3つの要素についてご紹介します。
はじめに
需要予測はもともと、天候などの不確実なばらつきをもつ外的要因という制約のもとで、顧客満足度や販売機会を最大化(欠品による損失の最小化)しつつ、売れ残りや在庫保有といったコストを最小限にするための手段のひとつです。生産から販売までのリードタイムが長い商品の販売量の予測や、一定期間先の需要量の取引を行うエネルギーの売買に携わる企業にとっては、正確な需要予測が不可欠です。今回は、予測結果そのものの精度をビジネス上の課題解決に見合う精度にするために、欠かせない要素ついてご紹介します。
欠かせない三つの工夫
SASは長年、SAS/ETSやSAS Forecast Serverなど、時系列予測機能を提供してきましたが、それらツールを使用して実際に成果を出している企業に共通するのは、これらのツールに用意されている時系列予測アルゴリズムを単に使用するのではなく、精度を高めるためのなんらかの"工夫"をしているということです。それをまとめると以下の3つに集約されます。
- 予測対象の実績データ(以下、時系列データ)のセグメンテーション
- マルチステージ(他段階の)予測モデリング
- 予測結果の追跡
予測のためのアルゴリズムは世の中に多数存在しますが、それを単純に適用するだけでは、ビジネス上の意思決定に利用可能な精度を実現するのは実は困難です。従来は、上記3つの工夫をシステム構築の際に考慮し独自に仕組みを作りこむ必要がありました。SASはこれらをベストプラクティス化し、ツールそのものの機能としてリリースしました。新たにSAS Forecast Serverに備わった、それら3つの機能について簡単にご紹介します。
1.時系列データのセグメンテーション
- どの店舗でいつ何が売れるのかを予測しなければいけない小売業
- 客室の埋まり方を予測しなければならないホテル業
- 顧客満足度を落とさずに欠品率をコントロールするために、どの施設レベルで予測すべきかに頭を悩ませる流通業
- エネルギーの使用量を予測しなければならないデータセンター事業者やエネルギー供給企業
- 乗客数や交通量を予測する航空関連企業
- コールセンターの需要を予測して従業員の配置を計画する通信会社
など、どのような予測業務においても、最初のステップは、自社の時系列データがどのようになっているかを理解することです。
理想的な時系列データ
従来の予測技術にとって最も完璧な(うれしい)時系列データはこのような形(図1)をしています。量が多く、データ期間が長く、安定していて、同じパターンが繰り返され、欠損値がほとんどなくパターンが予測しやすいという特徴があります。
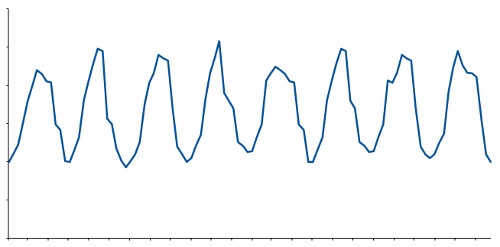
このような理想的な時系列データが仮に存在したとすれば、自動化された予測エンジンと単一の予測モデリング戦略で簡単に良い予測結果が得られます。
実世界の時系列データ
しかし現実世界では、企業が保有する時系列データはもっと多様です(図2)。
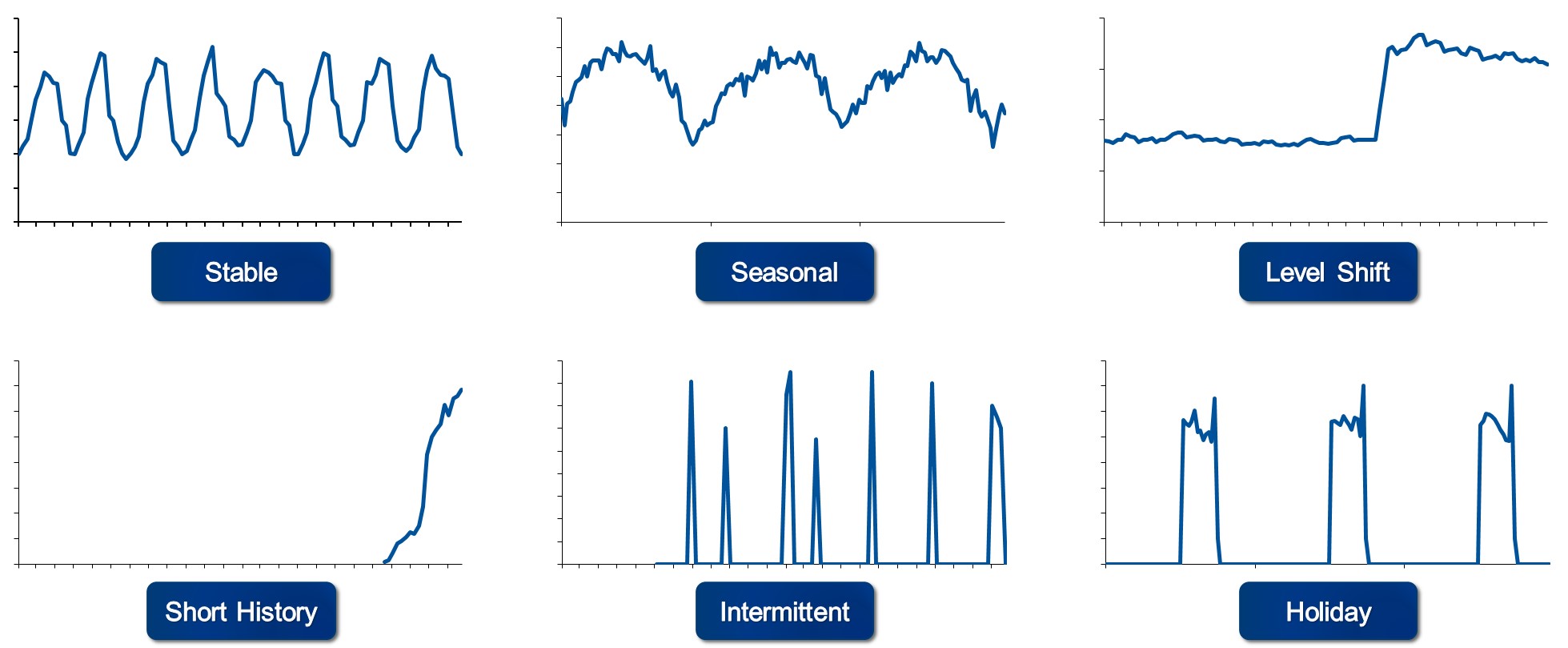
- 洗剤のようにいつでも売れる安定した(Stable)需要
- バーベキューセットのように季節性(Seasonal)のある需要
- あるいはレベルシフト(Level Shift)があるような需要-例えば、市場や販売チャネルを拡大したタイミングなど-
- 新製品の投入や新市場への進出など、データ期間が非常に限定されている(Short History)。
- 自動車の特定の補修部品のようにスパースなデータ(あるいは間歇需要とも言います)(Intemittent)。
- ハロウィングッズのように一年に一回のある週や月しか売れないものもあります(Holiday)。
このようにそれぞれまったく異なる時系列パターンに対して単一の予測モデリング戦略を適用しても良い予測結果は得られません。これらにどのように対処するかが「良い予測結果」を得られるかどうかの分かれ道になります。
時系列データのセグメンテーション
この問いに対する解決策は、時系列データのセグメンテーションです。時系列データのセグメンテーションとは、時系列データのパターンに応じて異なるパターンに分類する方法です。これは、需要予測プロセスにおいて最も重要な最初のステップのひとつです。分類した後にそれぞれのパターンに応じた予測モデリング戦略を適用することが「良い予測結果」を得るための秘訣となります。
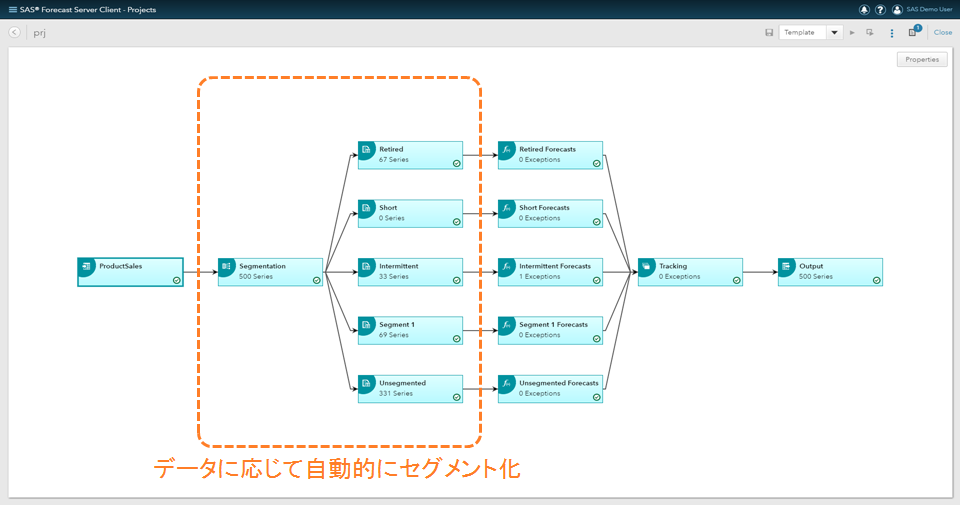
これにより、
- Stableなデータに対しては、ロバストなARIMAモデルを適用し、
- 季節性を示すデータには季節性モデルを、
- Level Shiftタイプにはレベルシフトの要素を説明変数に利用できるARIMAX手法を、
- 新製品パターンには類似性分析のテクニックを用い、
- スパースなデータに対しては間歇需要のための予測モデルを、
- Holidayパターンにはカスタマイズした時間間隔モデルを使用する
など、時系列データのパターンに応じた適切な予測モデリング戦略を適用することが可能となります。
SAS Forecast Serverではこのように時系列データをセグメント化し各セグメントごとに予測戦略を設定できる機能があらかじめ用意されています。
2.マルチステージ予測モデリング
例えば、消費財の業界では店舗SKUレベルの需要(販売実績)は通常スパース(たまにしか売れない)であり、ノイズに対して需要がとても小さく、また価格の効果やプロモーション効果を推定することも困難です。食料品店の一時間ごとのトランザクションや30分単位の電力の需要予測のような頻度の高いデータの場合には、従来型の時系列モデルは適さない場合があります。「良い予測モデル」は常にデータの特徴を的確に捉えビジネスニーズを満たすためにオーダーメイドにする必要があるのです。
階層型予測
階層に基づいたマルチステージモデリング戦略がひとつの解決策になります。これは、3つのステージからなり、予測システムを構築する際の汎用的なフレームワークです。階層とは、例えば、地域->各店舗、商品カテゴリ->各商品といった階層構造をイメージしてください。
非常に簡略化すると:
- 第1ステージでは、ノイズを消去しつつ隠れた特徴をあぶりだすために、データを上位階層で集約します。集約したデータに対して特長抽出テクニックを時系列モデルとともに使用して予測値を生成します。
- 第2ステージでは、特徴抽出テクニックを再度使用して最も下のレベルで個別の予測を行います。
- 第3ステージでは、前の二つのステージで作成した予測値を統合し、トップダウン調整を行ってファイナル予測値を生成します。
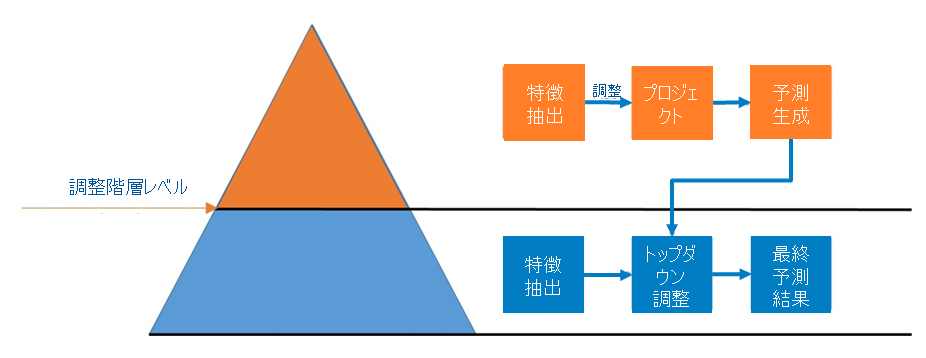
特徴の抽出には移動平均をはじめとするさまざまなテクニックが利用可能ですが、ここでは主に回帰を使用します。
3.予測精度のモニタリング
予測精度の最も良い測定は後になってからしかできません。予測した未来がやってきたときに初めて以前に算出した予測結果と比較したくなります。このプロセスは繰り返し行う予測業務に不可欠なものです。

新しい予測結果で上書きしてしまうのではなく、過去の予測結果をアーカイブしておくことによって、予測精度を継続的にモニタリングし以下のような問いに答えることを可能とします
・予測結果はどのくらい正しかったか?
・将来予測精度が許容範囲にあるのはあとどれくらいの期間か?
・予測精度はずっと安定しているか?
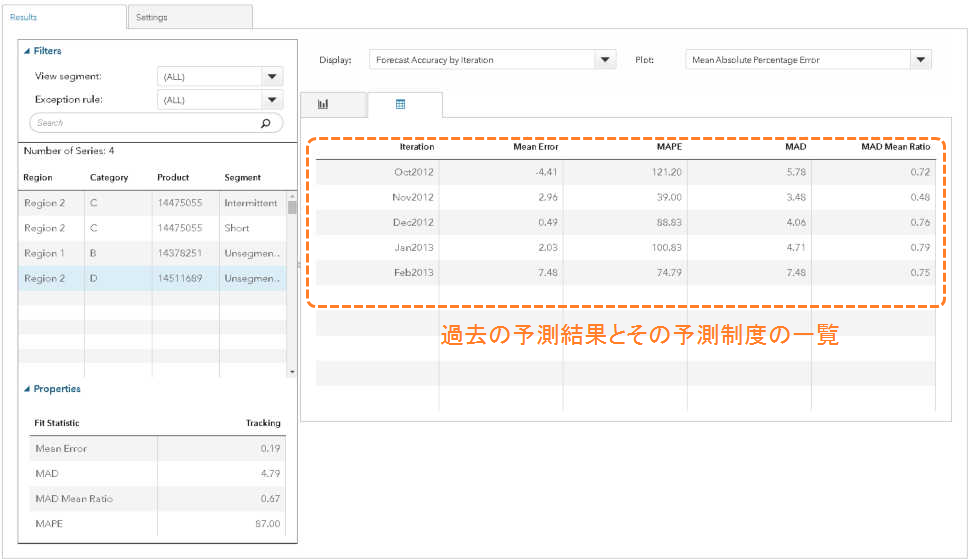
もし商品やSKUの階層型の予測をしている場合には、階層構造全体の予測精度を把握することが可能となります。階層のどのノードの精度が悪くなっているかを把握することで、予測の改善が最も必要な箇所に限られたリソースを集中することができます。
まとめ
従来これら3つの機能は、予測システムや在庫管理システム構築の際に、需要予測アルゴリズムの専門化がプロジェクトに参画し、時系列データを最初に分析し、その結果に基づいてシステムを設計・実装してきた機能です。最新のSAS Forecast Serverではこれらがあらかじめ組み込まれているため、そのような専門家に頼ることなく、ビジネスユーザー自身で「良い予測結果」を手に入れることができるようになったのです。
