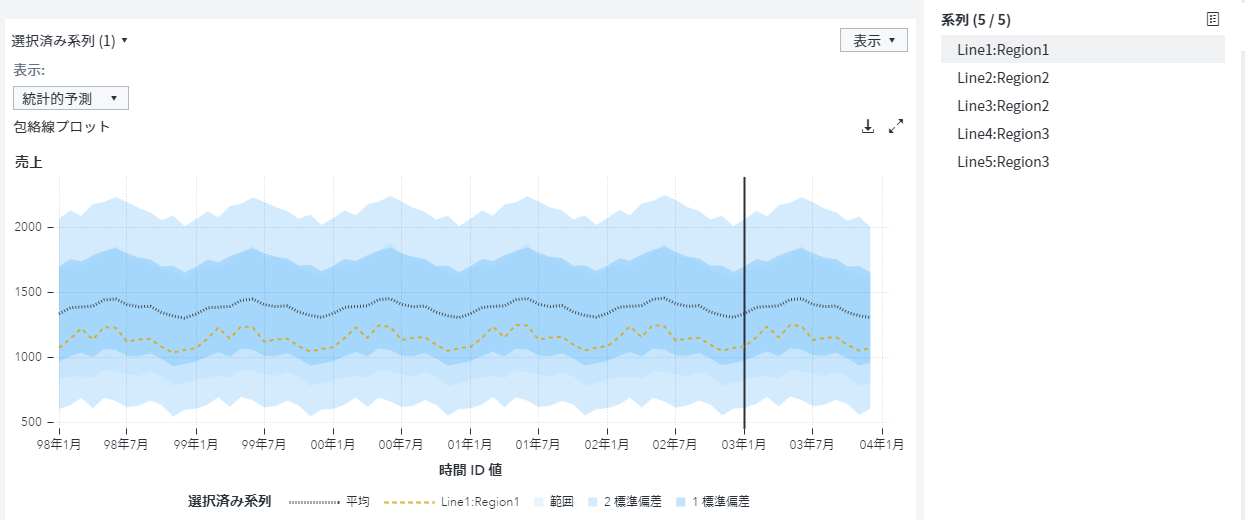
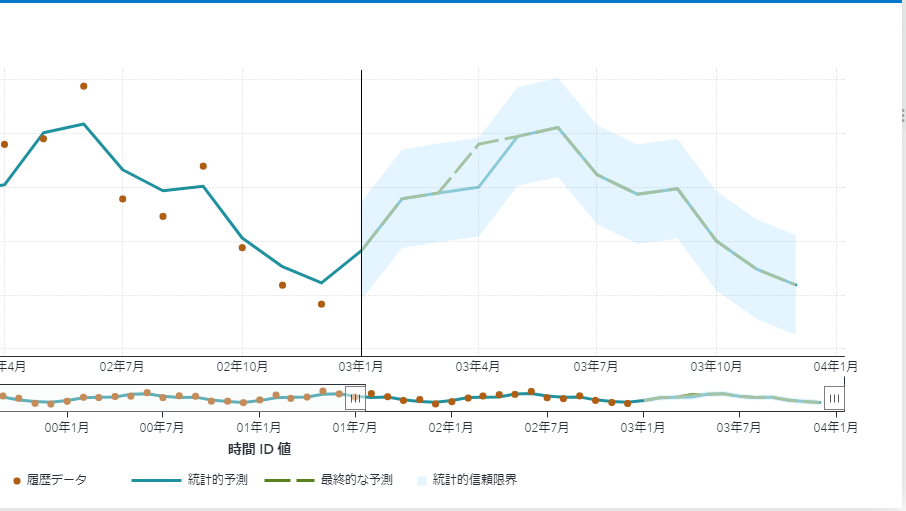
データサイエンスの使いどころ・・・攻めと守りの圧倒的な違い 以前のブログで、データ活用における攻めと守りについてお話しました。今回は小売業を例に多くのデータ活用プロジェクトが陥りやすい罠と、真の目的達成のための方法についてご紹介します。 小売業の目的はもちろん他の業種企業と変わらず、収益の最大化です。昨今データ分析を武器として売り上げの最大化、コストの削減、業務プロセスの生産性向上を目指す企業が増えてきています。時には、データサイエンティストが、データサイエンスを駆使してプロジェクトを実行しているケースもあるでしょう。 ここで、今一度現在取り組んでいる、またはこれから取り組もうとしているデータサイエンスやAI活用のプロジェクトがどんな利益を自社にもたらすのかを改めて考えてみましょう。昨今、需要予測についての相談が非常に多いので、ここでは需要予測について考えてみます。 弊社にご相談いただくケースの中で、少なくない企業が、需要予測をこのブログで言うところの「守りの意思決定」としてとらえています。多くのケースで、過去の実績をベースに将来の需要を予測することで、在庫過多や欠品を減らそうというプロジェクトに投資をしていたり、しようとしています。言い換えると、過去の実績を学習データとして、将来を予測するモデルを構築し、ひとつの将来の需要予測を作成し、それを在庫を加味したうえで、発注につなげています。 手段が目的化することで見失う可能性のある本来の目的とは 非常に典型的なAI活用、データサイエンス活用かと思いますが、実は、「AIで予測」、「機械学習で予測」といった言葉で最新のデータ活用をしているかのような錯覚に陥っているケースが見受けられます。数十年前から行われており、昨今でも同様に行われている、機械学習を用いた典型的な需要予測は、「守り」です。すなわち、どんなに多くの種類のデータを使うかどうかにかかわらず、過去の傾向が未来も続くという前提のもとに予測モデルを作成している場合には、あらかじめ定義した前提・業務プロセスの制約の下で、機会損失を最小化するために予測精度をあげているにすぎません。 つまり、そのような前提での需要予測は、小売業の収益向上という観点では、期待効果が限定的であるということです。では、最終的な収益の最大化を実現するには、何をすべきでしょうか? 収益を向上させるためにはもちろんより多くの商品を売ることにほかなりません。より多くの商品を売るためには当然、顧客の購買心理における購買機会に対して販売を最大化する必要があります。あるいは、顧客の購買心理そのものを潜在的なものから顕在化したものにすることも必要でしょう。つまり、販売機会を最大限に活用するということは、店舗中心ではなく、顧客中心に考えるということです。 小売業における攻めのデータ活用の1つは、品ぞろえの最適化 このように、顧客中心に考えることで初めて最適な品揃えの仮説検証のサイクルが可能となります。過去のデータは、単に過去の企業活動の結果であり、世の中の「真理~ここでは顧客の本当の購買思考」を表しているわけではありません。真理への到達は、仮説検証ベースの実験によってのみ可能になります。わかりやすく言うと皆さんよくご存じのABテストです。このような実験により、品ぞろえを最適化することで、販売機会を最大化することが可能なります。そのプロセスと並行して、オペレーショナルな需要予測を実践していくことが重要となります。 需要予測と品ぞろえ最適化の進化 昨今、AIブーム、データサイエンティストブーム、人手不足や働き方改革といったトレンドの中で、従来データ活用に投資してこなかった小売業においても投資が進んでいます。しかし多くのケースでこれまで述べてきたような守りのデータ活用にとどまっていたり、古くから行われている方法や手法にとどまっているケースが見受けられます。歴史から学ぶことで、無用なPOCや効率の悪い投資を避けることができます。今、自社で行っていることがこの歴史の中でどこに位置しているかを考えてみることで、投資の効率性の向上に是非役立てていただければと思います。 小売業におけるデータ活用のROI最大化にむけたフレームワーク SASでは長年、小売業や消費財メーカのお客様とともにお客様のビジネスの課題解決に取り組んできました。その過程で、小売業・消費財メーカー企業内の個々の業務プロセスを個別最適するのではなく、それら個々の業務プロセスを統合した、エンタープライズな意思決定フレームワークが重要であるとの結論に至っています。AIやデータサイエンスという手段を活用し、データドリブンな意思決定のための投資対効果を最大化するための羅針盤としてご活用いただければと思います。