Sie arbeiten mit Daten. Diese stammen vom Kunden. Vermutlich kann jener später indirekt identifiziert werden mit Ihren Daten. Ab Mai gilt neues Datenschutzrecht: Sie werden nachweisen müssen, welche „Maßnahmen der Technikgestaltung“ konkret getroffen wurden, um das zu verhindern. Knifflig, wobei eigentlich ist ja alles „pseudonymisiert“ oder „anonym“ oder so … Das regelt die IT schon? Nein. Tut sie nicht. In diesem Blog wird detailliert sortiert, was geht und wo Standard-Software etwas beitragen kann.

Der Nachweis „anno dazumal“ war einfach: Der Datenschutzbeauftragte hat das gewiss geregelt und mit den IT-/Compliance-Kollegen irgendwo dokumentiert. Gefühlt schützte das mächtige Bundesdatenschutzgesetz den Verantwortlichen (also auch Sie), wenn man mit den Daten verbunden war. Zu abstrakt? Eine Analogie:
Bei meinem Auto läuft im Mai der TÜV ab. Ich vertraue auf die amtliche StVO, als Taschenbuch im Handschuhfach. Ich sage zum Prüfer vor der Hebebühne: Bisher habe ich das immer so gemacht! Und das Checkheft-gepflegte Auto läuft doch seit Jahren anstandslos. Oh, ach, der neue Mechaniker letztens hat wohl 'was übersehen … Nachweis?! Wie jetzt …
Datenschutz durch Technikgestaltung und datenschutzfreundliche Voreinstellungen (Art. 25 DSGVO)
Zurück zu jenen (Ihren) Daten, die Sie sich aus dem Warenhaus ziehen (DWH), von Kollegen aufgreifen (IDV) oder frisch aus dem See fischen (Data Lake) … essenziell für „Self-Service Big Data Analytics“: Denn „gut verrührt“ kann der Computer damit das Kundenverhalten raten. Der Jurist ist da weniger blumig, nennt es „Profiling“ (DSGVO Abs. 4), das gerne über den initialen Geschäftszweck hinaus reichen kann. Schlimm: Falls der Kunde nicht „vernünftigerweise“ damit rechnen muss, dann kann er königlich jener Verarbeitung widersprechen, sich gar löschen lassen und vorher noch transparenteste Auskunft verlangen (Art. 22 und EWG 71 DSGVO, §37 BDSG-neu).
Was hilft? Früh und verlässlich den Personenbezug loswerden! Also schlicht weniger Datenmerkmale selektieren? Ja. Aber die braucht man für Analysen. Und vorher exakt aufschreiben, wie verarbeitet wird … da grübelt der Data Scientist. Auch selbst datensparsame Fragmente könnten ja rückwärts kombiniert dann doch wieder auf die „Zahnarztgattin 30-40 in Hintertupfingen“ zeigen. Also besser sauber „pseudonymisieren“ oder „anonymisieren“. Was war gleich der Unterschied? In §3 BDSG wird das zwar erklärt … doch jenes „wesentlich erschwerte“ und doch irgendwie Bestimmenkönnen wirkt auf den Datennutzer diffus, klingt aber irgendwie zu risikoreich.
Pragmatisch erklärt: Jedes relevante Datum aussternen oder durch eine Zufallszahl ersetzen, verschlüsseln oder hashen – dann wird der Datensatz idealerweise anonym; aber leider meist unbrauchbar für Auswertungen. Oder schlimmer: völlig falsch im Sinne der Kundensegmentierung, der Modellentwicklung, des Scorings. Dazu später mehr. Hier ein Beispiel „normaler“ Kundendaten:
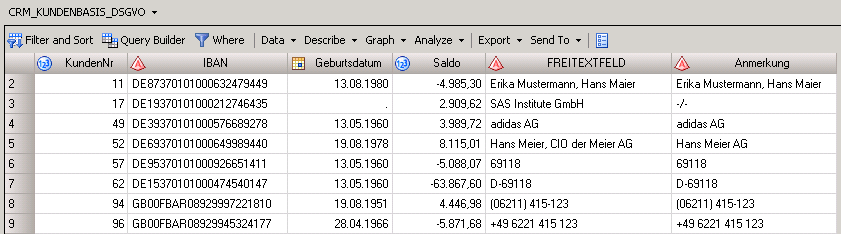
Diese Datei enthält reichlich Personenbezug. Selbst in Freitextfeldern und Anmerkungen könnte er drin stecken – ohne dass eine Verfahrensbeschreibung davon spricht, ein Data Dictionary sie listet. Aber sie lauern da, diese kleinen Merkmale, neugierig oder versehentlich mitselektiert und somit gespeichert. Und das Speichern ist bereits eine DSGVO-relevante Verarbeitung. Hoppla!
Alles anonym: Compliance durch Unbrauchbarmachen?
Also wie nun konkret „unkenntlich machen“, ohne die Merkmale gleich völlig zu tilgen? Nun, beim Maskieren sollte man Standardfunktionen einsetzen, deren Logik qualitätsgesichert, aber nicht vom Anwender (dem Verarbeiter der Daten) einsehbar ist. Das liest sich in SQL so:
CREATE VIEW pdp_de_demo.Team_Alpha.CRM_KUNDENBASIS_DSGVO_VIEW AS SELECT SYSCAT.DM.MASK ( 'ENCRYPT', PUT(A.KundenNr , 8.), 'alg', 'AES', 'key', '12345' ) AS KundenNr_encrypt, SYSCAT.DM.MASK ( 'HASH', A.IBAN , 'alg', 'SHA256', 'key', '12345' ) AS IBAN_hash, SYSCAT.DM.MASK ( 'TRANC',A."IBAN" , 'FROM', '1234567890', 'TO', 'XXXXXXXXXX', 'START', 10 , 'LENGTH', 9 ) AS IBAN_tranc, PUT(SYSCAT.DM.MASK ( 'RANDATE', A.Geburtsdatum, 'VARY', 5, 'UNITS', 'DAY' ), DDMMYYP10.) AS Geburtsdatum, SYSCAT.DM.MASK ( 'RANDOM', A.Saldo, 'VARY', 100 ) AS Saldo, (CASE WHEN ( SYSPROC.DQ.DQUALITY.DQEXTRACT ( A.FREITEXTFELD, 'PDP - Personal Data (Core)', 'Individual','DEDEU' ) ne '') THEN '* * *' ELSE A.FREITEXTFELD END) AS Freitextfeld_ohne_Namen, SYSPROC.DQ.DQUALITY.DQIDENTIFY ( A.ANMERKUNG, 'PDP - Personal Data (Core)', 'DEDEU' ) AS ANMERKUNG_IDENTIFY FROM pdp_de_demo.data.CRM_KUNDENBASIS AS A |
Das Ergebnis sieht schon ganz gut aus:
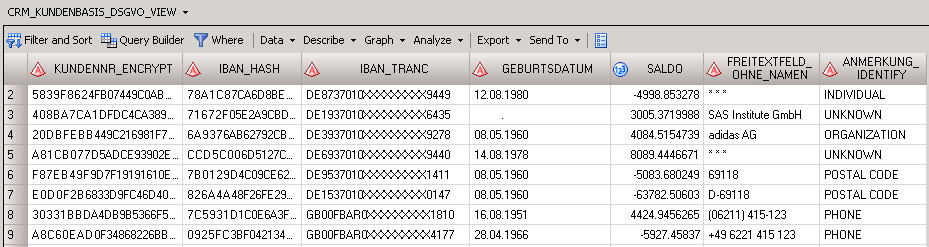
Schnell ergibt sich folgendes methodisches Problem: Wer im Datenfluss durchs Unternehmen tut diesen Schritt und wo speichert er das Ergebnis? Denn je nach Verarbeitung darf der Sachbearbeiter oder Analytiker die Daten ja erst gar nicht sehen, kann sie also nicht anonymisieren. Wenn aber die IT (bspw. die Anwendungsentwicklung) pauschal alle Tabellen des DWH so bearbeitet, dann sind die Daten sicher und sicher für manches zu kaputt!
Wer maskiert – und für wen?
Die Lösung: Jene offiziellen Tabellen bleiben unangetastet (siehe Hinweis am Ende). Der Nutzer greift dann nicht (mehr) physisch direkt auf jene zu, sondern auf dynamische Views (die dann spezifisch Daten lesen). Diese sorgen für die Maskierung, „on-the-fly“ in Echtzeit oder aus dem Cache – ohne die Originaldaten zu zerstören. Im einfachsten Fall (wie oben im Code-Beispiel) werden relevante Feldinhalte „für alle Selektierenden“ verändert. Oder je nach Steuertabelle sekundenschnell „ausgeknipst“, wenn der Besitzer sein „Opt-out“ äußert.
Der SAS Federation Server hostet derartige Sichten, klemmt sich sanft zwischen den IDV-Anwender, Analytiker oder Report-Konsumenten. Angemeldet weiß der Server um den User, seine Gruppen/ Rollen/ Rechte. Dies kann im Design der Views elegant ausgenutzt werden: Dieselbe Sicht liefert dem „Team-mit-VIP-Flag“ auch den Saldo, dem Fraud-Team sogar alles … und der Rest sieht bei Kritischem nur harmlose Sternchen. Auf derselben Physik. Über eine zentrale Anlaufstelle.
Drunter neu, drüber bewährt: geregelter Schutz zum Ein- und Ausschalten
Der Zugriff auf solch zentral administrierte Views passiert per ODBC/ JDBC/ API. Oder für den SAS Nutzer in bewährter Weise durch sein Libname-Statement. Dort steht dann statt „ORACLE“ nun „FEDSVR“ drin … alles andere fühlt sich an wie bisher: Seine Tabellen (die teils keine sind) sind da und der Code kann loslaufen. Das kann im Metadaten-Kontext natürlich auch „pre-assigned“ werden.
LIBNAME mydwh FEDSVR DSN=dwh1 SERVER="demo.sas.com" PORT=24141 SCHEMA=Team_Alpha; |
Doppelter Zusatznutzen: Die IT kann im Hintergrund entspannt-entkoppelt die Physik umbauen (DBMS-Portierungen, DDL-Anpassungen, Umswitchen etc.), ohne dass die mächtigen Fachbereiche gleich klagend zum Telefon greifen. Plus: Jeder Zugriff kann inhaltlich geloggt werden. Der SAS Federation Server wird (optional) die Queries mitschreiben, egal mit welchem geheimnisvollen Makro-Data-Step das Lesen geschah – das wird aufbereitet und notiert. Das kann der Nutzer nicht verhindern, indem er sein SAS-Log löscht. Solch Tun sollte nicht als Überwachung missverstanden werden. Vielmehr fordert die DSGVO den Nachweis des „Wer-wie-wo-wann“ … speziell bei Datenlecks innerhalb von nur 72 Stunden. Gern genommen auch bei Steuer-CDs nach Feierabend oder anderem Internal Fraud. Und ähnlich wie beim „Löschkonzept“ ist schon viel erreicht mit der Fähigkeit, nachweisen zu können: Ja, so ginge es – sollen wir es scharf schalten?
Zusammenfassung des ersten Teils
Die Datenschutzgrundverordnung fordert Sie und Ihr Unternehmen auf, solche „erforderlichen technischen und organisatorischen Maßnahmen“ zu ergreifen und „die zum Zeitpunkt der Verarbeitung verfügbare Technologie und technologischen Entwicklungen zu berücksichtigen“ (siehe Zitate im Anhang). Dieser Blog bot einige Anregungen für Ihre Diskussionen im Kreis der Kollegen. Und mehr noch: Die Software ist bereits verfügbar – das müssen Sie nicht alles selbst austüfteln … sondern jene kostbare Zeit sparen für die dahinter liegende Dokumentation Ihrer Compliance.
Im zweiten Teil beschäftigen wir uns mit Beta-Funktionen (dem Königsweg der Pseudonymisierung), durchgerutschten Personendaten und zufälligen Geburten …
Anhang: Gesetzestexte
Profiling DSGVO Art. (4) Abs. 4:
„Profiling“ jede Art der automatisierten Verarbeitung personenbezogener Daten, die darin besteht, dass diese personenbezogenen Daten verwendet werden, um bestimmte persönliche Aspekte, die sich auf eine natürliche Person beziehen, zu bewerten, insbesondere um Aspekte bezüglich Arbeitsleistung, wirtschaftliche Lage, Gesundheit, persönliche Vorlieben, Interessen, Zuverlässigkeit, Verhalten, Aufenthaltsort oder Ortswechsel dieser natürlichen Person zu analysieren oder vorherzusagen;
§3 BDSG (geltendes Recht) erklärt den Unterschied so:
(6) Anonymisieren ist das Verändern personenbezogener Daten derart, dass die Einzelangaben über persönliche oder sachliche Verhältnisse nicht mehr oder nur mit einem unverhältnismäßig großen Aufwand an Zeit, Kosten und Arbeitskraft einer bestimmten oder bestimmbaren natürlichen Person zugeordnet werden können.
(6a) Pseudonymisieren ist das Ersetzen des Namens und anderer Identifikationsmerkmale durch ein Kennzeichen zu dem Zweck, die Bestimmung des Betroffenen auszuschließen oder wesentlich zu erschweren.
Die DSGVO ist konkreter (EWG 26):
Bei der Feststellung, ob Mittel nach allgemeinem Ermessen wahrscheinlich zur Identifizierung der natürlichen Person genutzt werden, sollten alle objektiven Faktoren, wie die Kosten der Identifizierung und der dafür erforderliche Zeitaufwand, herangezogen werden, wobei die zum Zeitpunkt der Verarbeitung verfügbare Technologie und technologischen Entwicklungen zu berücksichtigen sind. Die Grundsätze des Datenschutzes sollten daher nicht für anonyme Informationen gelten, d.h. für (…) personenbezogene Daten, die in einer Weise anonymisiert worden sind, dass die betroffene Person nicht oder nicht mehr identifiziert werden kann.
§71 BDSG (neue Version), Abs. 1:
(1) Der Verantwortliche (…) hat hierbei den Stand der Technik (…) zu berücksichtigen. Insbesondere sind die Verarbeitung personenbezogener Daten und die Auswahl und Gestaltung von Datenverarbeitungssystemen an dem Ziel auszurichten, so wenig personenbezogene Daten wie möglich zu verarbeiten. Personenbezogene Daten sind zum frühestmöglichen Zeitpunkt zu anonymisieren oder zu pseudonymisieren, soweit dies nach dem Verarbeitungszweck möglich ist.
DSGVO EWG 29:
Um Anreize für die Anwendung der Pseudonymisierung bei der Verarbeitung personenbezogener Daten zu schaffen, sollten Pseudonymisierungsmaßnahmen, die jedoch eine allgemeine Analyse zulassen, bei demselben Verantwortlichen möglich sein, wenn dieser die erforderlichen technischen und organisatorischen Maßnahmen getroffen hat, um – für die jeweilige Verarbeitung – die Umsetzung dieser Verordnung zu gewährleisten, wobei sicherzustellen ist, dass zusätzliche Informationen, mit denen die personenbezogenen Daten einer speziellen betroffenen Person zugeordnet werden können, gesondert aufbewahrt werden. Der für die Verarbeitung der personenbezogenen Daten Verantwortliche, sollte die befugten Personen bei diesem Verantwortlichen angeben.
Abschließender Hinweis: Um im DWH (und zahllosen Quellsystemen) das separate „Recht auf Löschung“ gemäß Art. 17 DSGVO umzusetzen, sind gesondert Maßnahmen zu treffen. Dies ist oben aber nicht gemeint – denn gelöschte Sätze sind „weg“, können also nicht mehr via Profiling verarbeitet oder pseudonymisiert werden. Hinweis: Falls sie aber nicht sofort auch aus dem dispositiven Datenbestand verschwinden (dürfen), könnten Ansätze wie die beschriebenen durchaus eine Übergangslösung bieten …

