Big-Data-Definitionen und -Herleitungen à la drei, vier oder noch mehr „V”s gibt es zur Genüge, alle wohldurchdacht und stimmig. Ihnen allen gemein ist aber die generelle Einordnung des Themas als Zukunftsinitiative. Übertrieben gesagt: weg vom Rechenschieber hin zur künstlichen Intelligenz, die alles perfekt entscheidet und aus dem Nichts heraus neue profitable Geschäftsprozesse und -modelle erfindet.
Hier stellt sich mir die Frage: Ist wirklich alles so hip und neu, wie es den Anschein hat?
Bei der Suche nach einer Antwort auf diese Frage habe ich eine Technologie unter die Lupe genommen, die im Zusammenhang mit Big Data sehr häufig als Mittel der Wahl gilt: In-Memory.
Zum ersten Mal aufgetaucht ist das Schlagwort „In-Memory“ bei einem Projekt der Firma Exxon. Im Zuge der Evaluierung der eingesetzten Supply-Chain-Management-Lösung kam man zu der Ansicht, dass die Mainframe-basierte Applikation im Betrieb zu teuer wäre und auf kostengünstigere Hardware ausgelagert werden solle. Da man aber keine Performance-Einbußen in Kauf nehmen wollte, setzte man auf eine reine In-Memory-Architektur auf Commodity-Hardware (!). Zudem wollte man bei den Anwendern mit mehr Benutzerfreundlichkeit punkten. Die Analogie zu vielen aktuellen Hadoop Big Data Business Cases ist bemerkenswert, doch damals war die Apache Software Foundation noch nicht einmal gegründet! Das Projekt bei Exxon führte nämlich zum Release eines Produktes namens „TM/1“ durch die Sinper Corporation im Jahre 1984.
Es handelte sich dabei um eine der ersten multidimensionalen Datenbanken, die vollständig auf In-Memory setzte, entwickelt auf einem PC mit nicht weniger als 256 KB RAM, um auch „large amounts of data“ flexibel analysieren zu können. Bei Google Search (noch so eine Big-Data-Lösung) findet man sogar heute noch die originalen Presseaussendungen:
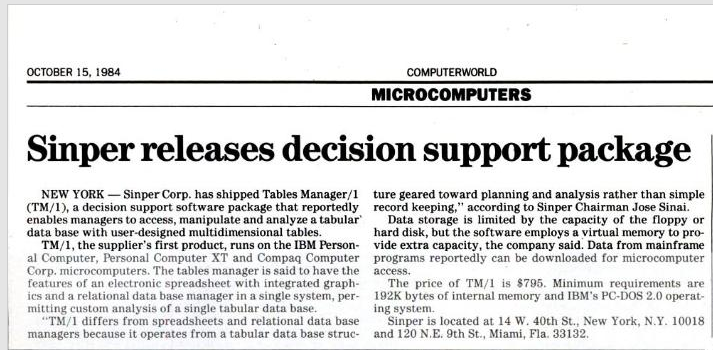
Und unter uns gesagt: Einige Passagen daraus könnte man problemlos auch heute noch verwenden.
In-Memory gibt es also mittlerweile seit mehr als 30 Jahren; selbst die Anwendungsfälle von damals unterscheiden sich kaum von aktuellen Problemstellungen. Und dabei war „In-Memory“ noch im Jahr 2014 beim Gartner-Hype-Cycle vertreten.
(vergleiche “Big Data ist tot, es lebe Big Data“)
Gar nicht schlecht für eine Technologie, wenn sie über 30 Jahre als „Hype“ bezeichnet werden kann, oder? Aber gut – deshalb heißt sie ja vermutlich auch In-Memory – und nicht In-Oblivion.
Was hat eigentlich die Firma SAS zum selben Zeitpunkt getrieben?
Nun ja, von einem kleinen Start-up wie bei der mittlerweile wieder verschwundenen Sinper Corp. kann man da nicht wirklich sprechen; SAS hatte damals nämlich schon Niederlassungen auf vier Kontinenten, 1.500 Mitarbeiter weltweit und längst die Vorreiterrolle in Sachen Analytics inne. Der Begriff „Big Data“ existierte in dieser Form zwar noch nicht, doch die Philosophie, durch Analytik mehr aus den Unternehmensdaten zu machen und so Sachverhalte rechtzeitig antizipieren zu können, war schon damals oberste Prämisse. Und sie fand regen Anklang am Markt, was auch das Inc. Magazine bemerkte:
„SAS is one of the fastest-growing companies in America for five consecutive years.“
Und SAS wandte sich damals – Stichwort „Commodity-Hardware“ – von der bis dahin vorherrschenden IBM-Ausrichtung ab:


Das Ganze natürlich nicht nur mit vergleichsweise simplen multidimensionalen Aggregationen wie im Falle des Exxon-Projektes, sondern mit komplexen analytischen Methoden, der Kernkompetenz von SAS. CEO war damals wie heute übrigens ein gewisser Dr. Jim Goodnight, der sich optisch im Grunde kaum verändert hat.

Der Markt hat es also längst nicht zum ersten Mal mit Schlagworten wie „Commodity-Hardware“, „In-Memory“ und Ähnlichem zu tun. Umso positiver stehe ich den aktuellen Herausforderungen im Bereich der Datenanalyse gegenüber, die vor allem auch das „Internet der Dinge“ mit sich bringt. Denn die Technologien und Methoden sind eindeutig bereit dafür.
Und wo stehen nun Big Data, Analytics und Hadoop heute bei SAS? Das lässt sich hier nachlesen.
