In the world of IT, very few new technologies emerge that are not built on what came before, combined with a new, emerging need or idea. The history of Hadoop is no exception.
To understand how Hadoop came to be, we therefore need to understand what went before Hadoop that led to its creation. To understand why Hadoop stagnated for a few years we need to understand how it was initially used. To understand why Hadoop is now accelerating in its adoption, we need to look at what is happening now and where we are headed.
Looking back at the phases of evolution that led to the emergence and incubation of Hadoop along with the current and future path of the technology can help us understand why it has gained in importance and where the hype is coming from.
Phases of connectivity
There is no doubt that the broader IT segment is moving through different phases of connectivity (and with that we are seeing growing data volumes generated). I believe that this evolution in connectivity led to the initial birth and incubation of Hadoop and that the next phases of connectivity will continue to influence the adoption of Hadoop. Below is a very simple graphic and some explanations that outlines the phases I think we are moving through and the places where Hadoop has been influenced.
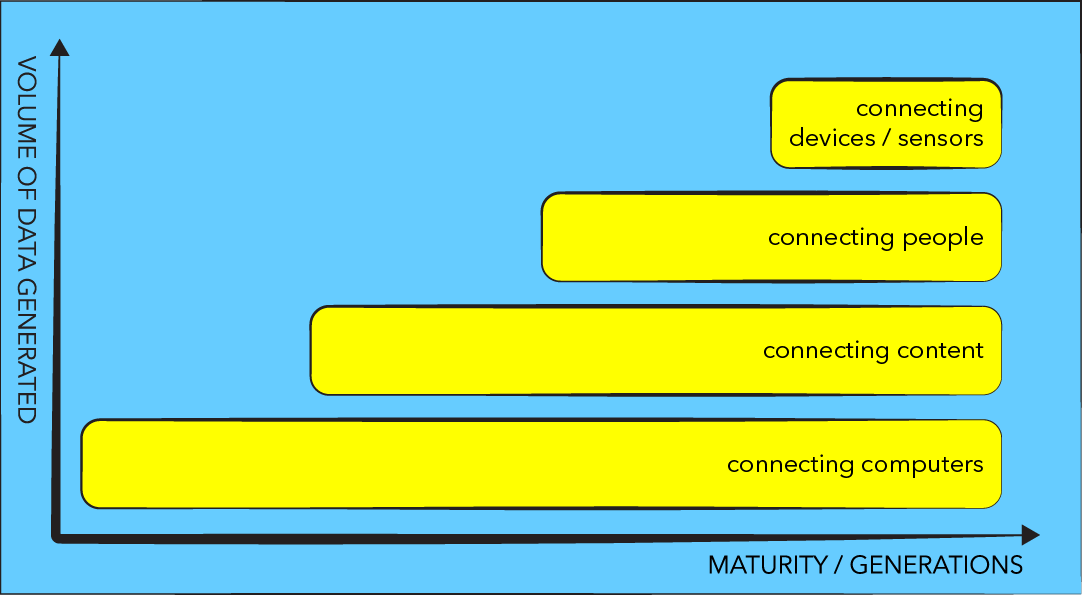
Phase 1 – connecting computers
If we go back in time to the 1980’s, we start out with connecting computers. You could argue that an earlier phase was spent creating computers, but that phase is less relevant to the topic at hand. For our purposes, many computers already existed, and there was a period of connecting computers to computers. At the start just, a few but soon millions were connected, although they were mostly connected in military, academic or commercial settings. Many standards emerged during this phase which we will not go into here.
Phase 2 – connecting pages and content
After connecting computers came the time of connecting pages, the worldwide web, which hit big in the 1990’s. To connect pages, we needed connected computers. So again the previous era helped define and enable the new one.
During this era, we saw the creation of standards for markup, for web servers and many other things such as the HTTP protocol. You can sort of think of this as the era of connecting content and also connecting the consumers of the content to the suppliers of the content. Despite the growing use and connection of content, the number of PCs was not that high throughout this time, and by 1999 there were only about 248 million users of the World Wide Web.
At this time, barriers to the flow of information were removed, allowing information to flow more freely around the connected world. At the end of 1999 it was estimated that there were 3,177,453 unique web sites on the World Wide Web.
In the middle of this phase many of the big Internet companies that we see today were founded, such as Amazon (founded in 1994), Yahoo (founded in 1994), eBay (founded in 1995) and Google (founded in 1996). Each set out to leverage this great new technology to disrupt existing business models or to make it easier for people to find things on what was now a massive web of connected content.
The audience consuming was still relatively small, though. Remember we had no smart phones in this phase. User experience was designed for the masses at least at the outset! With all web the logs, and ensuing cookies etc, organizations using the web quickly started to gather new data about what people were doing and experimenting with customizing things for a better overall experience and better revenues.
Phase 3 – connecting people
Then something dramatic happened. Between 1999 and the year 2000 the number of unique web sites jumped to over 17 million and since then it has been growing greatly to the point that at the end of 2010 there were 206 Million web sites. At the same time the number of connected computers grew tremendously with reports putting the numbers of PCs in circulation at around 1 Billion in 2008. Essentially, we had a perfect storm of PCs moving into the home, followed by the arrival of personal mobile devices such as the iPhone that was launched in 2007, which in turn brought many more people to the Web and created massive commercial opportunities.
As the number of web pages jumped, Doug Cutting and Mike Cafarella, who were at Yahoo, worked on things like Nutch, which was basically an attempt to build an open source web search engine that could discover all the connected pages on the World Wide Web, index them and make them searchable based on Lucene, which Doug Cutting had previously created (an open source indexing and search capability).
Nutch was designed to be distributed across many machines because no one machine could possibly retrieve all the web content and index it, and no one machine could search the indexes to deliver quick results. In 2005, while at Yahoo, Cutting working with Cafarella, took Nutch and combined it with some capabilities that had been developed by Google as they also struggled with the task of reliably storing large quantities of data and then retrieving it quickly, and Hadoop was born. The search engine came alive over the next few years.
As a result, companies collecting a great deal of data over the web started to build out more and more personalization, better and better targeting and cross selling and much more. The idea of using analytics on large volumes of data was seriously born in this phase. You could argue this is still the phase we are moving through today in the mainstream with more and more companies now collecting a lot of data and searching for new innovative services or customer approaches.
Phase 4 – connecting devices
At the moment, there is a new wave building, which involves the connecting of anything that you can attach an IP address to, including t-shirts, watches, fridges, toasters, traffic lights, buildings and cars. Connected devices will drive a new digital wave of information that is often called the Internet of Things (IoT). No doubt, this is going to be a big part of this next era of connectivity, especially when connectivity to the Internet will one day be ubiquitous.
At the same time, we have mobile devices giving consumers more connectivity to each other, and to the organizations they interact with, resulting in the delivery of more and more detailed digital information at a rate previously not contemplated. All this new data is driving up costs of storage and processing for organizations receiving that data and curtailing how effective they can be at delivering services while consuming increasingly large amounts of their IT budgets.
When you combine increasing mobile utilization of the Internet with Web services and the Internet of Things, you get a tidal wave of data and a mega processing headache! Hadoop offers a cost effective answer to these challenges, especially as it matures.
Within the enterprise microcosm
These four phases of evolution can be seen within any enterprise. For some, the efforts to harness data from connected devices are advancing fast as well (all organizations will need to eventually do something with IoT data). There are many new companies in this space creating new services that exploit new data. Incumbents are moving fast to ensure they are meeting consumer needs and even, in some cases, reinventing themselves.
Even if you disagree with the phases I’ve outlined above, there is a large body of evidence to suggest that a rapidly maturing Hadoop is becoming mainstream. Organizations are looking to adopt Hadoop, causing a massive disruptive effect on the incumbent technologies of today and yesterday.
SAS has kept up with this movement, and we have delivered, and will continue to deliver, the world’s broadest suite of Hadoop capabilities that should appeal to Hadoop users of all types from developers who like to code to a manager who just wants to visualize the data held in Hadoop and many steps in between.
These new technologies, and the solutions that are rapidly being created, are helping make the adoption and use of Hadoop a viable option for any organization willing to take a look. This means anyone can benefit from compelling cost savings and establish an architecture with long term viability (infinite linear scaling) while setting themselves up as an organization to operate in an agile way moving forwards, as IoT becomes a firm reality. I contend Hadoop is going to change the IT landscape forever as it disrupts existing business models and matures. We are only at the start of this journey!
In the next installments of this series, we will look at how Hadoop broke free of Silicon Valley, talk about some common early use cases for Hadoop alongside traditional IT architectures, take up the debate around the emerging topic of data lakes, and finally talk about the Big Data Lab.
Meanwhile, read how the independent industry analyst TDWI defines the considerations for utilizing big data analytics with Hadoop.
