Data federation is a relatively new term used to describe a form of data virtualization.
Data virtualization, however, is not new. It has been around since at least the 1960's when virtual memory was introduced to simulate additional memory beyond what was physically available on a machine. While data federation is a form of data virtualization, this does NOT mean that all forms of data virtualization imply data federation.
Confused yet? How about this type of logic, which borrows an analogy from a colleague, Lisa Dodson: a square is a type of rectangle, but a rectangle is not always a square. Get it? Square=data federation, rectangle=data virtualization.
Let me attempt to simplify the definitions of these two terms. Data virtualization makes data appear available in an easy-to-get-to and understand form while hiding the technical details like where it is physically stored. For example, a database view is an easy example of data virtualization, but it is not data federation. The technical definition of data federation sounds like this: a technology that aggregates data from a set of heterogeneous data sources making it available to end users as if all the data comes from a single source. Or, to simplify: data federation pulls data from many different sources and makes it easily available to end users from one location.
Now for some before and after pictures.
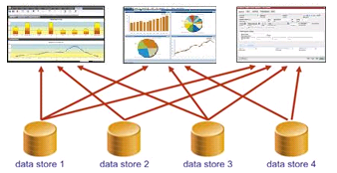

Anyone who has used SAS for awhile may be having déjà vu, because a SAS view which has been available for decades provided this type of data federation capabilities.
What's different now is big data, and the concept of a Logical Data Warehouse (LDW). The large volumes of data are often sourced from not only an enterprise data warehouse (EDW), but other sources referred to as data lakes or data pools, typically a big data storage platform like Hadoop or SAP HANA. The volume of data now in particular can cause performance issues (meaning the data takes too long to be used in a timely manner) when using older forms of data virtualization. SAS views still exist and work today, however anyone with big data volumes will require a better performance solution, and that is why SAS offers the SAS Federation Server.
In very simple terms, SAS Federation Server is an on-demand data server version of a SAS view, or you may want to consider it a SAS view on steroids. Don't get me wrong, there is a lot of technical magic behind the scenes that makes data federation work. But the beauty of good technology is that the back end hides the complexity while the front end is simple and "just works."
In its latest upgrade, SAS Federation Server integrates more data sources than ever, working with Hadoop, SAP HANA and other big data sources. For additional information on the benefits of data federation please see my colleague, Matt Magne's, prior blog post about data federation.
