Data governance and data virtualization can become powerful allies. The word governance is not be understood here as a law but more as a support and vision for business analytics application. Our governance processes must become agile the same way our business is transforming. Data virtualization, being a very versatile tool, can give a fast track to gaining that flexibility.
Having discussed the way that data virtualization can support management of data sources, let's dig in to another implementation scenario.
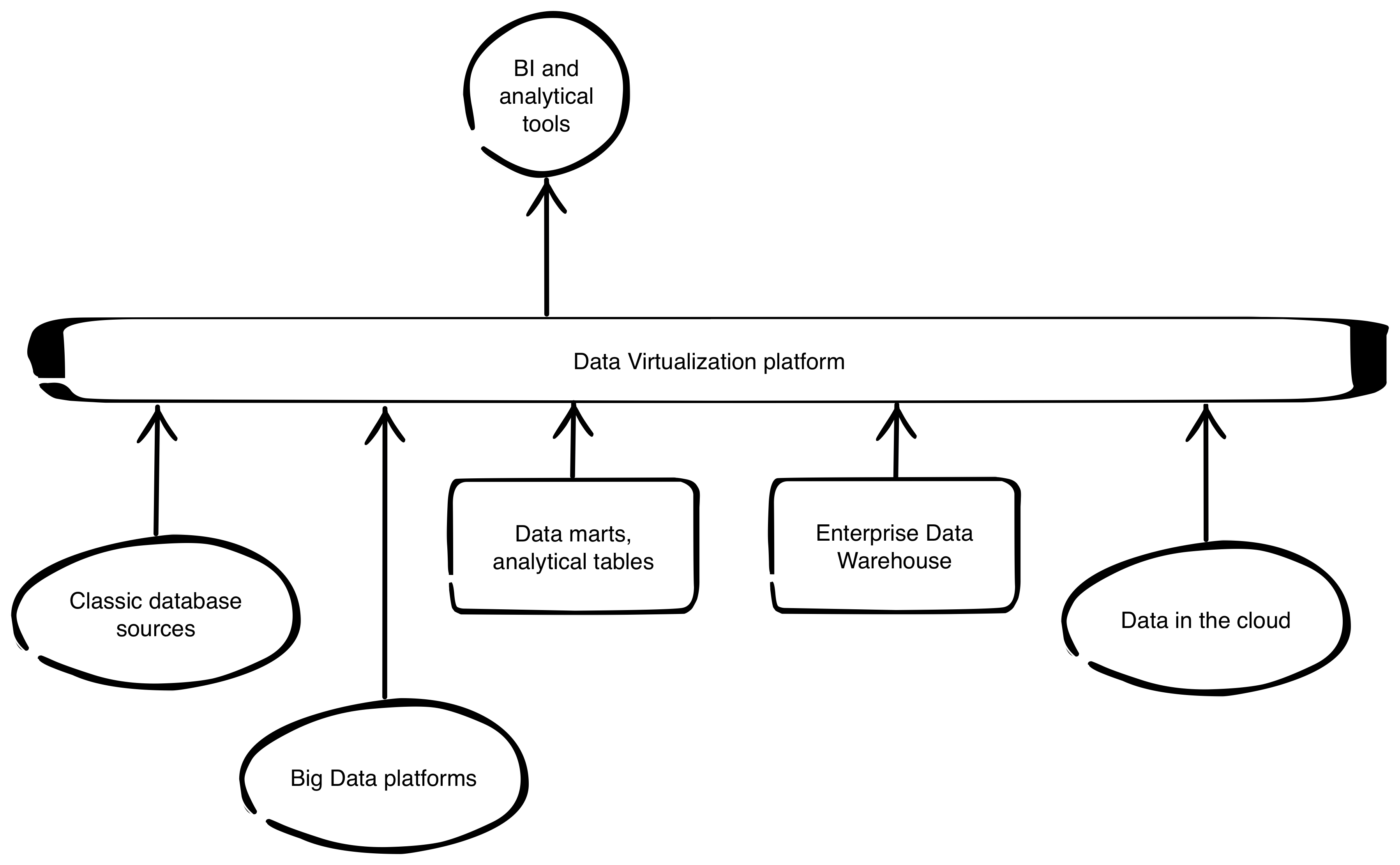
Scenario 2 - Guarding the consumers
When we got all of our source data in control, why don’t we put the reporting ready data in the same place? We can get a lot of control on how data is being used.
The very same platform, that was watching and supporting data preparation stage, can now gain view on data warehouse output data and be a single point of connection for all of business intelligence applications and self-service environments.
Positive side of „high control”
When we talk about control, that doesn't require us to look at every step of our users, nor does it mean becoming a type of Data Governance Big Brother. The idea is to gain as much knowledge about data usage as possible. With that in mind we can address primary goals of our data governance practice — provide the organization with proper alignment between business strategy and analytics. When we know who is using which data, and possibly know how and what for that data is being used, then we gain ability to adjust business intelligence programs to meet user needs.
Data virtualization delivers us all tools we need to achieve that goal by logging and auditing every single data manipulation and usage. For example, say we have a successfully implemented self-service business intelligence project for our organization. Users are eagerly using provided BI tool and building their own analysis. We can expect that data delivery platform will soon become heavily charged. Also the BI server will lack capacity. So, that leaves two options:
- Provide more power, which is costly and kind a brute force solution
- Build data marts and standard reports on what users have developed
 Second option sounds like the best one and here is why.
Second option sounds like the best one and here is why.
Daily struggle
It is not obvious to see, but heavy users are constantly struggling with the same transformations and measure calculations — why don’t we deliver that for them?
We can support them by:
- Building brand new data marts and delivering rebuild analytical tables, but that usually involves development, project and financing. It also ends up with another analytical solution, that has to be managed, maintained and supported by Data Governance processes
- Configuring such transformations and calculations with ease on the data virtualization platform
Given the second option we have new opportunities — users can manage to build those data marts and views by themselves, extending the idea of self-service business intelligence in the organization.
All that we build on data virtualization platform will be easy to maintain, cheap and fast in delivery. It is a perfect sandbox for testing new ideas. It is a common phenomenon that once the business user is presented with a report based on real data, the next thing he wishes for is a change to it.
Addressing the success
If there are reports or analysis, that are run on daily basis, that means, that they have become mission critical. That is a perfect news — our self-service initiative is a success! But on the other hand, shouldn't we take a proper care of those mission critical reports? We need to move them to more standardized environment (possibly an enterprise data warehouse) to give a higher SLA for that data and its delivery.
Download a paper – The SAS Data Governance Framework





