Data governance and data virtualization can become powerful allies. The word governance is not be understood here as a law but more as a support and vision for business analytics application. Our governance processes must become agile the same way our business is transforming. Data virtualization, being a very versatile tool, can give a fast track to gaining that flexibility.
 Data virtualization is a pretty simple and flexible tool. All you get is a platform, that connects to data sources and make all of data found in them available further. Of course that’s not all – you get security, caching and auditing.
Data virtualization is a pretty simple and flexible tool. All you get is a platform, that connects to data sources and make all of data found in them available further. Of course that’s not all – you get security, caching and auditing.
One can say that this kind of functionality is common, and every ETL or data access engine can do the same. It is not true. Let's discuss two of the many possible implementation patterns for data virtualization. The first style sits on data warehouses and other areas of raw data as a guard for data consumers. The second is on the source data side and supports data unloading and preparation. Each has advantages, which can put your data governance activities on steroids.
Scenario 1: Guarding the data sources
Placing data virtualization platform right in front of data sources gives certain advantages. It links to why we were building the staging areas for each of the data warehouses in the first place. We do this to:
- Secure source data from analytics impact, which can devastate the performance.
- Gain more intelligence on the "source" side, like the ability to identify increments in the source data.
- Find ways to build cross-database queries and transformations when loading data marts and warehouses, that would run faster than being implemented only with ETL.
- Gain more speed, as data sources are usually tuned to perform well with single transactions, it's important to have restrictive isolation levels that do not allow us to delete indexes prior to data load/unload.
Having a well designed staging area simplifies and accelerates data warehouse implementation. Sometimes it is also used, as a direct data source for all of our self-service and sandboxing activities.
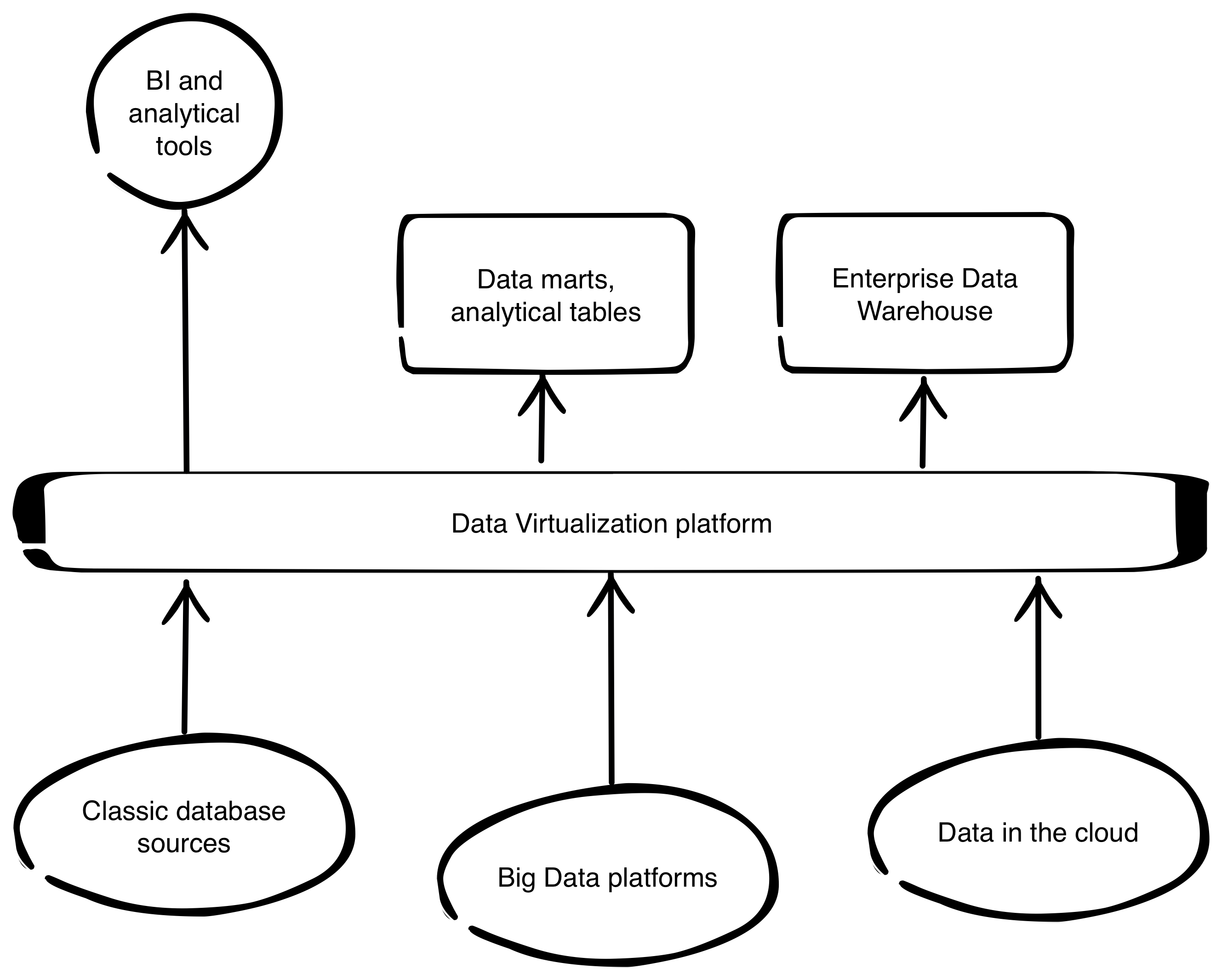
Data virtualization can give us all of that – but without latency and complication of building ETLs to load data into the staging environment. You just define new data source, connect to it and current data is available for further use. It is important to point out that not all of queries run directly on the source. Virtualization is also connected with caching ability to streamline data access. On the platform itself you can define views and queries, that are visible to consumers as new tables, previously not present at the source. They can be cached and refreshed on cycles - just like data in a classical staging area.
From the data governance perspective having transaction and operational systems separated by logical layer has a few bonuses:
- One security model and access control to all of the data, including row level security and LDAP integration.
- Full auditing capability letting the analysts and administrator see how the platform is being use and check in its performance.
- One-point administration, which simplifies introduction of any changes to the environment, like adding new source or switching one off for maintenance or upgrade.
- Audit capabilities allowing for tracking data usage and analysis of changes impact - when sources evolve it is a lot easier to identify, what business intelligence and analytics application must be adjusted.
New data source types
Building effective business strategy based on data as an asset creates a need for new, completely exotic data sources. Our data governance processes never had a chance to manage things like big data platforms or cloud data storage systems or sources. It is now obvious that these new kinds of data need to be addressed and introduced into organizations' ecosystems. But the emerging question is how?
The easiest way is to deliver analytical islands that consume this data, but the real business advantage lays in merging those data types with the ones that we already build momentum on. Then we can, for example, get a better look at our customers, product usage patterns or hunt for opportunities scanning the social media.
At that point data virtualization comes in handy. For those tools and platforms reaching out to the cloud for data is a standard daily task, digging into the Hadoop cluster is as simple as loading data from CSV file. Having that exotic data available to users in parallel to standard ones gives them ability to build new analysis and reports with no new competences needed – but with a wider and more in-depth view of business. And all that happens in a well-governed environment with minimal changes to data governance processes.
Further reading
Please follow to read about the second scenario. In the next post, I'll discuss, how data virtualization can support information delivery to consumers.
Download a paper – The SAS Data Governance Framework