The data lake is a great place to take a swim, but is the water clean? My colleague, Matthew Magne, compared big data to the Fire Swamp from The Princess Bride, and it can seem that foreboding.
The questions we need to ask are: How was the data transformed and cleansed prior to reaching Hadoop? If multiple data sources are being loaded, are the business keys or surrogate keys aligned across data sets? How will dirty data affect the analytics?
As an ETL/ELT developer, I once spent a great deal of time building and scheduling jobs to ensure a clean source of data for our users. Now, with big data, the sources are more varied, the speed at which data enters the enterprise is faster and the volumes are bigger than ever.
Naturally, when I was on the ETL/ELT side of things, much of my time was divided between building data flows to support the data warehouse and building jobs to create analytic base tables. What if there were a better way to enable the business user? What if we could free up IT to focus on the care and feeding of the Hadoop environment?
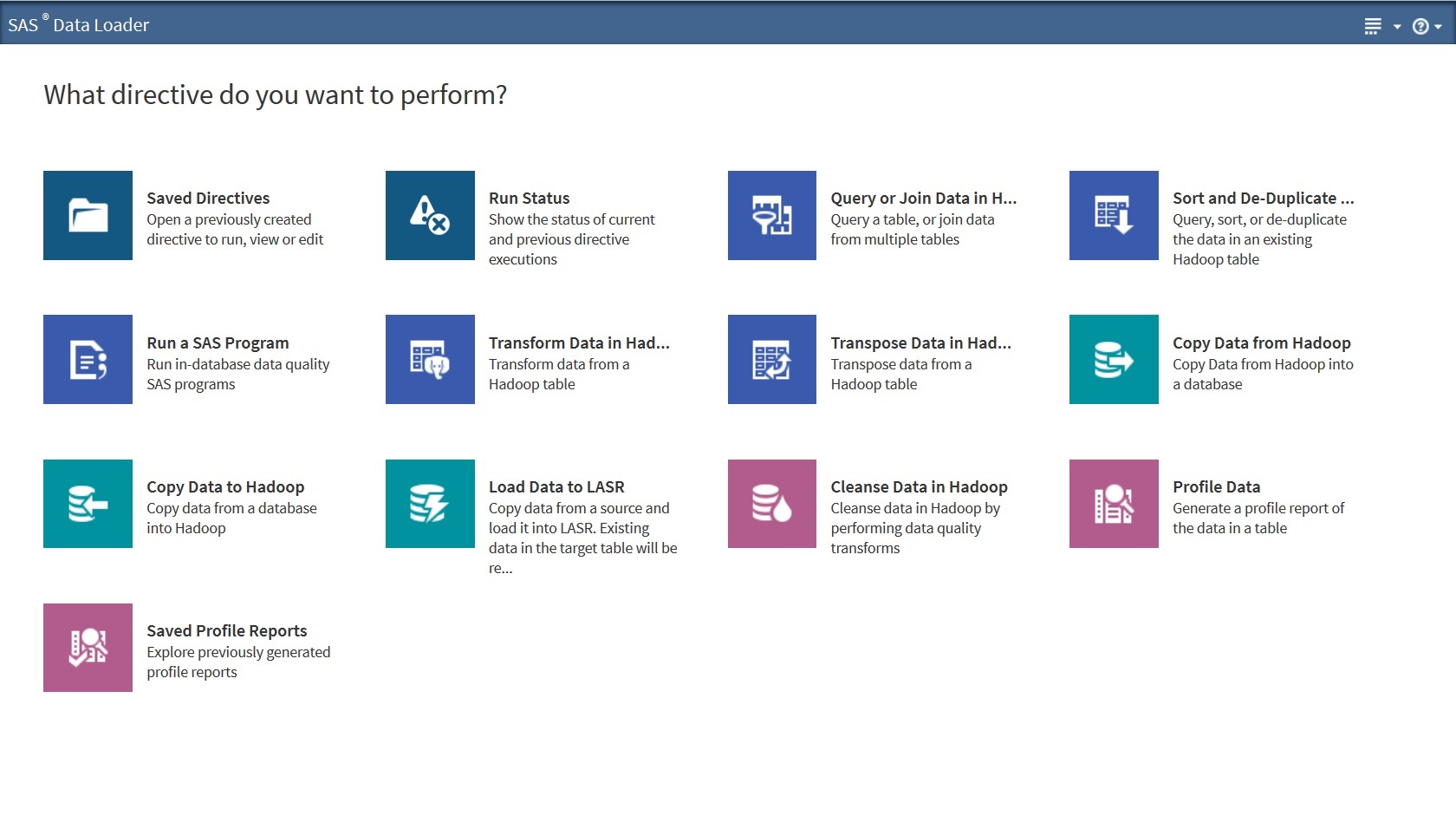
With business users wanting more access to all types of data for their analysis, it's important to give them the tools to manage that data. SAS Data Loader for Hadoop provides core data management capabilities, with minimal training, that allow business users to prepare data for analysis. Users can load data from DBMS (with SQOOP) or SAS datasets into Hadoop through the SAS Data Loader interface. Profiling capabilities are built in to allow users to investigate tables for patterns, uniqueness or incompleteness.
Users can join this new data table with other tables, transform and cleanse the data utilizing the SAS Data Quality Accelerator for Hadoop and the SAS Code Accelerator for Hadoop. Key functions such as identification analysis, parsing, and standardization allow data to be structured and categorized utilizing locale specific SAS definition library (Quality Knowledge Base) stored and accessed in HDFS.

Data scientists can use the interface to interact with the SAS Code Accelerator to develop DS2 code. This code can be executed via custom directives through the interface for more advanced data manipulation. Utilizing the performance and scalability of Hadoop, SAS Data Loader for Hadoop provides transpose or pivot of the data in Hadoop in preperation for exploration. Finally, the data set can be loaded in-memory in parallel for advanced reporting and analytic work with SAS Visual Analytics, SAS Visual Statistics or SAS In-Memory Statistics for Hadoop.
