Hadoop recently turned eight years old, but it was only 3-4 years ago that Hadoop really started gaining traction. It had many of us “older” BI/DW folks scratching our heads wondering what Hadoop was up to and if our tried-and-true enterprise data warehouse (EDW) ecosystems were in jeopardy. You didn't have to look hard to hear or read exclamations such as “The EDW is dead!” or questions like “Is my data warehouse a dinosaur?”
That was just three years ago.
Today, it’s not hard to find discussions—from formal research to industry events and online articles—that squelch the Hadoop dominance fears of yesteryear. The distinguished data warehousing expert Ralph Kimball joined Cloudera in a webcast earlier this year to talk about Hadoop and the EDW. In a lengthy Q&A at the end of the webcast, Dr. Kimball talked about the coexistence of these two technologies: “Conventional RDBMSs will be with us forever as they are superbly good at being OLTP engines and query targets for text and number data…Although the bigness of Big Data is impressive, it is less interesting than the variety. That is where Hadoop really makes a sustainable difference.”
A recent Gartner study also showed (see figure below) that the EDW—not Hadoop—is currently the most popular technology for deriving value from big data:
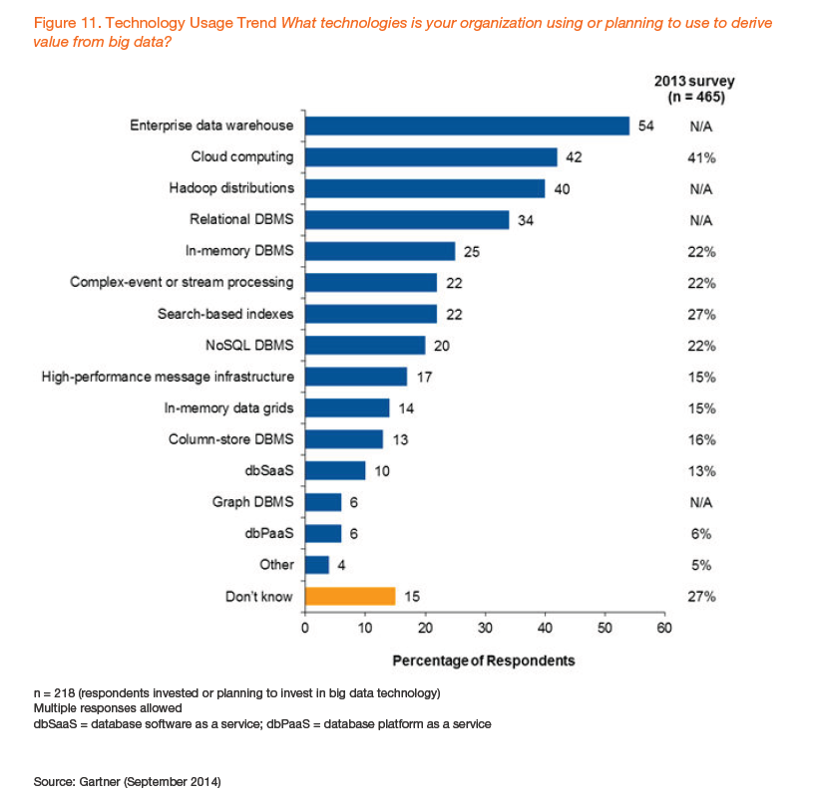
Besides demonstrating the popularity of the EDW, this chart shows the many technology options (including open source) that are available today to help address an organization’s big data initiatives. As you can see, Hadoop is not the only game in town when it comes to big data, despite the hype a few years ago.
But back to the question at hand: Will Hadoop mess up your data warehouse ecosystem? The short answer is “no”—which is good—but you already know that. The better question is: How can your organization use Hadoop to better manage and support your organization’s data (arguably one of its greatest assets)? This is where A Non-Geek’s Big Data Playbook: Hadoop and the Enterprise Data Warehouse can help.
This playbook was written for the technologically-savvy business professional who prefers pictures to words, simplicity to complexity, and briefer explanations to longer ones. It highlights six common “plays” on how Hadoop can be used to support your data ecosystem—and three of them don't even require “big” data.
Here’s a sneak peek at two of the more complex plays presented:
- Use Hadoop to extend your EDW as the center of your organization’s data universe. This play is geared towards companies that want to keep the EDW as the de facto system of record–at least for now. Hadoop is used to process and integrate structured, semi-structured, and unstructured data to load into the EDW. The organization can continue using its BI/analytics tools to access the data in the EDW, and alternatively, in Hadoop.
- Use Hadoop as the landing platform for all data and exploit the strengths of both the EDW and Hadoop. One advantage of capturing data in Hadoop is that it can be stored in its raw, native state. It does not need to be formatted upfront as with traditional, structured data stores; it can be formatted at the time of the data request. This process of formatting the data at the time of the query is called “late binding” and is a growing practice for companies that want to avoid protracted data transformation when loading the data into the EDW.
Hadoop is here to stay and it’s ready to “play” with your EDW. Download the Non-Geek’s Big Data Playbook today to help you figure out which plays make sense for your organization. And then do it.

2 Comments
Thanks for sharing such an informative post. Hadoop has been the rage for several years, but the larger business world is just starting to come to grips with how this technology will move from proof-of-concept into production. Some interesting points to note: Barclay’s just released a study (see “CIOs Uncertain About Hadoop’s Value: Barclays”) that indicates the adoption of Hadoop may happen gradually. CIOs are just not confident they can plug Hadoop into their data warehouse ecosystems and move ahead. Also, one of the findings from Gartner Analyst Merv Adrian’s research is that as tech executives gained more experience with Hadoop, they became less likely to think that it would eventually replace the data warehouse. https://intellipaat.com/
Adam, thanks for your comment. Yes, since this post went live in November, there have been some good reports talking about the state of Hadoop adoption - and they're even agreeing with each other! Like you noted, we're getting past the stage/fear of Hadoop being a replacement for the EDW; most organizations see it as a complementary solution. A recent CapGemini report showed that 27% of those surveyed considered their big data/Hadoop project successful, and only 13% were in full production. Hadoop is making a difference. One step at a time.