Get the latest machine learning algorithms and techniques
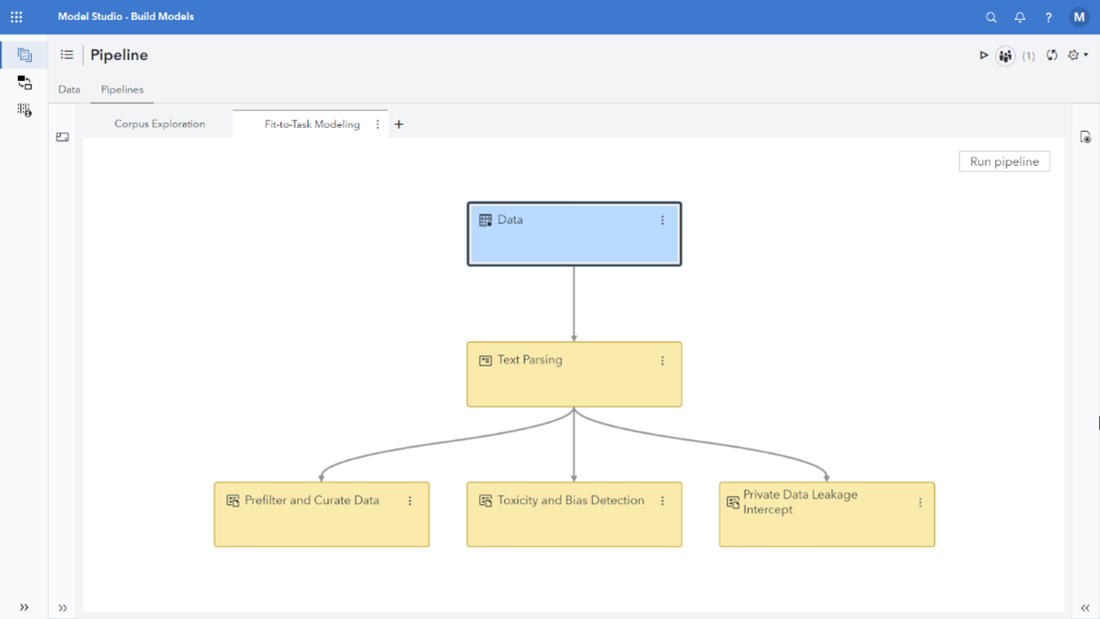
Three ways NLP can be used to identify LLM-related private data leakage and reduce risk

We often hear about cyberattacks, hackers, ransomware, and other nefarious deeds in the news, but not all data breaches are caused by third parties.



