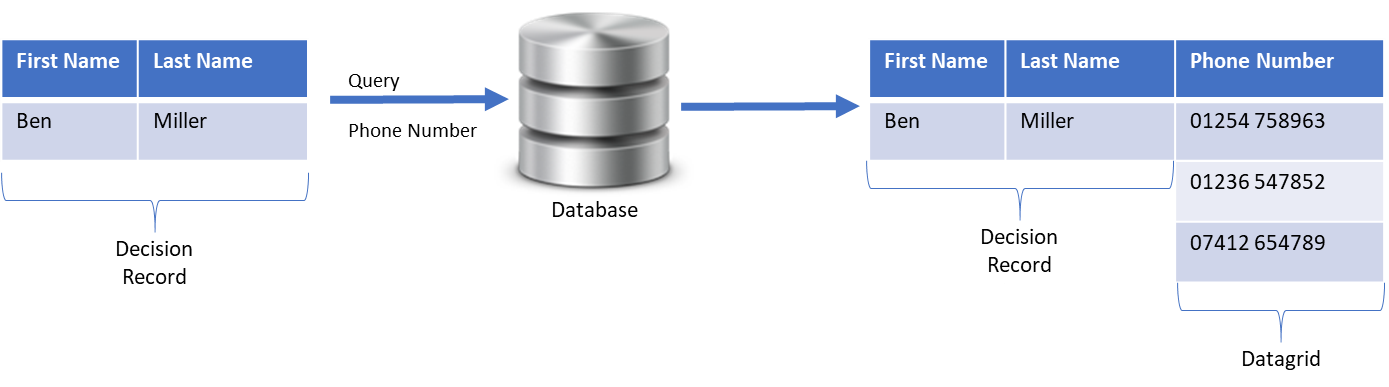
Blend, cleanse and prepare data for analytics, reporting or data modernization efforts

The case against automating data management

Phil Simon flip-flops from his last post.