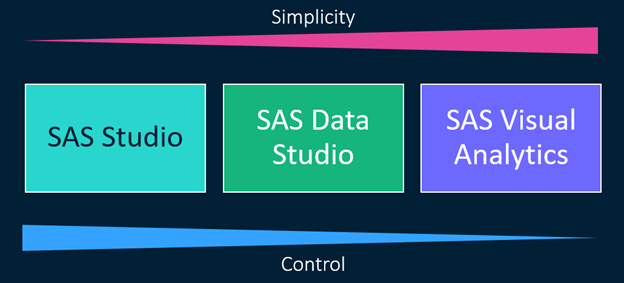
From weeks to minutes: How a data mapper agent can change the game

What if integrating your data for AI didn’t take weeks or months – but happened in minutes, without ever moving your data at all? That’s the vision guiding the development of a new data mapping agent at SAS. It’s not just a feature – it’s a potential shift in how