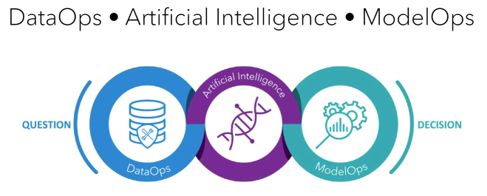
How ModelOps addresses your biggest machine learning challenges

Editors note: This is the first in a series of articles. According to the Global McKinsey Survey on the State of AI in 2021, the adoption of AI is continuing to grow at an unprecedented rate. Fifty-six percent of all respondents reported AI adoption – including machine learning (ML) –



