With the latest iteration of SAS Viya, SAS now offers monthly stable releases for SAS Viya 2020. This means new features are arriving every month. Personally, I am very happy with this monthly cadence. As an avid user of SAS Viya, each month I have a new capability at my disposal and there is always something to make my life a bit easier.
As an example, I am frequently thinking about how to productionalize and operationalize text analytics. Many organizations are still focusing on operationalizing their classification and prediction models, often leaving text models as science experiments or ad hoc jobs. But with the release of SAS Viya 2020.1.4, text categories and concept models can now be deployed into production with just a few clicks and used to score data in-batch and via API! You can also now use these models in decision flows. In today’s article, let me show you how easy it is to put these models into production and utilize these models for decisioning.
Registering and publishing text models
The text model I am using in this example is a categorization model built in SAS Visual Text Analytics using consumer complaint data from the Consumer Financial Protection Bureau’s Consumer Complaint Database. This model groups complaints into applicable categories. Once you are happy with your categorization model, you can easily register it from SAS Visual Text Analytics by right-clicking the Category node and selecting Register model.
Registering my model pushes it into a SAS Model Manager repository. This repository also hosts a rich treasure trove of metadata about your modeling project and models in one place. This enables organizations to find modeling documentation quickly.
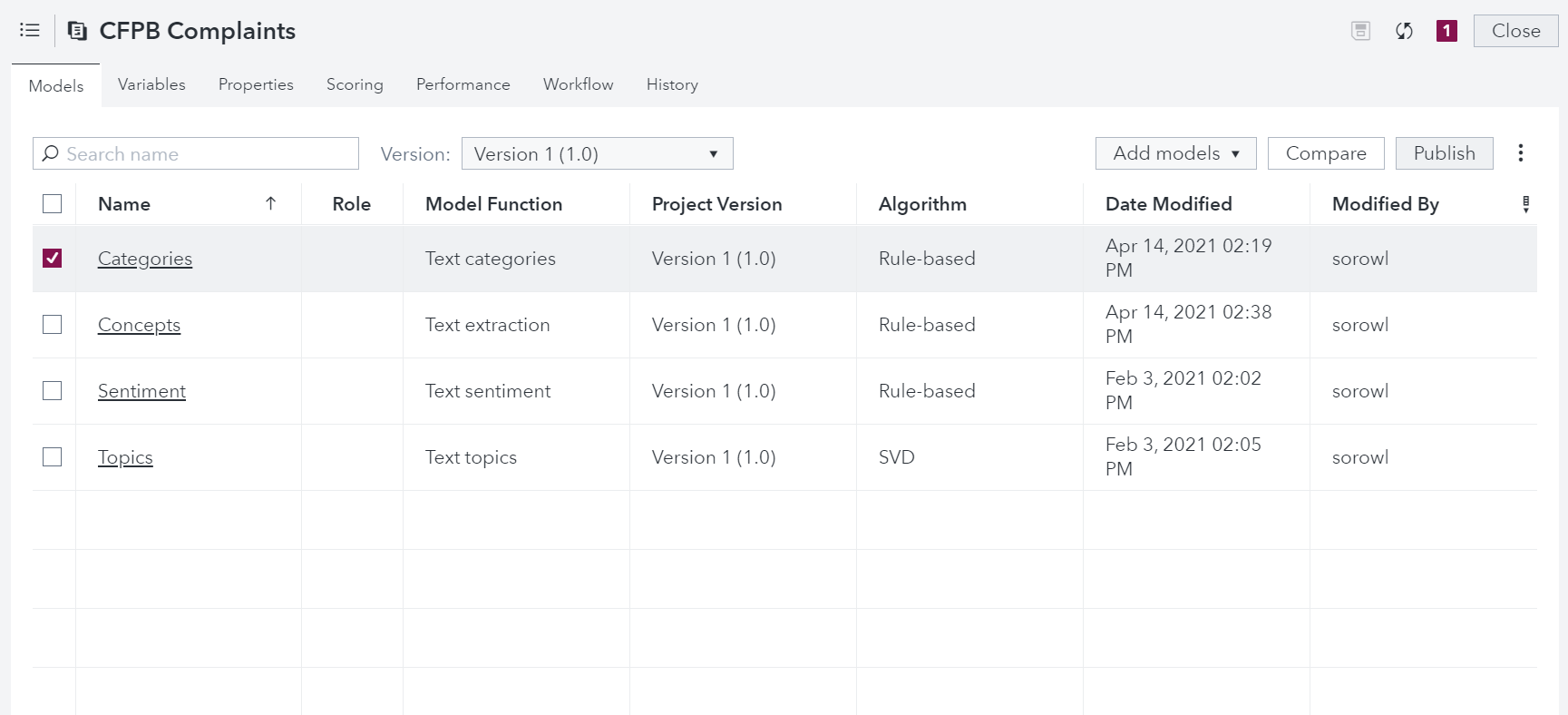
To publish a categories or concepts model, check the box to the left of the model. Next, select Publish in the upper right-hand corner. Give your deployed model a name and select the publishing destination. These models can either be published into SAS Cloud Analytics Service (CAS) or SAS Micro Analytic Service (MAS). In just a few clicks, you can register a text model into SAS Model Manager and in just a few more clicks, you can deploy a categorization or concept model. This gets models into production easily and quickly!
Testing the API endpoint
The benefit of publishing a model into MAS is that it exposes an API endpoint to the model. Before we add our category model into our decision flow, let’s test to see if we can call it from this API endpoint. I prefer to test my API calls from Python using the Requests package, but the beauty of APIs is that you can call them from a wide variety of languages!
The first thing we need when calling our model endpoint API is get an authentication token. The block of code below uses your username and password to get a token.
# To get credentials import getpass username = input("Username: ") password = getpass.getpass("Password: ") host = input("Viya Hostname: ") # Using POST request with username and password to get token from requests import request url = host + '/SASLogon/oauth/token' r = request('POST', url, data='grant_type=password&username=%s&password=%s' %(username, password), headers={ 'Accept': 'application/json', 'Content-Type': 'application/x-www-form-urlencoded' }, auth=('sas.ec', ''), verify=False) token = r.json()['access_token'] |
Now that we have our authentication token, we can start making API calls. The block of code below returns some helpful information about your deployed model, including the inputs the model is expecting and the outputs it is generating. It is always good to take a peek to ensure you are passing the expected inputs to your deployed model.
# Get name of deployed model modelname = input(“Deployed Name:”) # Add token into headers headers = {'Authorization': 'Bearer ' + token} # Embed deployed name into URL url = host + '/microanalyticScore/modules/'+ modelname + '/steps' # Get information about the deployed model r = request('GET', url, params={}, headers = headers, verify=False) r.json() |
With the information about the inputs, my deployed model is expecting and the URL to use for scoring, I can pass my complaint into my model below and see which categories my complaint falls into.
# Get complaint complaint = input(“Complaint:”) # Prepare input data input_data = '{"inputs":[{"name":"consumer complaint narrative", "value": "' + complaint + '"}]}' #Specify headers headers = {'Content-Type': 'application/vnd.sas.microanalytic.module.step.input+json', 'Authorization': 'Bearer ' + token} # Embed deployed name into URL url = host + '/microanalyticScore/modules/'+ modelname + '/steps/score' # Using POST request to get model outputs r = request('POST', url, data=payload, headers = headers, verify=False) r.json() |
An example of the returned response is below.
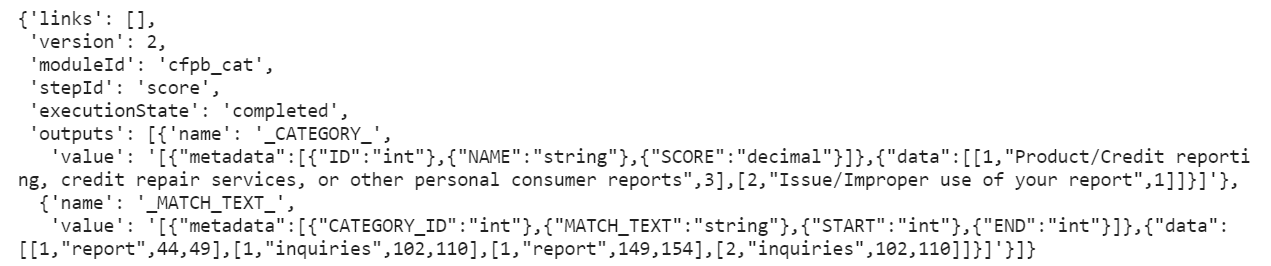
Embedded in the outputs, I can see the categorization my text model gave my complaint. A complaint can have multiple categories. In the example above, I see that this complaint was given two categories. Additionally, the outputs of our model about are returned in a data grid JSON string format. We’ll see this format used again in SAS Intelligent Decisioning!
Utilizing text in decisioning
Finally, to add your category or concept model into a SAS Intelligent Decisioning pipeline all you need to do is add a Model node to the decision and navigate to your model in the VTA repository. Another operation that takes just a few clicks and now you are ready to score text in SAS Intelligent Decisioning!
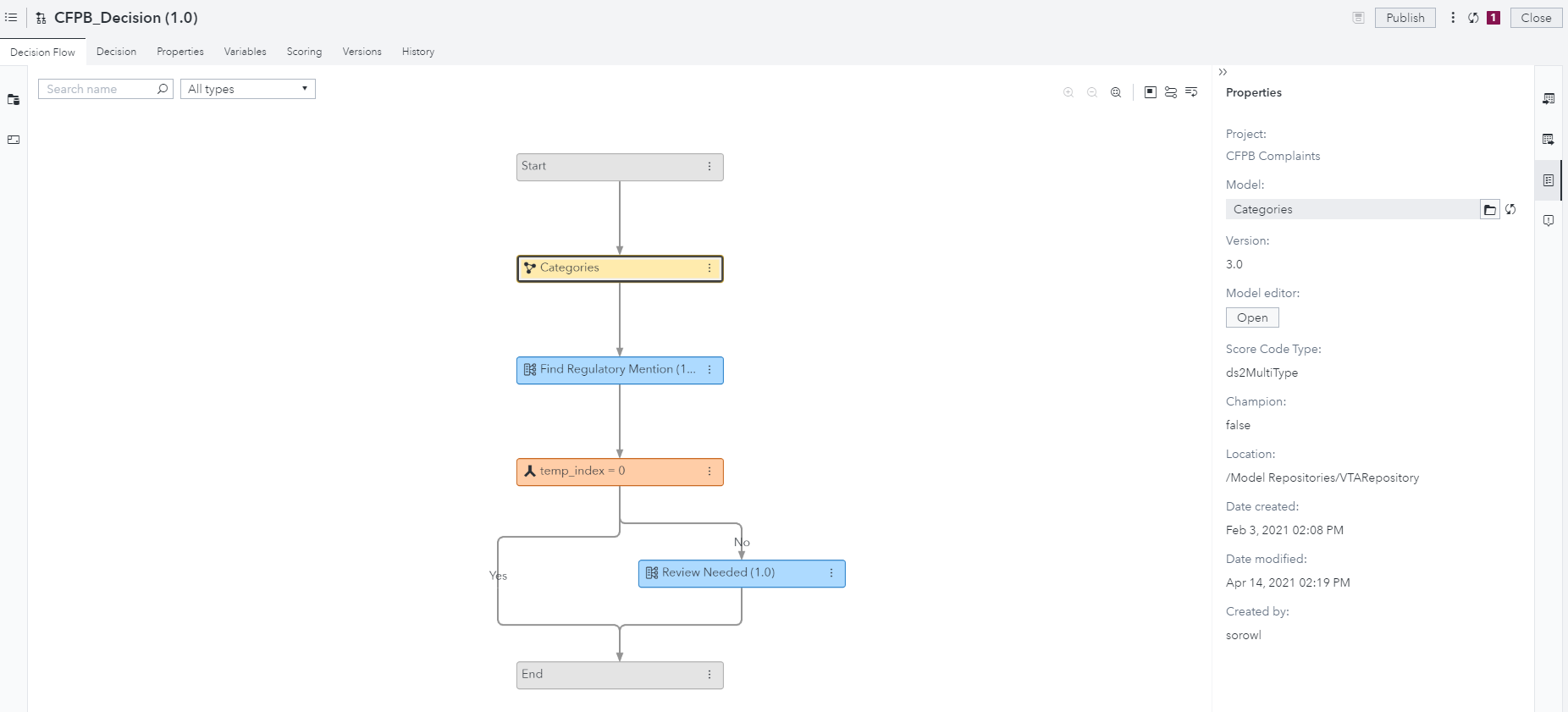
There are several use cases for using a text category model in a decisioning. Examples include flagging text to send to certain departments or specifying actions to take. In the example above, I am looking for regulatory mentions to flag a complaint for further review. Not to worry, these flows can be customized to fit an organization’s specific business needs.
The benefit of using a decision over a model is that a decision can provide an action. I ran the same complaint in a scenario test, and it returned the same categorization data grid as well as my flag for additional review. Since this complaint didn’t mention any financial regulations, further review is not necessary. The output of the test is below. This output shows an empty Review Flag and a formatted view of the data grid.

In conclusion, the monthly cadences of Viya 2020 offer a lot to get excited about. These cadences are bringing new capabilities to users faster. For example, the Viya 2020.1.4 release brought the ability to put text models into productions and into decisions with just a few clicks. Creating analytically driven processes based on unstructured text data has never been easier! Who else is excited to see what’s in store for the next cadence?






