It is increasingly possible to use text analytics to explore different types of data. When a news story this summer caught my eye, I decided to see if I could use SAS Visual Text Analytics (VTA) and SAS Visual Analytics (VA) on customer complaints to provide information that might be useful to regulators in the financial sector.
The news story was about a so-called neobank, a new kind of direct bank that operates online only. These banks tend to cater to low- to middle-income customers who have traditionally been underserved by banks. The issue was that many customers were reporting that the bank had denied them access to their funds and was also taking too long to resolve their complaints—a potential disaster for people on low incomes.
The bank, for its part, reported that the reason behind denying access to some accounts was to combat the exceptional spike in fraudulent deposits. However, this proved to be little consolation for its unhappy customers, especially those denied access to their money. There were many complaints to various consumer protection bodies and organizations across the US.
Finding data
I obtained over 400,000 consumer narratives from the Consumer Complaints dataset on the Consumer Financial Protection Bureau website, relating to the years 2018 to 2021. In the span of a month, I worked with visual text analytics software to identify some concepts, sentiments, and categories across variables like state, issue, and product.
Using the narratives written by the complainants, I identified four main concepts: Cannot Access, Closed Account, Stolen Money, and Unauthorized Transfers. The concept rules used language interpretation for textual information syntax, which includes Boolean and distance operators. Concepts are important because they influence how text is parsed to pull out specific pieces of information.
For example, in the Unauthorized Transfers concept, my rule was Concept_Rule: (Sent, "_c{transferred@}", (OR, "money@", "knowledge@")). Through SAS VTA, the platform automatically looks for any synonyms of transferred in the same sentence with a synonym of money or knowledge, as a way to find narratives in which the consumer complained of having money transferred from their account without their knowledge. Therefore, the concept rules were written by me and once they were ran in SAS VTA, automation took care of finding the narratives that fit my concept rules.
Separately, I created custom categories and tagged documents that fitted each one. SAS VTA generated categories including Managing an Account, Unauthorized Transactions, Fraud or Scam, and Closing Your Account using supervised learning on how the document issues were manually tagged. The code for categories used OR, AND, and NOT commands to identify keywords in the consumer narratives.
After manually generating all my concepts and categories, I ran the VTA pipeline so the platform would automatically find all the relevant consumer narratives and SAS VTA would also analyze the sentiment of each narrative. This information was then brought into Visual Analytics to allow exploration and visualization of the data.
Exploring data
The first step was to identify the top ten issues using a word cloud. I then explored these further using a geographical split to look at both categories and concepts by state. For example, the figure below shows the state-by-state analysis of the category ‘Closing an account’. It highlights that this issue was most prominent in Massachusetts, but it was also a problem in Arizona, Texas, Arkansas, and North Carolina.
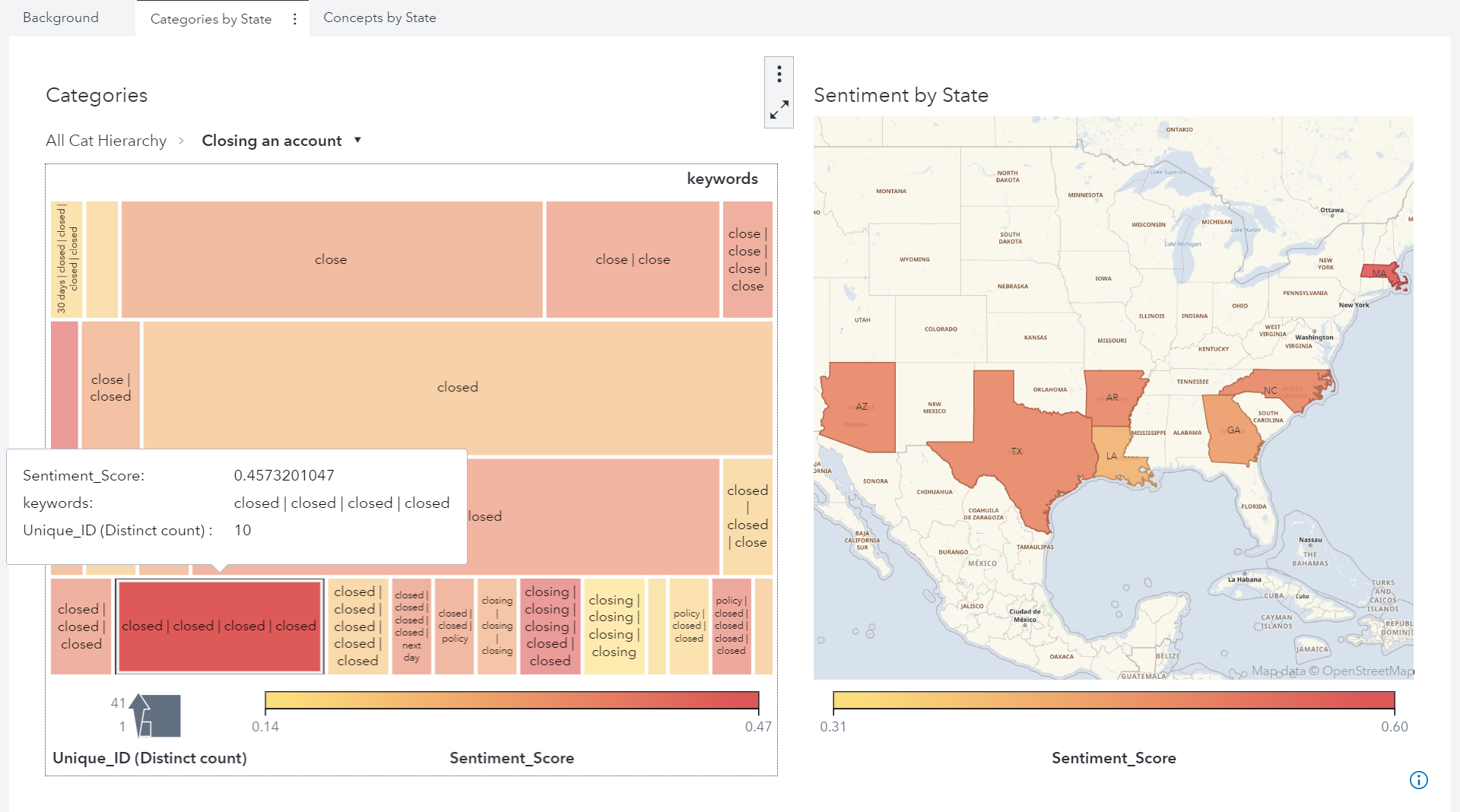
It is also possible to dig into the detail of specific consumer narratives, including the frequency of complaints. This can be done at both concept and category level, and provides both examples of narratives, and a picture of the type of issue. It was interesting to see that particular concepts and categories were more prominent in certain states. For example, the concept of ‘Stolen Money’ was raised more often in Texas and Virginia.
Overall, the complaints showed that consumers in almost all states were affected in some way, including not being able to access their account, having their account closed, seeing unauthorized transactions, or having their funds taken from their account by the bank.
Potential in investigations
Using a visual text analytics framework like this is interesting—but it could also assist regulators to investigate consumer complaints faster and more effectively. Reading through 400,000 customer accounts and determining which states are most affected is a tiresome job without SAS VTA and SAS VA. The data is just too raw and large to be analyzed only through the dataset. This approach should therefore help to strengthen consumer protection and clamp down on unfair, misleading, or abusive financial market activities.
Financial providers and other companies could also use this kind of framework to dig deeper into their own complaints data. They could therefore identify problems and issues affecting their customers, and respond proactively, without waiting for regulatory findings. Indeed, rapid and well-directed action in response to customer complaints could, ultimately, mean that they are not subject to regulatory investigations.
It is important to stress that this kind of text mining framework is not intended to replace human analysts in any way. However, it could be a useful aid to those analysts in identifying particular problems or geographic areas that have experienced issues. Ultimately, this should enable regulators to better protect consumers from risk from financial products and services. In the future, simply uploading new data into SAS VTA and running it through the pipeline would be enough to refresh the model to hunt for the same concepts and categories with new data. This information could then be transferred to the VTA model that has already been developed, to visualize the new data.
For a more in-depth version of this article click here.

2 Comments
I agree that what this showcases is a text analytics framework that is widely adaptable to a variety of problems, both for government and for the commercial sector. The capability to identify key terms and themes of interest in the form of entities and visually depict them over time can help organizations focus in on, say, 1-3% of a large volume of text narratives for a particular issue making analysis much more manageable. Fantastic work, Fernanda!
Very interesting analysis, and a great use case for SAS text analytics!