It’s here!
Statistics is a core component of data analytics and machine learning. Despite the "bigness" of the data, statistics still has a lot of application. The role of statistics remains what it has always been and is even more important now. Perhaps the core statistical task in (traditional) statistics is inductive inference from data to models and scientific conclusions. This core task is still very relevant in the advent of massive data sets.
Replicability, stability, heterogeneity, causality, and uncertainty are the five basic principles of statistics, and they all hold equally well with big data.
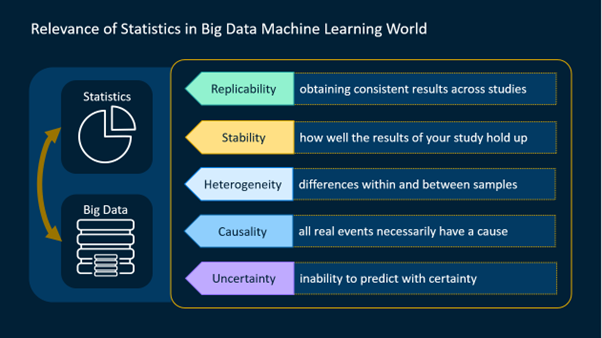
Ideally, in big data scenario too, the conclusions and findings are replicable and generalizable. If you imagine running the analysis again, now on a new data set, would the outcome be similar, meaning that the model is stable? How would you find out what similarity in outcomes means and how to evaluate accuracy, to quantify uncertainty. Understanding heterogeneity in large-scale data sets is more crucial and comprehending causality and its connection to robust prediction is still interesting.
Are you interested in machine learning and want to grow your career in it? The key to machine learning is using the right data preprocessing techniques, understanding the algorithm, cutting through the equations and Greek letters, and making sense out of complex results.
Developing an accurate understanding of statistics will help you build robust machine learning models that are optimized for a given business problem. SAS launched a new course that provides a comprehensive overview of the fundamentals of statistics that you'll need to start your data science journey. This course is also a prerequisite to many courses in the SAS data science curriculum.
In this course, you learn how to:
- explain the relevance of statistics in the big data and machine learning world
- relate statistical and data science terminology
- generate descriptive statistics, explore data with graphs and plots, and perform testing of hypotheses
- detect associations among variables and perform linear regression
- compare explanatory modeling with predictive modeling
- describe trade-offs between bias and variance
- fit a logistic regression model and score new data
- explain the statistical foundations of machine learning
- prepare your data for machine learning modeling using transformations, imputation, standardization, and variable reduction
- discuss data difficulties and modeling issues, and their statistical solutions.
It also gives you opportunity of hands-on using SAS Studio tasks to perform your data analysis. This course is available in three formats: face-to-face classroom training, remotely connected live web, and self-paced e-learning.
Learn more
- More details on this brand-new SAS course can be checked out at:
Statistics You Need to Know for Machine Learning - Explore the Learning Paths this course is a part of:
SAS Training - Learning Paths - Also check out this On-Demand Webinar:
The Data Scientist Learning Journey: Statistics You Need to Know for Data Science | SAS
