 This post explains:
This post explains:
- how the order of your data can differ when you run a DATA step with a BY statement in SAS®4 versus in CAS
- how to achieve the same results in CAS by using the ADDROWID data set option, which was introduced in SAS® Viya®1
DATA step processing with a BY statement in SAS 9.4 and CAS
In SAS 9.4, the order of your data remains constant when you run a DATA step with or without a BY statement.
However, running a DATA step in CAS is different. It is essential to understand how processing works when running a DATA step in CAS to avoid possible unexpected results.
CAS DATA step processing overview
When a DATA step runs in CAS, CAS distributes the code and data across multiple workers and threads, as shown below:
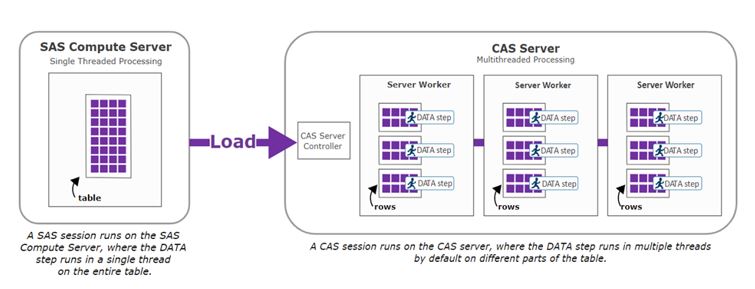
Source: SAS Help Center: Data Step Processing in CAS
The code that executes on each worker and thread is the same, but the portion of data is unique for that worker and thread.
CAS DATA step processing with a BY Statement
When you use a BY statement in the DATA step that is running in CAS, the data is grouped by the unique values of the BY variable. Each resulting BY group is maintained when distributing the code and data. However, because of the process by which CAS distributes and reassembles the data, the order of the data within each by group is not guaranteed. This change in order can occur with or without a BY statement. This reordering becomes very important when you use FIRST. and/or LAST. variables in your DATA step. Since the order is not guaranteed when running in CAS, results are almost assuredly different when you compare the output from running in SAS 9.4 to running in CAS.
Example of DATA Step in CAS
Here is an example of how the order of the data can be different when running a DATA step in CAS. In this example, I use the SASHELP.CARS data set. I compare the output of running a DATA step using BY-group processing in SAS 9.4 to the output produced from running the exact same code in CAS.

Here is the output from both PRINT procedures, which are clearly not the same. The model that is associated with the make is different in the output that is created in CAS.
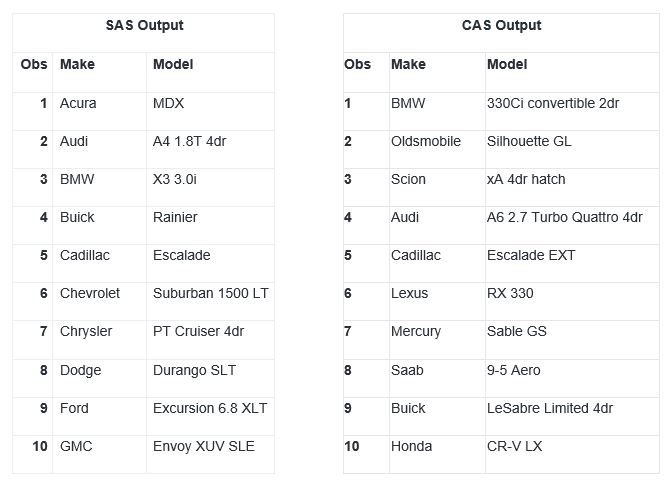
The output from running the step in SAS 9.4 shows the make in alphabetic order with the first model based on an alphabetic sort order, which is the original order of the data. This output is the same each time I run this code in SAS 9.4. However, the value of model is not the same each time I run the step in CAS. When processing in CAS, the BY groups are retained, but the order of rows within the BY group cannot be guaranteed.
ADDROWID data set option
The ADDROWID data set option was created so that the results created in SAS can be replicated when running in CAS. This option creates the new variable _ROWID_ that increments numerically for each row in the table. The value of _ROWID_ is 1 for the first row, 2 for the second, 3 for the third, and so on. So you can perform BY-group processing using FIRST. and LAST. logic with ADDROWID to generate the same results in CAS that you get in SAS 9.4.
Example Using ADDROWID and _ROWID_ in CAS
Here is an example of how to use ADDROWID and _ROWID_ to maintain the order of the data. This is the same code I ran earlier in CAS, but this time, I used the ADDROWID option when creating the CARS table. Adding this option creates the sequential _ROWID_ variable that I can then use in the BY statement:
cas; /* Starts the CAS session. */ caslib _all_ assign; /* Creates the CASUSER libref. */ data casuser.cars(ADDROWID=YES); set sashelp.cars; run; /* Sorting the data is not required when you run in CAS. */ data casuser.cascars; set casuser.cars; by make _ROWID_; if first.make then output; run; proc print data=casuser.cascars(obs=10); var make model; run; |
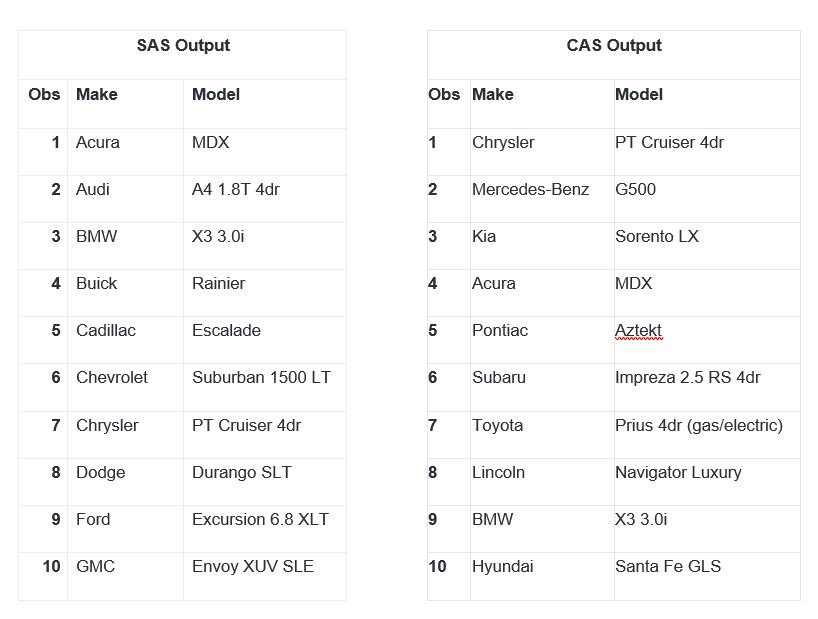
Listing _ROWID_ as the last variable in the BY statement creates a unique BY group for each row. This code enables you to obtain the same results from running in SAS 9.4 when running the DATA step in CAS. Now, the output from the PROC PRINT steps shows that CAS matches the make and model from the values in the data set in the same way that they are matched in SAS 9.4:
Final thoughts
When running your DATA step in CAS, it is important to understand how the code and data is distributed and how this can affect your output. The order of your data can change when distributing the code and data across threads and workers and then reassembling the data after processing has finished. This is especially important to be aware of when you use BY-group processing in the DATA step.
Starting in SAS Viya 2020.1, the ADDROWID data set option was introduced to account for this behavior. This easy-to-use option allows you to ensure that the output produced when running your DATA step in CAS matches the output produced when running in SAS 9.4
References
SAS Institute Inc. 2022. "ADDROWID Data Set Option." In SAS® Viya® Programming Documentation. Cary, NC: SAS Institute Inc.
SAS Institute Inc. 2022. "Grouping and Ordering." In SAS® Viya® Programming Documentation. Cary, NC: SAS Institute Inc.
