You've probably heard by now the new SAS Viya runs on containers orchestrated by Kubernetes. There is a lot to know and learn for both experienced users and k8s noobies alike. I would recommend searching the SAS Communities Library for a wealth of information on deployment, administration, usability, and more.
If you're here, you're probably looking to deploy SAS Viya on Azure Kubernetes Service (AKS) and you're thinking about making data available to users' sessions. Maybe you have SAS deployed today and are doing that already with an NFS server? This is still possible in this new paradigm, but perhaps you haven't already deployed an NFS server in the cloud, or at least inside of the same Virtual Network as your AKS cluster and you're looking to avoid communicating over public IP addresses. Or, maybe you just don't want to manage another VM to hold an NFS server. Enter: Azure Files. These are a great option if you want to make the same data available to multiple VMs, similar to the way an NFS export works. In our case with SAS Viya on Kubernetes, what we want to do is make the same data available to multiple containers which we can do with Azure Files shares as well.
Pro Tip: Opt for Premium File Shares for better performance. These run on SSD-based hardware and use the NFS protocol. The Standard ones run on HDD-based hardware and SMB protocols, which tends to be slower with data over a few MBs.
If you're not yet familiar with the relationships between Storage Classes, Persistent Volumes, and Persistent Volume Claims, here is a great walkthrough. While it's written with Azure storage options in mind, the general relationships between those k8s objects are always the same. Now that we're all on the same page, we know we need to create a Persistent Volume (PV), which refers to an Azure File share and then define a Persistent Volume Claim (PVC) tying back to that PV. Our container specs request the PVC and in turn, have the Azure File share mounted into them. This allows multiple containers access to the same data. A quick read through this guide on doing all of this highlights why we're here...What if you don't want to mount this data with 777 or 755 permissions?
That's the point of today's post: to show how you can use Azure Files with group-based access patterns to support a line of business (LOB)- or project-based security model for accessing data with SAS Viya.
So here’s the punchline
Follow the steps below as your guide for accomplishing everything we've already talked about, plus some SAS Viya-specific steps to ensure that user access occurs as intended. In the next section we'll get into details, so you can replicate this setup in your deployment.
But one more quick note: the rest of this post assumes that your SAS Viya environment is configured to make calls to an LDAP provider to facilitate user and group information. If you've opted to leverage a SCIM provider like Azure Active Directory or Okta instead, keep reading but stay tuned for my next post which will cover a couple additional steps you'll need to account for.
- Make sure there’s an LDAP group for each LOB or project in your security model. Put all the relevant users in them. Your life will be simpler if you have your SAS Administrator(s) in each group as well, but we can work around that if it's not feasible.
- Create a storage account for each LOB/project (sort of optional) and then create your Azure File Share(s).
- For each storage account, create a Kubernetes Secret to store the Access Key (this is why a separate Storage Account per LOB/project is optional; technically you could share the keys but it's not recommended).
- For each File Share create a Persistent Volume (PV), a Persistent Volume Claim (PVC), and Patch Transformers to make sure the data gets mounted to all necessary containers.
- Create another PatchTransformer to add the mount point(s) to the CAS allowlist.
- Make sure all the volumes and claims end up in the resources section of your kustomize.yaml.
- Finally, make sure all of the transformers are listed in the transformers section of your kustomization.yaml, then build and apply.
- Put all users in the CASHostAccountRequired Custom Group.
- Bounce all the CAS containers.
- Rejoice!
Let’s walk through that, a little slower now…
LDAP GROUPS
For this example I'm going to stick with just one group: the HR line of business (LOB). That group's GID in my LDAP environment is 5555.
STORAGE ACCOUNTS
Note: If the Storage Accounts and File Shares already exist at your site, with or without data already in them, that's totally fine, we'll just create the secret(s) and you can skip this step.
For this walk through I'm using a separate Storage Account for each LOB/project so we can also separate the access keys. Just generally a good practice since access keys are already a hefty object, but there's technically nothing stopping you from using the same Storage Account for multiple LOBs/BUs.
A word to the wise: if you create a storage account for this, make sure to pick this on the “Networking” tab:
![]()
and this on the "Advanced" tab:
![]()
That unique combination will yield no errors and no public access to your data. Regardless of whether you created the storage accounts, or they pre-existed, we’ll need to store the key for each one in a Kubernetes Secret. We'll see that in a later step.
Finally, create a File Share for each LOB/project in your storage account(s, however you decide). You can put data in now or wait until later.
KUBERNETES SPECIFICATIONS
A quick note on the of each of the code blocks to follow: I include the filename and path in a # comment in the initial line. The paths will make more sense in the last section where we see how to put these all together. Where I use $deploy, I am referring to whatever directory you create to store all of the files to customize and build your SAS Viya environment.
Create a Secret manifest
All right, let's get into the meat and potatoes. First you'll create each LOB/project Secret (or just one if you went that route). I will create it in a separate namespace from the one SAS Viya will be deployed into so that I can reuse this secret for multiple SAS Viya deployments. For that reason, I chose not to put it in the same $deploy directory with the rest of my deployment-specific manifests. Here's an example of one way to do it:
# $someSafeLocation/azure-hr-storage-account-key.yaml apiVersion: v1 kind: Secret metadata: name: hr-azure-sa-key type: Opaque stringData: azurestorageaccountname: hrdemodata azurestorageaccountkey: <keyStringHere> |
I am keeping this simple for illustrative purposes. Be aware when creating this Secret, k8s will only base64 encode it. There are other extensions and add-ons for actually encrypting your Secrets in k8s but that's out of scope for this post. You could replace the stringData property with the data property and then use an already base64-encoded value for visual obfuscation, but that's easily decodable, so this really shouldn't be stored in source control regardless.
At this point you should apply the secret:
# $deploy/ kubectl apply -f $someSafeLocation/azure-finance-storage-account-key.yaml -n $myKeysNamespace |
Create a Persistent Volume (PV) manifest
Next, you’ll create your PersistentVolume similar to this example:
# $deploy/site-config/volumesAndClaims/hr-data-storage-volume.yaml apiVersion: v1 kind: PersistentVolume metadata: name: hr-data-storage-<deploy> # The label is used for matching the exact claim labels: usage: hr-data-storage-<deploy> spec: capacity: storage: 1Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain azureFile: secretName: hr-azure-sa-key shareName: viyahrdemodata secretNamespace: afs-data readOnly: false mountOptions: - dir_mode=0770 - file_mode=0770 - uid=2222 - gid=5555 |
Consider replacing the the <deploy> suffix at the end of the name and usage properties with some unique identifier to this SAS Viya deployment, like the name of the namespace. I'll explain why in the next section.
The secretName comes from the name property in the first step and the shareName is the name of the File Share for this particular LOB inside the key's Storage Account. secretNamespace is pretty self-explanatory, it’s where I created the secret. I did this in a separate namespace from where my SAS Viya deployment will live so I can reuse the same secret for multiple environments, if I need to.
We still have the mountOptions specification here, but this pattern equates to giving anyone in our HR LDAP group (gid 5555) full access, but not world access. The SAS Admin (uid 2222) in my case owns the files. You might pick a LOB/project lead here instead.
Create a Persistent Volume Claim (PVC) manifest
Moving along, we need to create the PersistentVolumeClaim which is what the containers needing access to the data to serve up to users' sessions will request. It will tie them back to the volume specification we just created.
# $deploy/site-config/volumesAndClaims/hr-data-volume-claim.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: hr-volume-claim annotations: # Set this annotation to NOT let Kubernetes automatically create # a persistent volume for this volume claim. volume.beta.kubernetes.io/storage-class: "" spec: accessModes: - ReadWriteMany resources: requests: storage: 1Gi selector: matchLabels: usage: hr-data-storage-<deploy> |
In this case we don't need to add a unique identifier to our PVC's name because it is a namespace-scoped resource already. There is a one-to-one mapping to PVs, but because PVs are not scoped to any namespace by nature, we end up tying to it to one due to this mapping. Just as when creating my Secret in it's own namespace to reuse it for multiple SAS Viya environments, I expect to have multiple but similar PVs - their only difference being which SAS Viya environment they belong to. Hence, the unique identifier on those.
Take note of the fancy annotation here. The comment tells all. By the way, I am modelling this after the examples in the Azure Files Kubernetes Plug-In docs. The very last attribute is also very important: the name hr-data-storage- is the value of the usage label from the PersistentVolume spec above. This is what links these two things together.
Mount the PV using the PVC
To make sure that these volumes get mounted into all CAS and SAS Compute containers for both in-memory and traditional sessions, we'll use PatchTransformers and targert specific types and named k8s objects like this:
# $deploy/site-config/transformers/add-hr-demo-data-to-CAS.yaml apiVersion: builtin kind: PatchTransformer metadata: name: add-azure-hr-data patch: |- - op: add path: /spec/controllerTemplate/spec/volumes/- value: name: hrdata persistentVolumeClaim: claimName: hr-volume-claim - op: add path: /spec/controllerTemplate/spec/containers/0/volumeMounts/- value: name: hrdata mountPath: /mnt/hrdata target: group: viya.sas.com kind: CASDeployment name: .* version: v1alpha1 |
# $deploy/site-config/transformers/add-hr-demo-data-to-Compute.yaml apiVersion: builtin kind: PatchTransformer metadata: name: add-azure-hr-data-compute patch: |- - op: add path: /template/spec/volumes/- value: name: hrdata persistentVolumeClaim: claimName: hr-volume-claim - op: add path: /template/spec/containers/0/volumeMounts/- value: name: hrdata mountPath: /mnt/hrdata target: kind: PodTemplate name: sas-compute-job-config version: v1 |
The target is, somewhat confusingly, listed at the end of both manifests. In the first one we're targeting all CASDeployments which are the k8s Custom Resources that define CAS. In the second we're targeting all PodTemplates that are called "sas-compute-job-config" which is how we ensure this data gets mounted into all of the containers that get dynamically spun up to support individual user sessions.
The claimName in both manifests has a value equal to the metadata.name property from the PVC manifest in the last step. The name and mountPath value within both of the patches (in my case those values are "hrdata" and "/mnt/hrdata" respectively) can be whatever you like. The later will end up being the name of the directory inside the containers.
Add the new mount points to the CAS allowlist
The details of CAS allowlists are a little out of scope for this post, but my colleague Gerry Nelson, covered this topic deeply his Accessing path-based data from CAS in Viya article. The general concept though is we can only point to data from approved locations, which was implemented to strengthen our security posture when we moved to containerized Kubernetes deployments. If we miss this step, users will not be able to load any of this data to CAS to work with it in memory.
# $deploy/site-config/transformers/add-demo-data-to-allowlist.yaml apiVersion: builtin kind: PatchTransformer metadata: name: cas-add-allowlist-paths patch: |- - op: add path: /spec/appendCASAllowlistPaths value: - /cas/data/caslibs - /mnt/hrdata target: group: viya.sas.com kind: CASDeployment name: .* version: v1alpha1 |
The target is similar to what we saw in the last step, it's in charge of making sure this change gets applied to any CAS pods that are created. The list of values within the patch make up the new allowlist. The first path in the list should stay to maintain access to the OOTB paths, and then you can add additional entries to represent your newly-mounted data. Note the paths you add here should correspond exactly to the mountPath values from the PatchTransformers in the last step (in my case that was "/mnt/hrdata"). But the fact we specify a list here means we use this same transformer for all of the projects/LOBs in our security model.
Put all users in the CASHostAccountRequired Custom Group
Finally, we need to add an environment variable to all the CAS pods ensuring all users will spawn PIDs with their own UIDs and GIDs. If we skip this step, then our user's sessions will attempt to access data mounted into our containers as a service account, usually 'cas'. This will not work with the group-based access we set up when defining our PVs above, since only group members have access. If you're familiar with this process in earlier versions of SAS Viya, this would be the equivalent of creating the CASHostAccountRequired custom group and then ensuring all users end up in it, except easier.
# $deploy/site-config/transformers/set-casallhostaccounts-envvar.yaml apiVersion: builtin kind: PatchTransformer metadata: name: casallhostaccounts-environment-variable patch: |- - op: add path: /spec/controllerTemplate/spec/containers/0/env/- value: name: CASENV_CASALLHOSTACCOUNTS value: "ALL" target: group: viya.sas.com kind: CASDeployment name: .* version: v1alpha1 |
Not too much new here. The target behaves as before and the patch adds an environment variable to the proper level in the manifest for the target CASDeployment Custom Resource.
A quick aside
I just have to mention this. If you get curious and exec into a CAS container and try to run an ls on one of these newly-mounted paths, you will get denied. That's because the new SAS Viya no longer requires a tight coupling with user identities on the hosts it's running on - as it shouldn't. Configuring something like SSSD so the underlying hosts (in our case, containers) can facilitate users and groups from your LDAP/AD, which is required in a SAS Viya 3.x environment, would add too much size and complexity to our containers. Instead, the CAS containers themselves run as an internal 'sas' user (UID 1001) which doesn't have any access to our mounts because of the access model we set up when we defined the PVs above.
So how do users actually get access to the data then? By default in the new SAS Viya, the SAS Identities Service will pull your users UID and GID information out of the configured LDAP provider. This, in combination with this environment variable, spawns PIDs for your user's CAS sessions as their UID/GID. Further, these sessions, associated with a PID running as the user, are not denied when trying to access allowable mount points. Meaning, if the HR group in our example (GID 5555) is in their secondary groups then they will be allowed, and otherwise denied.
And what if you're environment is configured to use a SCIM provider like Azure Active Directory or Okta instead of an LDAP provider? Likely, in that case your provider won't facilitate user and group information (unless you have something like Domain Services for Azure Active Directory turned on). So how will we manage group-based access without UID and GID information coming from the provider? Stay tuned for the next post!
PUTTING IT ALL TOGETHER
Now we need to make sure all the resources we've defined actually get applied to our environment. For the sake of simplicity, I'm assuming you already have SAS Viya deployed into a namespace on Kubernetes and you're familiar with how we use Kustomize to bundle up our customizations to the vanilla manifests shipped to you and apply that bundle to Kubernetes. If not, keep reading to capture the gist and then take a look at the How do I kustomize a SAS Viya deployment? SAS Communities article.
Structure the sub-directories inside of your site-specific (site-config) however makes sense to your business. Here's how I went about it for the files relevant to this post:
# $deploy/site-config /transformers - add-demo-data-to-allowlist.yaml - add-hr-demo-data-to-CAS.yaml - add-hr-demo-data-to-Compute.yaml - set-casallhostaccounts-envvar.yaml /volumesAndClaims - hr-data-storage-volume.yaml - hr-data-volume-claim.yaml - kustomization.yaml |
The only file out of that list we've yet to see is this one:
# $deploy/site-config/volumesAndClaims/kustomization.yaml resources: - hr-data-storage-volume.yaml - finance-data-storage-volume.yaml - hr-data-volume-claim.yaml - finance-data-volume-claim.yaml |
This directory structure/organization, along with the kustomization.yaml inside the same directory, allows me to add the entire $deploy/site-config/volumesAndClaims path to the resources section of my main kustomization.yaml file, which keeps it cleaner. When I'm ready to add PVs and PVCs to support more projects/LOBs, I will add them to the list in the $deploy/site-config/volumesAndClaims/kustomization.yaml file.
Note that if you are using the SAS Viya Deployment Operator, you will need to move these PV and PVC specs outside of your kustomization.yaml and apply them separately from the SAS Viya deployment process.
Here's a peek at my main kustomization.yaml:
# $deploy/kustomization.yaml ... resources: - sas-bases/base - ... - site-config/volumesAndClaims - ... ... |
Next, we need to add all the Transformers we created to the transformers section of our main kustomization.yaml file.
# $deploy/kustomization.yaml ... transformers: - ... - site-config/transformers/add-hr-demo-data-to-CAS.yaml - site-config/transformers/add-hr-demo-data-to-compute.yaml - site-config/transformers/add-demo-data-to-allowlist.yaml - site-config/transformers/set-casallhostaccounts-envvar.yaml - ... ... |
If you're a visual person like I am, I've included a map of these files and to which namespace they should be deployed at the bottom of this post that might help you.
Then in typical Kustomize fashion, we'll bundle up our customizations and rewrite the site.yaml file that holds the manifests for this SAS Viya deployment. We'll then apply that with kubectl, which conveniently only applies the net-new changes to our namespace.
# $deploy/ kustomize build -o site.yaml kubectl apply -f site.yaml -n $namespace |
To finish things off, we need to bounce the CAS server and any of it's Workers which we can do by deleting the Pods controlled by the CAS Operator. Note, in general, Pods are the only "safe" thing to delete because the Replica Set that backs them ensures they get replaced.
kubectl -n $namespace delete pods -l casoperator.sas.com/server=default |
VALIDATING THE END RESULT
After completing the process, we want to verify the results. First, start a SAS Studio session and validate the CASALLHOSTACCOUNTS variable was successfully set with the serverStatus action using the following code:
cas; proc cas; bulitins.serverStatus result=results; /* describe results; */ print "CAS Host Account Required: " results.About.CASHostAccountRequired; run; |
Verify the output shows “ALL”.
Next, create the global caslibs in SAS Viya. For instructions on creating these, see this page of our documentation (hint: use PATH, not DNFS). Make sure to use the mountPath value from your $deploy/site-config/transformers/add-hr-demo-data-to-CAS.yaml file above.
Finally, we'll apply some authorizations on the global caslib itself, which will add to the POSIX permissions we've already set on our PV. The image below is an example of the project/LOB-based security pattern I typically use for caslibs, applied to my newly-created HR caslib. No full promote! With this pattern, only users in the HR Members LDAP group (GID 5555) will even see this caslib exists, let alone work with it. They won't be able to alter this caslib or adjust who else has access to it. For more information on setting authorizations on caslibs, see this section of our documentation.
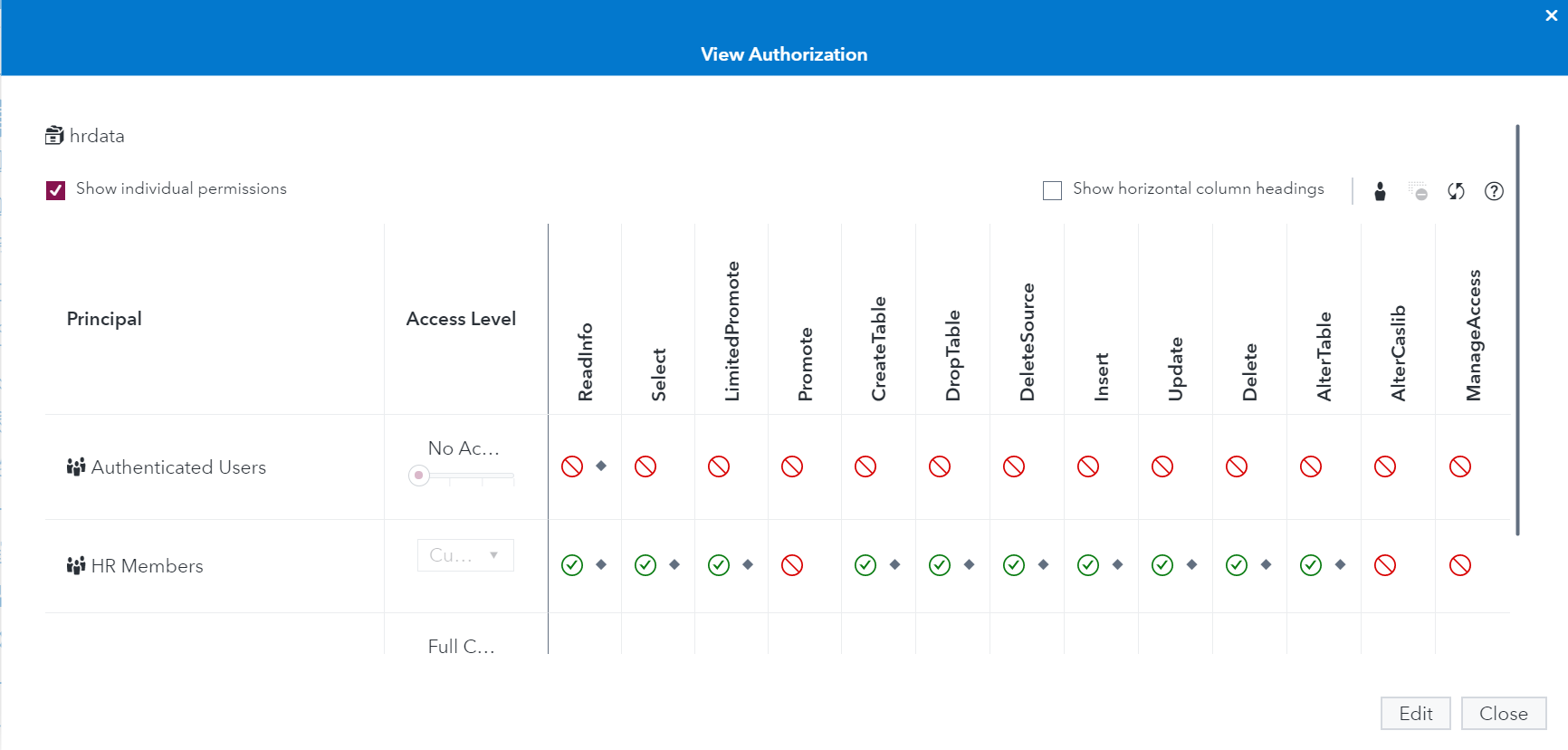
This is me logged in as myself (taflem), a member of the HR line of business group, showing I can view and promote tables from source. In other words, I can see DIABETES.sashdat exists in the Azure File Share I created for HR and I can load it into memory for this caslib.
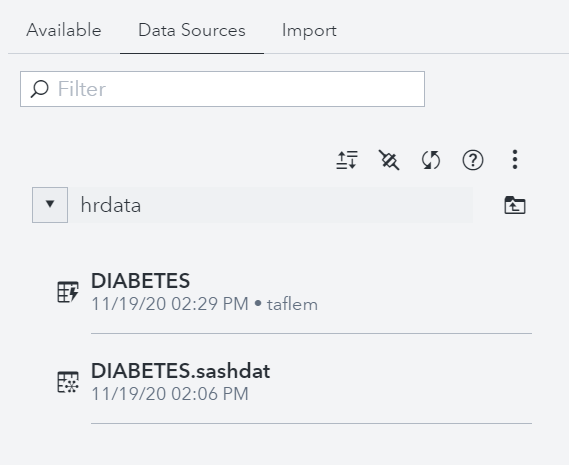
I won't be able to load it into memory associated with any other caslibs that I have access to (the out-of-the-box Public caslib for example) because I (acting as the SAS Admin) don't allow full promote permissions on any caslibs in this environment like you see in the screenshot above. Accomplishing this requires editing the authorizations of all caslibs in your environment and removing (not denying) Full Promote permissions from them. The benefit of doing this consistently is that, for example, users won't be able to take HR data associated with this caslib, which only HR group members have access to, and make it available while it's in memory to any other caslibs which might have wider permissions.
A few more validations… still logged in as myself, I can write back to source and prove the written file maintains the same POSIX permissions (this way of mounting File Shares is like the setgid bit on steroids). I can also validate I can’t do anything with the sister finance caslib, which I set up following the exact same pattern we just walked through for all of the HR Kubernetes objects. This is because I associated that PV with a different LDAP group, just for Finance LOB users, which I'm not a member of.

AND IN CONCLUSION…
I always feel like I do this to myself where I write a really detailed blog post and don’t save energy for a conclusion :). But with this pattern, you can create a group-based security model for path-based data using Azure Files shares. I hope it helps you on your journey to a SAS Viya environment that's well-balanced between security and usability!
As promised, here's a map of these files and which namespace they should get deployed to (click to make it larger and zoom in):
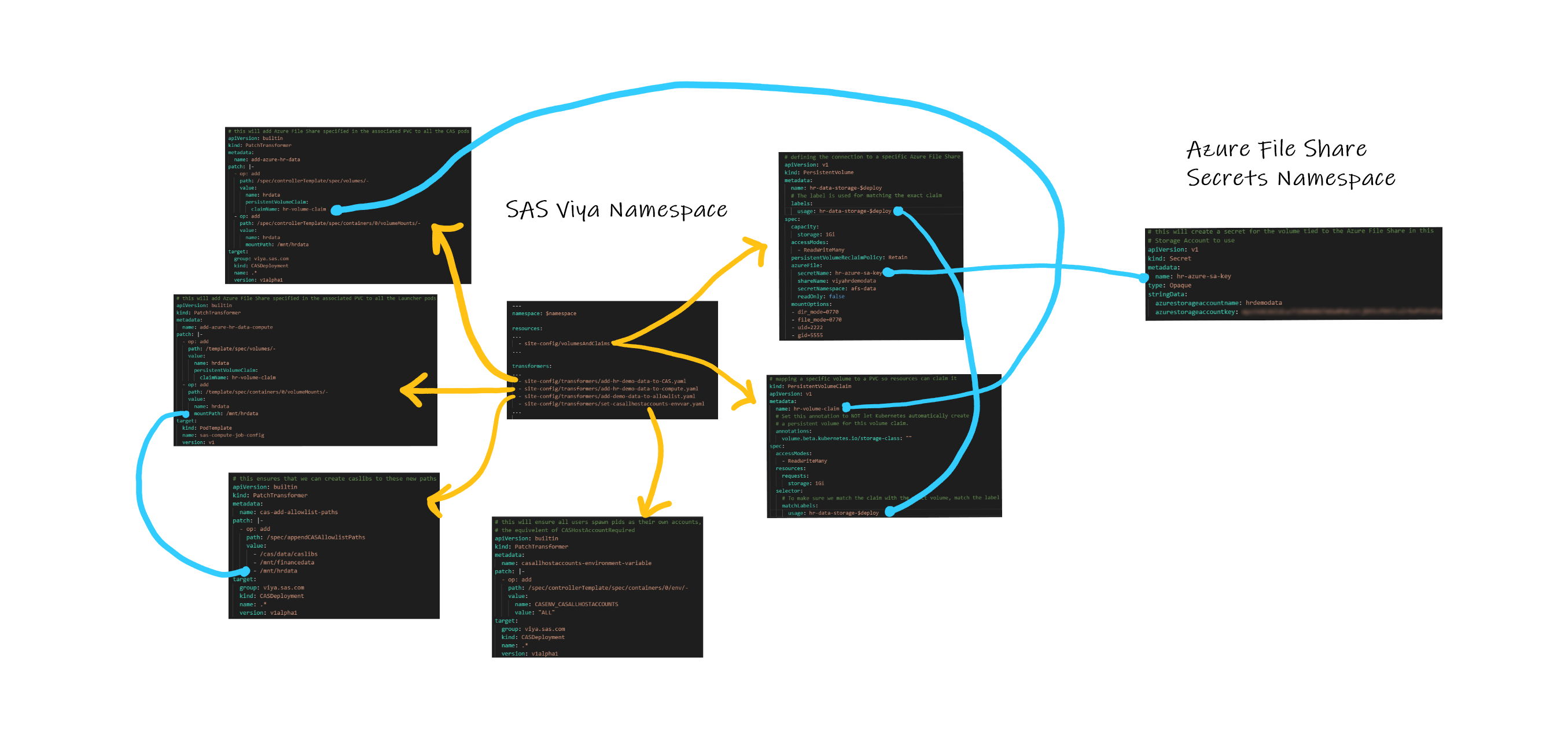

4 Comments
Thanks Tara. Fantastic detail post and very helpful.
Thanks Tara. This was very helpful to me. I followed the steps and was able to configure and use persistent storage in SAS VIYA for one department. I however have three departments. I used the same pattern for the other two departments. The persistent storages were successfully claimed but I am seeing errors when I tied to mount the file shares to the CAS and Computer servers. Any tip, or suggestion on how to mount multiple file shares will be highly appreciated. Again thanks. George
Hey George - I'm not sure exactly what would be causing your errors but in developing this blog post, and for testing before starting the post, I was using two separate File Shares to mock up separate business units and ensure adequate separation of permissions as expected.
Thanks for this Tara - definitely going into my Viya4 Toolbox!