Structuring a highly unstructured data source
Human language is astoundingly complex and diverse. We express ourselves in infinite ways. It can be very difficult to model and extract meaning from both written and spoken language. Usually the most meaningful analysis uses a number of techniques.
 While supervised and unsupervised learning, and specifically deep learning, are widely used for modeling human language, there’s also a need for syntactic and semantic understanding and domain expertise. Natural Language Processing (NLP) is important because it can help to resolve ambiguity and add useful numeric structure to the data for many downstream applications, such as speech recognition or text analytics. Machine learning runs outputs from NLP through data mining and machine learning algorithms to automatically extract key features and relational concepts. Human input from linguistic rules adds to the process, enabling contextual comprehension.
While supervised and unsupervised learning, and specifically deep learning, are widely used for modeling human language, there’s also a need for syntactic and semantic understanding and domain expertise. Natural Language Processing (NLP) is important because it can help to resolve ambiguity and add useful numeric structure to the data for many downstream applications, such as speech recognition or text analytics. Machine learning runs outputs from NLP through data mining and machine learning algorithms to automatically extract key features and relational concepts. Human input from linguistic rules adds to the process, enabling contextual comprehension.
Text analytics provides structure to unstructured data so it can be easily analyzed. In this blog, I would like to focus on two widely used text analytics techniques: information extraction and entity resolution.
Information extraction
Information extraction (IE) automatically extracts structured information from an unstructured or semi-structured text data type -- for example, a text file, to create new structured text data. IE works at the sub-document level, in contrast with techniques such as categorization, that work at the document or record level. Therefore, the results of IE can further feed into other analyses, like predictive modeling or topic identification, as features for those processes. IE can also be used to create a new database of information. One example is the recording of key information about terrorist attacks from a group of news articles on terrorism.
Any given IE task has a defined template, which is a (or a set of) case frame(s) to hold the information contained in a single document. For the terrorism example, a template would have slots corresponding to the perpetrator, victim, and weapon of the terroristic act, and the date on which the event happened. An IE system for this problem is required to “understand” an attack article only enough to find data corresponding to the slots in this template. Such a database can then be used and analyzed through queries and reports about the data.
In their new book, SAS® Text Analytics for Business Applications: Concept Rules for Information Extraction Models, authors Teresa Jade, Biljana Belamaric Wilsey, and Michael Wallis, give some great examples of uses of IE:
"One good use case for IE is for creating a faceted search system. Faceted search allows users to narrow down search results by classifying results by using multiple dimensions, called facets, simultaneously. For example, faceted search may be used when analysts try to determine why and where immigrants may perish. The analysts might want to correlate geographical information with information that describes the causes of the deaths in order to determine what actions to take."
Another good example of using IE in predictive models is analysts at a bank who want to determine why customers close their accounts. They have an active churn model that works fairly well at identifying potential churn, but less well at determining what causes the churn. An IE model could be built to identify different bank policies and offerings, and then track mentions of each during any customer interaction. If a particular policy could be linked to certain churn behavior, then the policy could be modified to reduce the number of lost customers.
Reporting information found as a result of IE can provide deeper insight into trends and uncover details that were buried in the unstructured data. An example of this is an analysis of call center notes at an appliance manufacturing company. The results of IE show a pattern of customer-initiated calls about repairs and breakdowns of a type of refrigerator, and the results highlight particular problems with the doors. This information shows up as a pattern of increasing calls. Because the content of the calls is being analyzed, the company can return to its design team, which can find and remedy the root problem.
Entity resolution and regular expressions
Entity Resolution is the technique of recognizing when two observations relate to the same entity (thing, person, company), despite having been described differently. And conversely, recognizing when two observations do not relate to the same entity, despite having been described similarly. For example, you are listed in one data base as S Roberts, Sian Roberts, S.Roberts. All refer to the same person but would be treated as different people in an analysis unless they are resolved (combined to one person).
Entity resolution can be performed as part of a data pre-processing step or as text analysis. Basically one helps resolve multiple entries (cleans the data) and the other resolves reference to a single entity to extract meaning, for example, pronoun resolution - when “it” refers to a particular company mentioned earlier in the text. Here is another example:
Assume each numbered item is a separate observation in the input data set:
- SAS Institute is a great company. Our company has a recreation center and health care center for employees.
- Our company has won many awards.
- SAS Institute was founded in 1976.
The scoring output matches are below; note that the document ID associated with each match aligns with the number before the input document where the match was found.
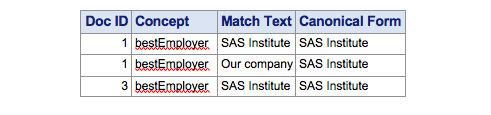
Unstructured data clean-up
In the following section we focus on the pre-processing clean-up of the data. Unstructured data is the most voluminous form of data in the world, and analysts rarely receive it in perfect condition for processing. In other words, textual data needs to be cleaned, transformed, and enhanced before value can be derived from it.
A regular expression is a pattern that the regular expression engine attempts to match in input. In SAS programming, regular expressions are seen as strings of letters and special characters that are recognized by certain built-in SAS functions for the purpose of searching and matching. Combined with other built-in SAS functions and procedures, such as entity resolution, you can realize tremendous capabilities. Matthew Windham, author of Unstructured Data Analysis: Entity Resolution and Regular Expressions in SAS®, gives some great examples of how you might use these techniques to clean your text data in his book. Here we share one of them:
"As you are probably familiar with, data is rarely provided to analysts in a form that is immediately useful. It is frequently necessary to clean, transform, and enhance source data before it can be used—especially textual data."
Extract, Transform, and Load (ETL) ETL is a general set of processes for extracting data from its source, modifying it to fit your end needs, and loading it into a target location that enables you to best use it (e.g., database, data store, data warehouse). We’re going to begin with a fairly basic example to get us started. Suppose we already have a SAS data set of customer addresses that contains some data quality issues. The method of recording the data is unknown to us, but visual inspection has revealed numerous occurrences of duplicative records. In this example, it is clearly the same individual with slightly different representations of the address and encoding for gender. But how do we fix such problems automatically for all of the records?
First Name Last Name DOB Gender Street City State Zip Robert Smith 2/5/1967 M 123 Fourth Street Fairfax, VA 22030 Robert Smith 2/5/1967 Male 123 Fourth St. Fairfax va 22030
Using regular expressions, we can algorithmically standardize abbreviations, remove punctuation, and do much more to ensure that each record is directly comparable. In this case, regular expressions enable us to perform more effective record keeping, which ultimately impacts downstream analysis and reporting. We can easily leverage regular expressions to ensure that each record adheres to institutional standards. We can make each occurrence of Gender either “M/F” or “Male/Female,” make every instance of the Street variable use “Street” or “St.” in the address line, make each City variable include or exclude the comma, and abbreviate State as either all caps or all lowercase. This example is quite simple, but it reveals the power of applying some basic data standardization techniques to data sets. By enforcing these standards across the entire data set, we are then able to properly identify duplicative references within the data set. In addition to making our analysis and reporting less error-prone, we can reduce data storage space and duplicative business activities associated with each record (for example, fewer customer catalogs will be mailed out, thus saving money).
Your unstructured text data is growing daily, and data without analytics is opportunity yet to be realized. Discover the value in your data with text analytics capabilities from SAS. The SAS Platform fosters collaboration by providing a toolbox where best practice pipelines and methods can be shared. SAS also seamlessly integrates with existing systems and open source technology.
Further Resources:
- Natural Language Processing: What it is and why it matters
- White paper: Text Analytics for Executives: What Can Text Analytics Do for Your Organization?
- SAS® Text Analytics for Business Applications: Concept Rules for Information Extraction Models, by Teresa Jade, Biljana Belamaric Wilsey, and Michael Wallis
- Unstructured Data Analysis: Entity Resolution and Regular Expressions in SAS®, by Matthew Windham
