Last year when I went through the SAS Global Forum 2017 paper list, the paper Breaking through the Barriers: Innovative Sampling Techniques for Unstructured Data Analysis impressed me a lot. In this paper, the author raised out the common problems caused by traditional sampling method and proposed four sampling methods for textual data. Recently my team is working on a project in which we are facing a huge volume of documents from a specific field, and we need efforts of linguists and domain experts to analyze the textual data and annotate ground truth, so our first question is which documents we should start working on to get a panoramic image of the data with minimum efforts. Frankly, I don’t have a state-of-the-art method to extract representative documents and measure its effect, so why not try this innovative technique?
The paper proposed four sampling methods, and I only tried the first method through using cluster memberships as a strata. Before we step into details of the SAS program, let me introduce the steps of this method.
- Step 1: Parse textual data into tokens and calculate each term's TF-IDF value
- Step 2: Generate term-by-document matrix
- Step 3: Cluster documents through k-means algorithm
- Step 4: Get top k terms of each cluster
- Step 5: Do stratified sampling by cluster
I wrote a SAS macro for each step so that you are able to check the results step by step. If you are not satisfied with the final cluster result, you can tune the parameters of any step and re-run this step and its post steps. Now let's see how to do this using SAS Viya to extract samples from a movie review data.
The movie review data has 11,855 rows of observations, and there are 200,963 tokens. After removing stop words, there are 18,976 terms. In this example, I set dimension size of the term-by-document matrix as 3000. This means that I use the top 3000 terms with the highest TF-IDF values of the document collections as its dimensions. Then I use k-means clustering to group documents into K clusters, and I set the maximum K as 50 with the kClus action in CAS. The dataSegment action can cluster documents directly, but this action cannot choose the best K. You need to try the clustering action with different K values and choose the best K by yourself. Conversely the kClus action chooses the best K automatically among the K values defined by minimum K and maximum K, so I use kClus action in my implementation.
After running the program (full code at the end of this post), I got 39 clusters and top 10 terms of the first cluster as Table-1 shows.
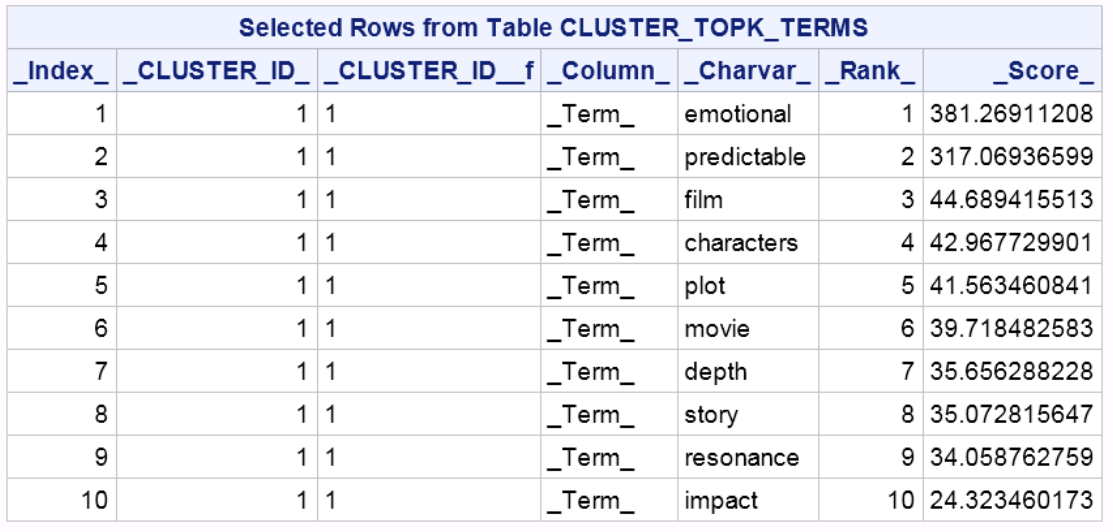
Let's see what samples we get for the first cluster. I got 7 documents and each document either has term "predictable" or term "emotional."

I set sampPct as 5 which means 5% data will be randomly selected from each cluster. Finally I got 582 sample documents. Let's check the sample distribution of each cluster.
This clustering method helped us select a small part of documents from the piles of document collections intelligently, and most importantly it saved us much time and helped us to hit the mark.
I haven't had a chance to try the other three sampling methods from the paper; I encourage you have a try and share your experiences with us. Big thanks to my colleague Murali Pagolu for sharing this innovative technique during the SAS Global Forum 2017 conference and for kindly providing me with some good suggestions.
Appendix: Complete code for text sampling
/*-------------------------------------*/ /* Get tfidf */ /*-------------------------------------*/ %macro getTfidf( dsIn=, docVar=, textVar=, language=, stemming=true, stopList=, dsOut= ); proc cas; textparse.tpParse / docId="&docVar" documents={name="&dsIn"} text="&textVar" language="&language" cellWeight="NONE" stemming=false tagging=false noungroups=false entities="none" offset={name="tpparse_out",replace=TRUE} ; run; textparse.tpAccumulate / offset={name="tpparse_out"} stopList={name="&stopList"} termWeight="NONE" cellWeight="NONE" reduce=1 parent={name="tpAccu_parent",replace=TRUE} terms={name="tpAccu_term",replace=TRUE} showdroppedterms=false ; run; quit; proc cas; loadactionset "fedsql"; execdirect casout={name="doc_term_stat", replace=true} query=" select tpAccu_parent.&docVar, tpAccu_term._term_, tpAccu_parent._count_ as _tf_, tpAccu_term._NumDocs_ from tpAccu_parent left join tpAccu_term on tpAccu_parent._Termnum_=tpAccu_term._Termnum_; " ; run; simple.groupBy / table={name="tpAccu_parent"} inputs={"&docVar"} casout={name="doc_nodup", replace=true}; run; numRows result=r / table={name="doc_nodup"}; totalDocs = r.numrows; run; datastep.runcode / code = " data &dsOut; set doc_term_stat;" ||"_tfidf_ = _tf_*log("||totalDocs||"/_NumDocs_);" ||"run; "; run; quit; proc cas; table.dropTable name="tpparse_out" quiet=true; run; table.dropTable name="tpAccu_parent" quiet=true; run; table.dropTable name="tpAccu_term" quiet=true; run; table.dropTable name="doc_nodup" quiet=true; run; table.dropTable name="doc_term_stat" quiet=true; run; quit; %mend getTfidf; /*-------------------------------------*/ /* Term-by-document matrix */ /*-------------------------------------*/ %macro DocToVectors( dsIn=, docVar=, termVar=, tfVar=, dimSize=500, dsOut= ); proc cas; simple.summary / table={name="&dsIn", groupBy={"&termVar"}} inputs={"&tfVar"} summarySubset={"sum"} casout={name="term_tf_sum", replace=true}; run; simple.topk / table={name="term_tf_sum"} inputs={"&termVar"} topk=&dimSize bottomk=0 raw=True weight="_Sum_" casout={name='termnum_top', replace=true}; run; loadactionset "fedsql"; execdirect casout={name="doc_top_terms", replace=true} query=" select termnum.*, _rank_ from &dsIn termnum, termnum_top where termnum.&termVar=termnum_top._Charvar_ and &tfVar!=0; " ; run; transpose.transpose / table={name="doc_top_terms", groupby={"&docVar"}, computedVars={{name="_name_"}}, computedVarsProgram="_name_='_dim'||strip(_rank_)||'_';"} transpose={"&tfVar"} casOut={name="&dsOut", replace=true}; run; quit; proc cas; table.dropTable name="term_tf_sum" quiet=true; run; table.dropTable name="termnum_top" quiet=true; run; table.dropTable name="termnum_top_misc" quiet=true; run; table.dropTable name="doc_top_terms" quiet=true; run; quit; %mend DocToVectors; /*-------------------------------------*/ /* Cluster documents */ /*-------------------------------------*/ %macro clusterDocs( dsIn=, nClusters=10, seed=12345, dsOut= ); proc cas; /*get the vector variables list*/ columninfo result=collist / table={name="&dsIn"}; ndimen=dim(collist['columninfo']); vector_columns={}; j=1; do i=1 to ndimen; thisColumn = collist['columninfo'][i][1]; if lowcase(substr(thisColumn, 1, 4))='_dim' then do; vector_columns[j]= thisColumn; j=j+1; end; end; run; clustering.kClus / table={name="&dsIn"}, nClusters=&nClusters, init="RAND", seed=&seed, inputs=vector_columns, distance="EUCLIDEAN", printIter=false, impute="MEAN", standardize='STD', output={casOut={name="&dsOut", replace=true}, copyvars="ALL"} ; run; quit; %mend clusterDocs; /*-------------------------------------*/ /* Get top-k words of each cluster */ /*-------------------------------------*/ %macro clusterProfile( termDS=, clusterDS=, docVar=, termVar=, tfVar=, clusterVar=_CLUSTER_ID_, topk=10, dsOut= ); proc cas; loadactionset "fedsql"; execdirect casout={name="cluster_terms",replace=true} query=" select &termDS..*, &clusterVar from &termDS, &clusterDS where &termDS..&docVar = &clusterDS..&docVar; " ; run; simple.summary / table={name="cluster_terms", groupBy={"&clusterVar", "&termVar"}} inputs={"&tfVar"} summarySubset={"sum"} casout={name="cluster_terms_sum", replace=true}; run; simple.topk / table={name="cluster_terms_sum", groupBy={"&clusterVar"}} inputs={"&termVar"} topk=&topk bottomk=0 raw=True weight="_Sum_" casout={name="&dsOut", replace=true}; run; quit; proc cas; table.dropTable name="cluster_terms" quiet=true; run; table.dropTable name="cluster_terms_sum" quiet=true; run; quit; %mend clusterProfile; /*-------------------------------------*/ /* Stratified sampling by cluster */ /*-------------------------------------*/ %macro strSampleByCluster( docDS=, docClusterDS=, docVar=, clusterVar=_CLUSTER_ID_, seed=12345, sampPct=, dsOut= ); proc cas; loadactionset "sampling"; stratified result=r / table={name="&docClusterDS", groupby={"&clusterVar"}} sampPct=&sampPct partind="TRUE" seed=&seed output={casout={name="sampling_out",replace="TRUE"}, copyvars={"&docVar", "&clusterVar"}}; run; print r.STRAFreq; run; loadactionset "fedsql"; execdirect casout={name="&dsOut", replace=true} query=" select docDS.*, &clusterVar from &docDS docDS, sampling_out where docDS.&docVar=sampling_out.&docVar and _PartInd_=1; " ; run; proc cas; table.dropTable name="sampling_out" quiet=true; run; quit; %mend strSampleByCluster; /*-------------------------------------*/ /* Start CAS Server. */ /*-------------------------------------*/ cas casauto host="host.example.com" port=5570; libname sascas1 cas; /*-------------------------------------*/ /* Prepare and load data. */ /*-------------------------------------*/ %let myData=movie_reviews; proc cas; loadtable result=r / importOptions={fileType="csv", delimiter='TAB',getnames="true"} path="data/movie_reviews.txt" casLib="CASUSER" casout={name="&myData", replace="true"} ; run; quit; /* Browse the data */ proc cas; columninfo / table={name="&myData"}; fetch / table = {name="&myData"}; run; quit; /* generate one unique index using data step */ proc cas; datastep.runcode / code = " data &myData; set &myData; rename id = _document_; keep id text score; run; "; run; quit; /* create stop list*/ data sascas1.stopList; set sashelp.engstop; run; /* Get tfidf by term by document */ %getTfidf( dsIn=&myData, docVar=_document_, textVar=text, language=english, stemming=true, stopList=stopList, dsOut=doc_term_tfidf ); /* document-term matrix */ %DocToVectors( dsIn=doc_term_tfidf, docVar=_document_, termVar=_term_, tfVar=_tfidf_, dimSize=2500, dsOut=doc_vectors ); /* Cluster documents */ %clusterDocs( dsIn=doc_vectors, nClusters=10, seed=12345, dsOut=doc_clusters ); /* Get top-k words of each cluster */ %clusterProfile( termDS=doc_term_tfidf, clusterDS=doc_clusters, docVar=_document_, termVar=_term_, tfVar=_tfidf_, clusterVar=_cluster_id_, topk=10, dsOut=cluster_topk_terms ); /* Browse topk terms of the first cluster */ proc cas; fetch / table={name="cluster_topk_terms", where="_cluster_id_=1"}; run; quit; /* Stratified sampling by cluster */ %strSampleByCluster( docDS=&myData, docClusterDS=doc_clusters, docVar=_document_, clusterVar=_cluster_id_, seed=12345, sampPct=5, dsOut=doc_sample_by_cls ); /* Browse sample documents of the first cluster */ proc cas; fetch / table={name="doc_sample_by_cls", where="_cluster_id_=1"}; run; quit; |
