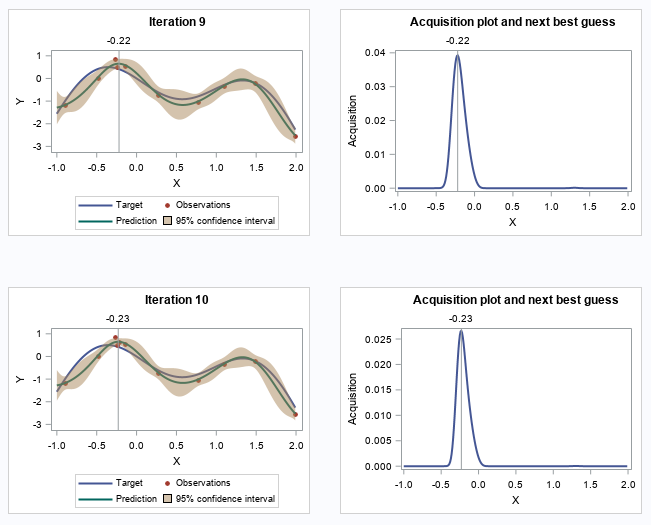
Bayesian optimization in SAS

Learn how Bayesian optimization works through a simple demo.

Learn how Bayesian optimization works through a simple demo.
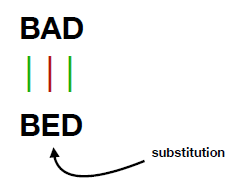
Dynamic programming is a powerful technique to implement algorithms, and is often used to solve complex computational problems. This article shows how to use PROC FCMP to implement the "edit distance" algorithm.
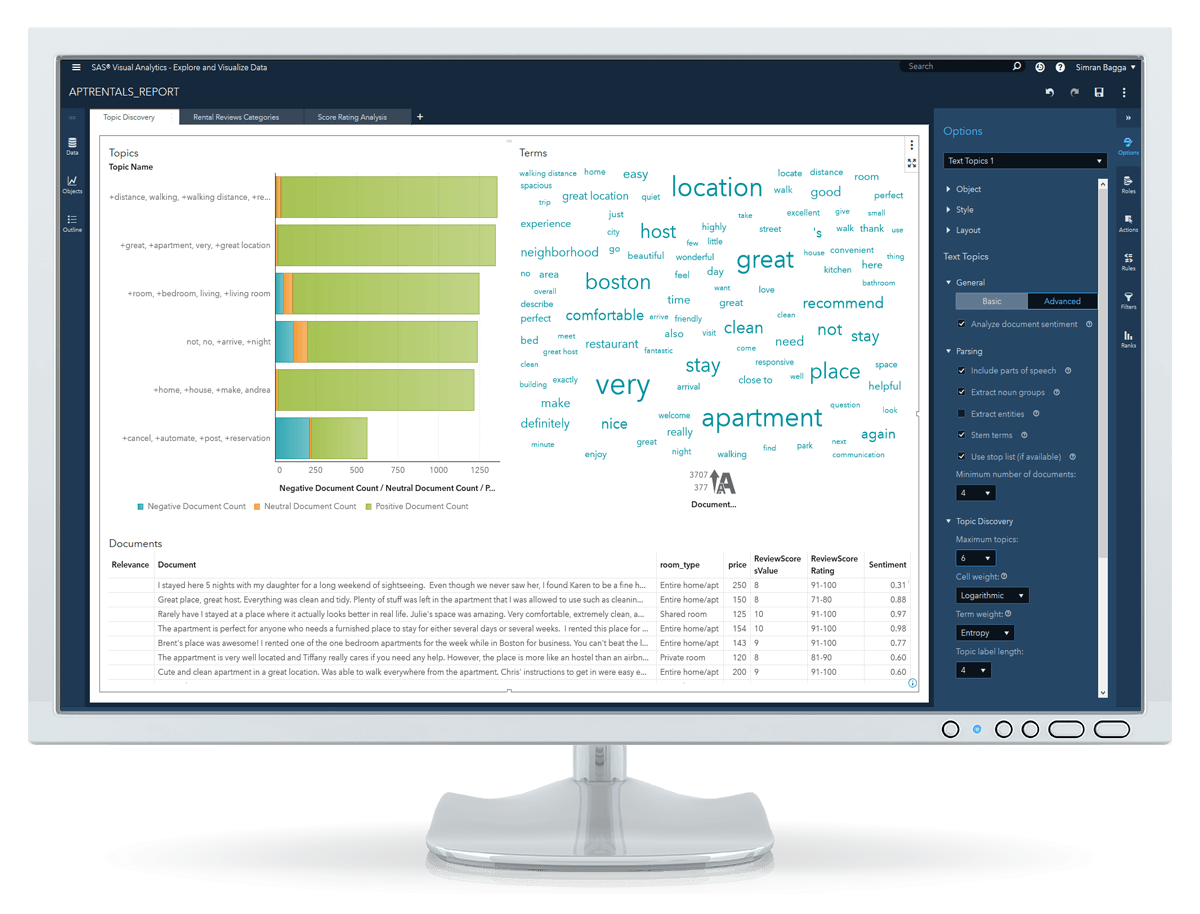
SAS Visual Analytics includes text parsing actions that can help tokenize sentences, and SAS Visual Text Analytics provides even better, more sophisticated methods. This article contains code samples and cites papers for more details.