Once upon a Time
 Once upon a time, Oliver S. Füßling merely occupied a line in a SAS® program. But one day, he lost his last name, and a quest began to help our hero find the rest of his name.
Once upon a time, Oliver S. Füßling merely occupied a line in a SAS® program. But one day, he lost his last name, and a quest began to help our hero find the rest of his name.
Our Story Begins
The SAS Training Center wanted to re-create course data for the "Introduction to Programming 1" class. The updated class uses SAS® Studio, a new programming environment that incorporates a UTF-8 SAS session encoding. However, the course data sets contained national language characters, which are not available on an English keyboard. As a result, depending on how those programs were submitted in the new environment, they experienced the following transcoding problems:
- character substitution
- data truncation
- invalid-data errors
Like the Training Center, you might encounter similar transcoding issues if you have programs that:
- contain national language characters
- are created in the WLatin-1 SAS session encoding
- you move to a UTF-8 SAS session encoding.
This story explains how you can move such programs successfully to a UTF-8 environment and avoid substitution characters, data truncation, and invalid-data errors.
The programs in the "Introduction to Programming 1" class were originally submitted via an earlier English edition of the SAS® Foundation. However, the sample program in this story is created in SAS® 9.4 (English).
When the program is opened in the Enhanced Editor window, this is how a shortened version of the program looks:
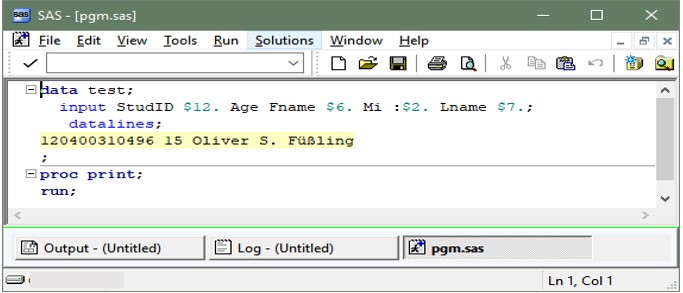
Note: If you would like a copy of this program for your own testing, see the Epilogue heading at the end of this post.
In SAS 9.4 (English) for the Windows environment, the default session encoding is WLatin-1. You can see the encoding in the log by running either of the following sets of statements:
- PROC OPTIONS OPTION=ENCODING;
RUN; - %PUT ENCODING= %SYSFUNC(getOption(ENCODING));
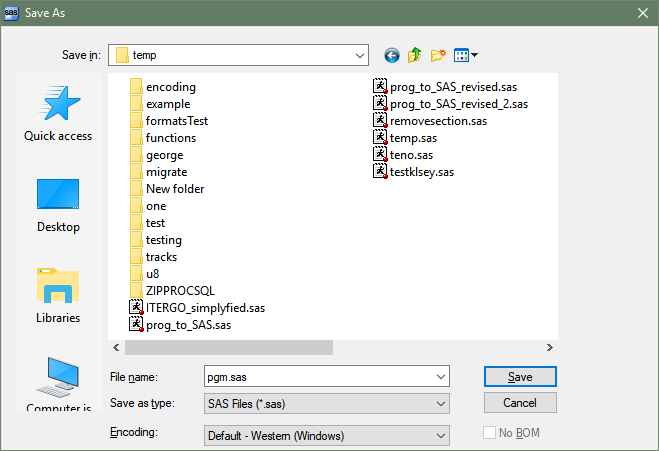
When programs are saved from the Enhanced Editor window, the encoding for the program file defaults to Default - Western (Windows), as shown below.
When the program file that is shown earlier, which contains the name Oliver S. Füßling, is uploaded and included into the SAS Studio code editor, Oliver's last name displays replacement characters rather than the expected national language characters.
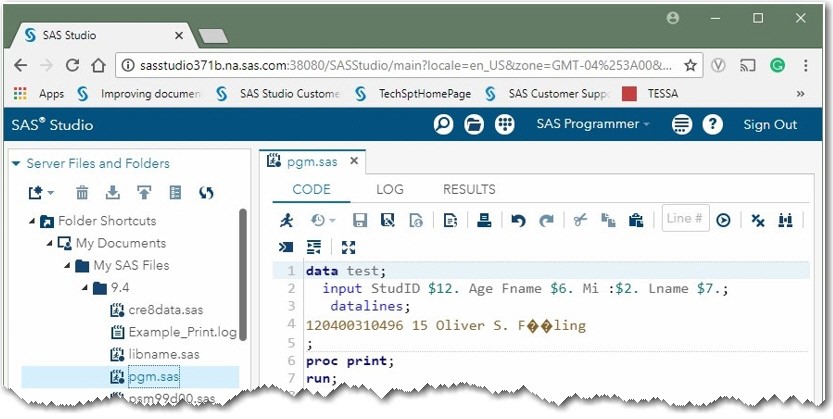
Note: This display shows SAS Studio open in a Google Chrome browser. In this browser, you see two characters (diamonds with white question marks) that are substituted for the national language characters. If you use SAS Studio in Microsoft Internet Explorer, the display shows only one diamond, and it truncates the remainder of the name.
To begin resolving the display problem, you need to look at the code-editor status bar (bottom of the window).
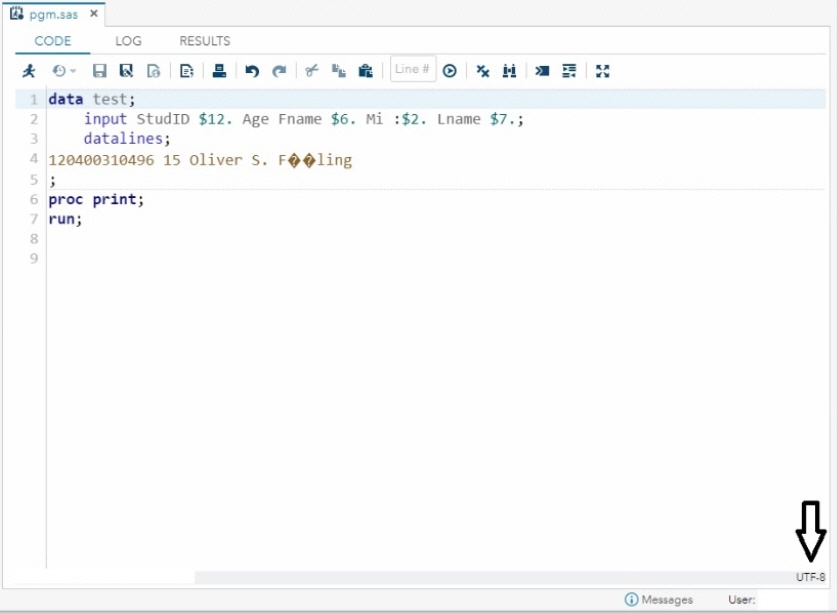
Notice that there is a text-encoding setting that informs SAS Studio of the encoding of the external file. That setting is shown to the right on the status bar. In the display above, that encoding is UTF-8.
Be aware that this text-encoding setting differs from the UTF-8 SAS session encoding that is displayed by the SAS ENCODING system option, which is generated in the log when you run the OPTIONS procedure. In SAS Studio, the default text encoding is UTF-8, regardless of the session encoding. Because the pgm.sas program was saved originally from the Enhanced Editor in the default Western-Windows encoding, it is not in the encoding that the SAS Studio code editor expects.
To fix the display issue, you can use either of the following options:
Option 1
1. Right-click the program file and select Open with text encoding.
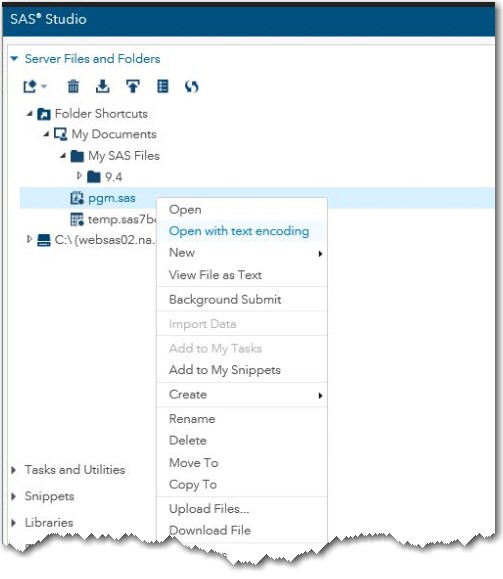
2. In the Select Text Encoding dialog box, select the windows-1252 encoding value from the Navigation Pane menu.
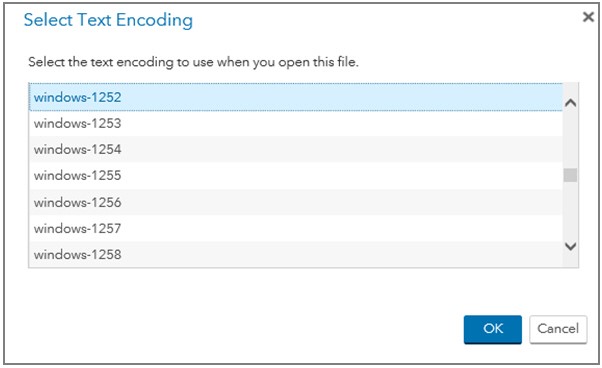
The Windows code page 1252 represents the character set that is used by Western European languages, including English, in Microsoft Windows operating environments. The WLatin-1 encoding is the SAS equivalent for the 1252 Windows code page.[1]
3. Click OK to save your selection before you exit the dialog box.
Option 2
From the General tab in the Preferences dialog box, select a value for the default text encoding.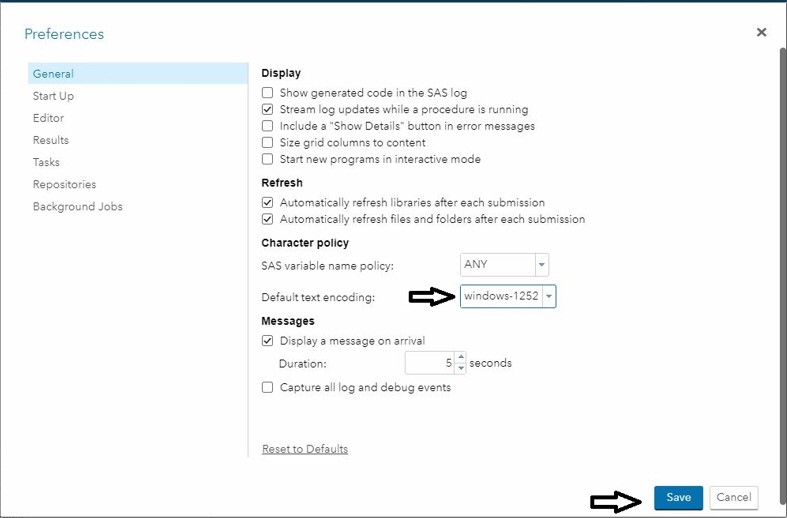
When you set the value in this way, the change is not reflected immediately in the existing code- editor window. You must close the program and re-open it for the setting to take effect. Any programs that you open later will retain the same setting unless you change the setting or override it by selecting another value in the Select Text Encoding dialog box.
Oliver's last name is displayed correctly in the code editor when you use the windows-1252 setting to open the file, as shown below:
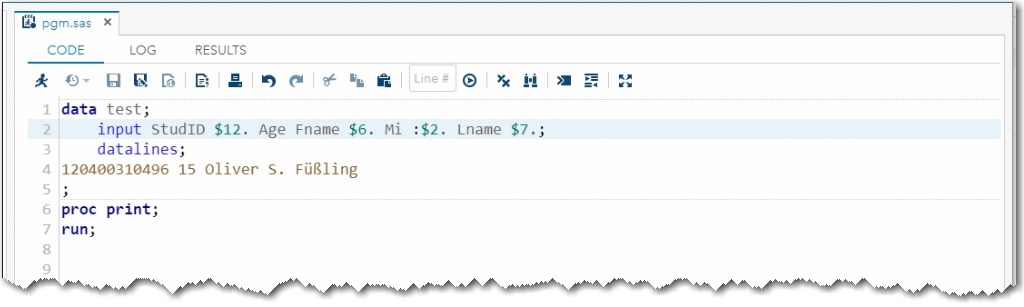
However, Oliver's last name is truncated on the HTML Results tab when you submit the program.

The Plot Thickens
Although the problem is fixed in the code editor when you submit the program, Oliver's last name is truncated as Füßli in the output. However, you do not receive any notes or warnings in the log about that truncation. So, why does the truncation happen? The ü (U-umlaut) and the ß (German Eszett) are stored as single-byte characters (SBCS) in WLatin-1, but those characters require two bytes in UTF-8. As a result, there is not adequate space to print the remaining characters in the name.
When you submit programs that contain national language characters from a single-byte encoding to a UTF-8 environment, you must be prepared to modify the program to use wider informats when you create your variables. Otherwise, character truncation can occur.
You can correct this problem easily by enlarging the column to accommodate the extra bytes that are used to store the characters in UTF-8.
Here is the modified INPUT statement that successfully reads the data in a UTF-8 SAS session. The character informat for the Lname variable is increased from $7. to $9.
input StudID $12. Age Fname $6. Mi :$2. Lname $9.; |
After you increase the informat, Oliver's last name is correct when you view it on the HTML Results tab.

A Subplot Appears
What if the program file is included and executed by using the %INCLUDE statement rather than by submitting it from the code editor?
In this situation, the program stops processing with the following errors:
NOTE: The data set WORK.TEST has 1 observations and 5 variables. NOTE: DATA statement used (Total process time): real time 0.00 seconds cpu time 0.00 seconds ERROR: Invalid characters were present in the data. ERROR: An error occurred while processing text data. NOTE: The SAS System stopped processing this step because of errors. NOTE: There were 1 observations read from the data set WORK.TEST. |
In this case, the HTML Results tab does not display a last name at all.

To eliminate this error, you need to use the ENCODING= option in the %INCLUDE statement, as shown below.
%include "your-directory/pgm.sas" /encoding="windows-1252"; |
By including the ENCODING="windows-1252" option in the %INCLUDE statement, the program now executes successfully, as shown by the notes in the log:
NOTE: The data set WORK.TEST has 1 observations and 5 variables. NOTE: DATA statement used (Total process time): real time 0.01 seconds cpu time 0.01 seconds NOTE: There were 1 observations read from the data set WORK.TEST. |
Happily Ever After (or, The End)!
The moral of this story is that there are many ways to avoid transcoding problems when you have national language characters in SAS programs that you save from a SAS®9 (English) session and move to a UTF-8 environment. Hopefully, you can use the tips that are provided to avoid such issues. However, if you still have problems, you can call on another hero, SAS Technical Support, for help!
Epilogue
The following program is the one used throughout this story. You can copy and paste it for your own use.
data test; input StudID $12. Age Fname $6. Mi :$2. Lname $7.; datalines; 120400310496 15 Oliver S. Füβling ; proc print; run; |
Additional Resources
- Bouedo, Mickaël. 2012. "Write Once, Run Anywhere! How to Make Your SAS® Applications Speak Many Languages." Proceedings of the SAS Global Forum 2012 Conference. Cary, NC: SAS Institute Inc.
- Carlton, Jody. 2017. SAS blog: "Demystifying and resolving common transcoding problems." Cary, NC: SAS Institute Inc.
- Kiefer, Manfred. 2012. SAS® Encoding: Understanding the Details. Cary, NC: SAS Institute Inc.
- Lawhorn, Bari. 2014. SAS blog: "Encoding: helping SAS® speak your language." Cary, NC: SAS Institute Inc.
- SAS Institute Inc. 2013. "Multilingual Computing with SAS® 9.4." Cary, NC: SAS Institute Inc.
- SAS Institute Inc. 2018. SAS® 9.4 National Language Support (NLS): Reference Guide, Fifth Edition. Cary, NC: SAS Institute Inc.
Notes
[1] If you do not know the encoding for your source file and you see replacement characters, try opening your file using a different value that is consistent with the default environment encoding and the locale of the SAS session in which the file was created. For a table that lists common encoding methods, their corresponding encodings, and their aliases, see Encodings and Their Aliases and Encoding Character Set Compatibility in SAS® 9.4 National Language Support (NLS): Reference Guide, Fifth Edition.

5 Comments
Thanks for this Jody! This is an awesome description of all the things that users have to be aware of when working with data for other languages. For students in Programming 1, Programming 2 and other classes where we use a program to make data, our e-learning developers have changed the data creation file to eliminate this issue. In newer versions of the courses, Oliver S. Füβling, becomes Oliver S. Fuszling and other characters like o-umlaut (ö), a-umlaut (ä), u-umlaut (ü), etc were changed in the program to avoid the issue. The transcoding issue doesn't always happen in SAS Studio, sometimes it also occurs in Enterprise Guide, as well, which doesn't have the same features as Studio.
Cynthia
Thank you for this info, Cynthia!
Most software systems now use UTF-8 as the standard character encoding and have done for some time. The Wlatin-1 encoding is very limiting, even in Europe (no Polish characters, for example). I am migrating everything to UTF-8.
.
SAS needs to make this easier. The fixed-width text variables must expand to four times their previous size to allow for the very rare 4-byte characters. Disk usage explodes. Is a new dataset file format planned? Databases have had international varchars for a long time. How about an option which makes UTF-8 the default for everything so we do not have to change all the code, the lengths and so on?
.
I also have a case open with tech support which I am almost certain is related to UTF-8 issues with the ODBC engine.
Your post is a must-read for any user of SAS Studio dealing with extended ascii character sets like the Latin-1 etc. (iso 8859-1 etc.) : almost mandatory reading ! Should I suggest you cross-post the article to the SAS community forums as well, this might reach many more non-english SAS users ;).
Another way still to change the default encoding of SAS Studio editor is to modify the 'webdms.defaultEncoding' parameter :
http://documentation.sas.com/?docsetId=webeditorag&docsetTarget=p1ghk2x06a9nknn0zwtf39hzcddw.htm&docsetVersion=3.6&locale=en
This modification does not persist when the SAS Studio web applicaton is being rebuilt, in contrast to the user's preference settings (now my personal favourite ).
Ronan, thank you for the suggestion to share on Communities and to Bari for taking the time to post! You will find it here: https://communities.sas.com/t5/SAS-Studio/SAS-Studio-transcoding-or-encoding-concerns/td-p/475315. A site might find 'webdms.defaultEncoding' in config.properties a useful method for setting text encoding for all users. Thanks for mentioning it!