As SAS Viya has been gaining awareness over the past year among SAS users, there has been a lot of discussion about how SAS’ Cloud Analytic Server (CAS) handles memory vs SAS’ previous technologies such as LASR and HPA. Recently, while I was involved in delivering several SAS Viya enablement sessions, I realised that many, including myself, held an incorrect understanding of how this works, mainly around one particular CAS option called maxTableMem.
The maxTableMem option determines the memory block size that is used per table, per CAS Worker, before converting data to memory-mapped memory. It is not intended to directly control how much data is put into memory vs how much is put into CAS_DISK_CACHE, but rather it indirectly influences this.
Let’s unpack that a bit and try to understand what it really means.
The CAS Controller doesn’t care what the value of maxTableMem is. In a serial load example, the CAS Controller distributes the data evenly across the CAS Workers[1], which then fill up maxTableMem-sized buckets (memory blocks), emptying them (converting them to memory-mapped memory) as they fill up, only leaving non-full buckets of table data. You should almost never change the default setting of this option (16MB), except perhaps in cases of extremely large tables, in order to reduce the number of file handles (up to 256MB is probably sufficient in these cases).
CAS takes advantage of standard memory mapping techniques for the CAS_DISK_CACHE, and leaves the optimisation of it up to the OS. With SASHDAT files and LASR in SAS 9.4, the SASHDAT file essentially acts as a pre-paged file, written in a memory-mapped format, so the table data in memory doesn’t need to be written to disk when it is paged out. Should a table need to be dropped from memory to make room for other data, and subsequently needed to be read back in to memory, it would be paged in from the SASHDAT file.
With CAS, the CAS_DISK_CACHE allows us to extend this pre-paged file approach to all data sources, not just SASHDAT. Traditional OS swap files are written to each time memory is paged out, however with CAS, regardless of the data source (SASHDAT, database, client-uploaded file etc.) most table memory will never need to be written to disk, as it will already exist in the backing store (this could be CAS_DISK_CACHE, HDFS or NFS). Although data will be continually paged in and out of memory, the amount of writing to disk will be minimised, which is typically slower than reading data from disk.
Another advantage of the CAS_DISK_CACHE is that when data does need to be written to disk it can happen upfront when the server is less busy, rather than at the last moment when the system detects it is out of memory (pre-paging rather than demand-paging). Once it is written, it can be paged back into memory multiple times, by multiple concurrent processes. The CAS_DISK_CACHE also spreads the I/O across multiple devices and servers as opposed to a typical OS swap file that may only write to a single file on a single server.
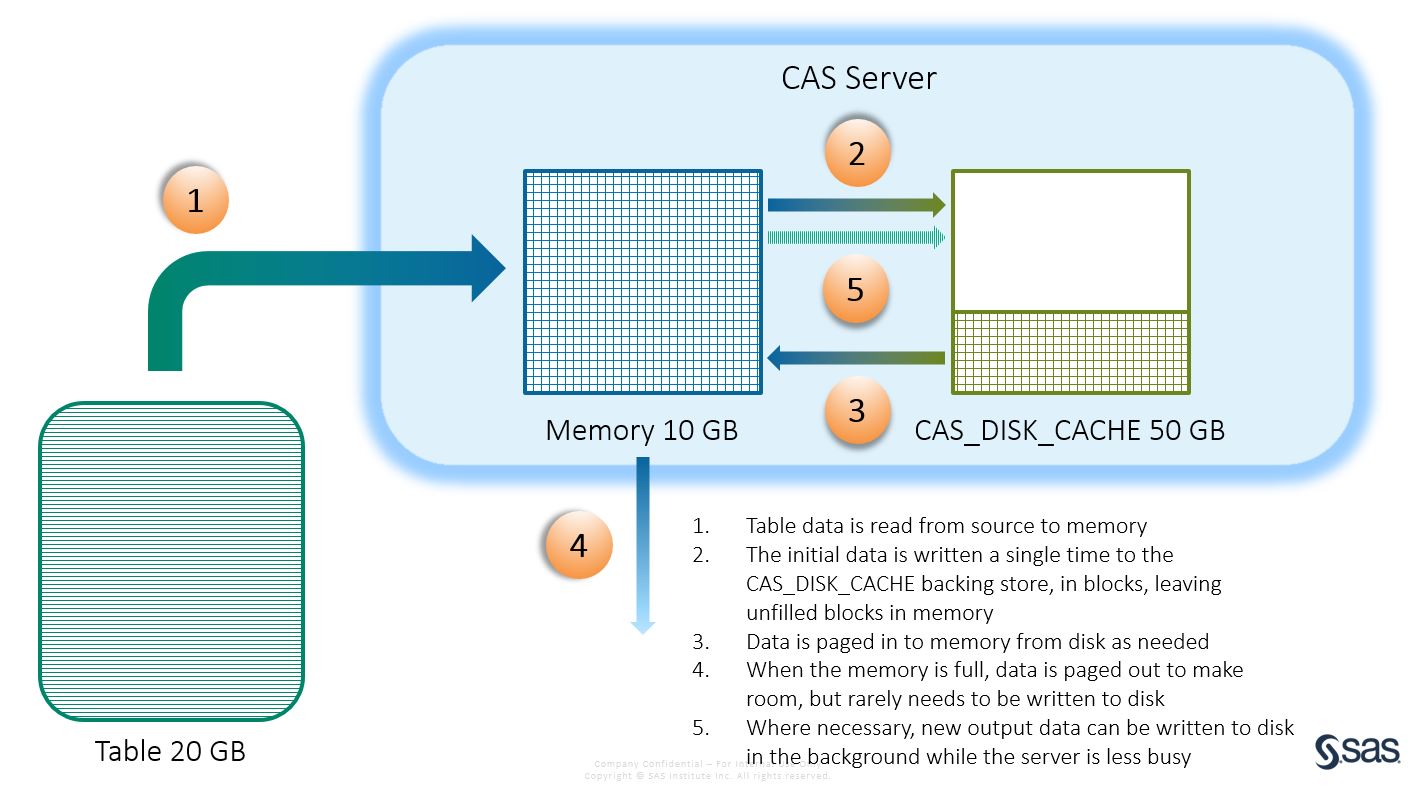
While CAS supports exceeding memory capacity by using CAS_DISK_CACHE as a backing store, read/write disk operations do have a performance cost. Therefore, for best performance, we recommend you have enough memory capacity to hold your most commonly used tables, meaning most of the time the entire table will be both in memory and the backing store.
If you expect to regularly exceed memory capacity, and therefore are frequently paging data in from CAS_DISK_CACHE, consider spreading the CAS_DISK_CACHE location across multiple devices and using newer solid state storage technologies in order to improve performance.[2]
Additionally, when you need CAS to peacefully co-exist with other applications that are sharing resources on the same nodes, standard Linux cgroup settings along with Hadoop YARN configuration can be utilised to control the resources that CAS sessions can exploit.
References
How SAS Cloud Analytic Services Uses Memory
Notes
[1] There are exceptions to data being evenly distributed across the CAS Workers. The main one is if the data is partitioned and the partitions are of different sizes – all the data of a partition must be on the same node therefore resulting in an uneven distribution. Also, if a table is very small, it may end up on only a single node, and when CAS is co-located with Hadoop the data is loaded locally from each node, so CAS receives whatever the distribution of data is that Hadoop provides.
[2] A comprehensive analysis of all possible storage combinations and the impact on performance has not yet been completed by SAS.
