In 2011, Loughran and McDonald applied a general sentiment word list to accounting and finance topics, and this led to a high rate of misclassification. They found that about three-fourths of the negative words in the Harvard IV TagNeg dictionary of negative words are typically not negative in a financial context. For example, words like “mine”, “cancer”, “tire” or “capital” are often used to refer to a specific industry segment. These words are not predictive of the tone of documents or of financial news and simply add noise to the measurement of sentiment and attenuate its predictive value. So, it is not recommended to use any general sentiment dictionary as is.
Extracting domain-specific sentiment lexicons in the traditional way is time-consuming and often requires domain expertise. Today, I will show you how to extract a domain-specific sentiment lexicon from movie reviews through a machine learning method and construct SAS sentiment rules with the extracted lexicon to improve sentiment classification performance. I did the experiment with the help from my colleagues Meilan Ji and Teresa Jade, and our experiment with the Stanford Large Movie Review Dataset showed around 8% increase in the overall accuracy with the extracted lexicon. Our experiment also showed that the lexicon coverage and accuracy could be improved a lot with more training data.
SAS Sentiment Analysis Studio released domain-independent Taxonomy Rules for 12 languages and domain-specific Taxonomy Rules for a few languages. For English, SAS has covered 12 domains, including Automotive, Banking, Health and Life Sciences, Hospitalities, Insurance, Telecommunications, Public Policy Countries and others. If the domain of your corpus is not covered by these industry rules, your first choice is to use general rules, which sometimes lead to poor classification performance, as Loughran and McDonald found. Automatically extracting domain-specific sentiment lexicons has been studied by researchers and three methods were proposed. The first method is to create a domain-specific word list by linguistic experts or domain experts, which may be expensive or time-consuming. The second method is to derive non-English lexicons based on English lexicons and other linguistic resources such as WordNet. The last method is to leverage machine learning to learn lexicons from a domain-specific corpus. This article will show you the third method.
Because of the emergence of social media, researchers are able to relatively easily get sentiment data from the internet to do experiments. Dr. Saif Mohammad, a researcher in Computational Linguistics, National Research Council Canada, proposed a method to automatically extract sentiment lexicons from tweets. His method provided the best results in SemEval13 by leveraging emoticons in large tweets, using the PMI (pointwise mutual information) between words and tweet sentiment to define the sentiment attributes of words. It is a simple method, but quite powerful. At the ACL 2016 conference, one paper introduced how to use neural networks to learn sentiment scores, and in this paper I found the following simplified formula to calculate a sentiment score.
Given a set of tweets with their labels, the sentiment score (SS) for a word w was computed as:
SS(w) = PMI(w, pos) − PMI(w, neg), (1)
where pos represents the positive label and neg represents the negative label. PMI stands for pointwise mutual information, which is
PMI(w, pos) = log2((freq(w, pos) * N) / (freq(w) * freq(pos))), (2)
Here freq(w, pos) is the number of times the word w occurs in positive tweets, freq(w) is the total frequency of word w in the corpus, freq(pos) is the total number of words in positive tweets, and N is the total number of words in the corpus. PMI(w, neg) is calculated in a similar way. Thus, Equation 1 is equal to:
SS(w) = log2((freq(w, pos) * freq(neg)) / (freq(w, neg) * freq(pos))), (3)
The movie review data I used was downloaded from Stanford; it is a collection of 50,000 reviews from IMDB. I used 25,000 reviews in train and test datasets respectively. The constructed dataset contains an even number of positive and negative reviews. I used SAS Text Mining to parse the reviews into tokens and wrote a SAS program to calculate sentiment scores.
In my experiment, I used the train dataset to extract sentiment lexicons and the test dataset to evaluate sentiment classification performance with each sentiment score cutoff value from 0 to 2 with increment of 0.25. Data-driven learning methods frequently have an overfitting problem, and I used test data to filter out all weak-predictive words whose absolute value of sentiment scores are less than 0.75. In Figure-1, there is an obvious drop in the accuracy line plot of test data when the cutoff value is less than 0.75.
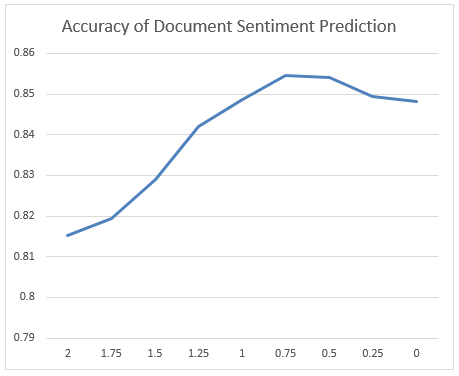
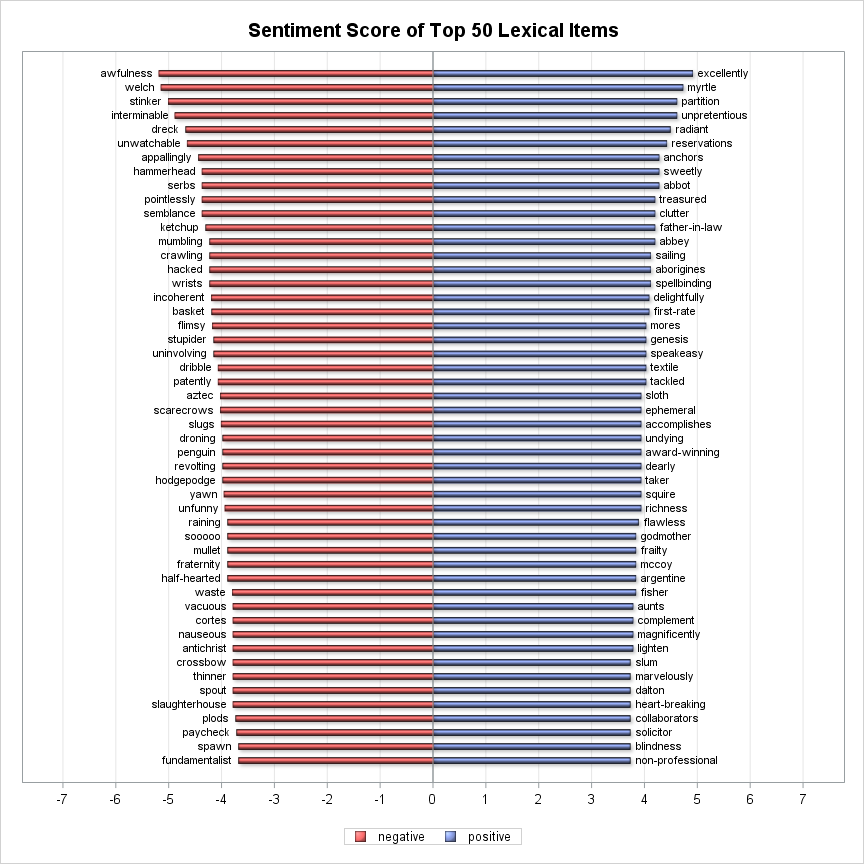
Finally, I got a huge list of 14,397 affective words; 7,850 positive words and 6,547 negative words from movie reviews. The top 50 lexical items from each sentiment category as Figure-2 shows.
Now I have automatically derived the sentiment lexicon, but how accurate is this lexicon and how to evaluate the accuracy? I googled movie vocabulary and got two lists from Useful Adjectives for Describing Movies and Words for Movies & TV with 329 adjectives categorized into positive and negative. 279 adjectives have vector data in the GloVe word embedding model downloaded from http://nlp.stanford.edu/projects/glove/ and the T-SNE plot as Figure-3 shows. GloVe is an unsupervised learning algorithm for obtaining vector representations for words. Training is performed on aggregated global word-word co-occurrence statistics from a corpus. T-SNE is a machine learning algorithm for dimensionality reduction developed by Geoffrey Hinton and Laurens van der Maaten.[1] It is a nonlinear dimensionality reduction technique that is particularly well-suited for embedding high-dimensional data into a space of two or three dimensions, which can then be visualized in a scatter plot. So two words are co-located or located closely in the scatter plot, if their semantic meanings are close or their co-occurrence in same contexts is high. Besides semantic closeness, I also showed sentiment polarity via different colors. Red stands for negative and blue stands for positive.
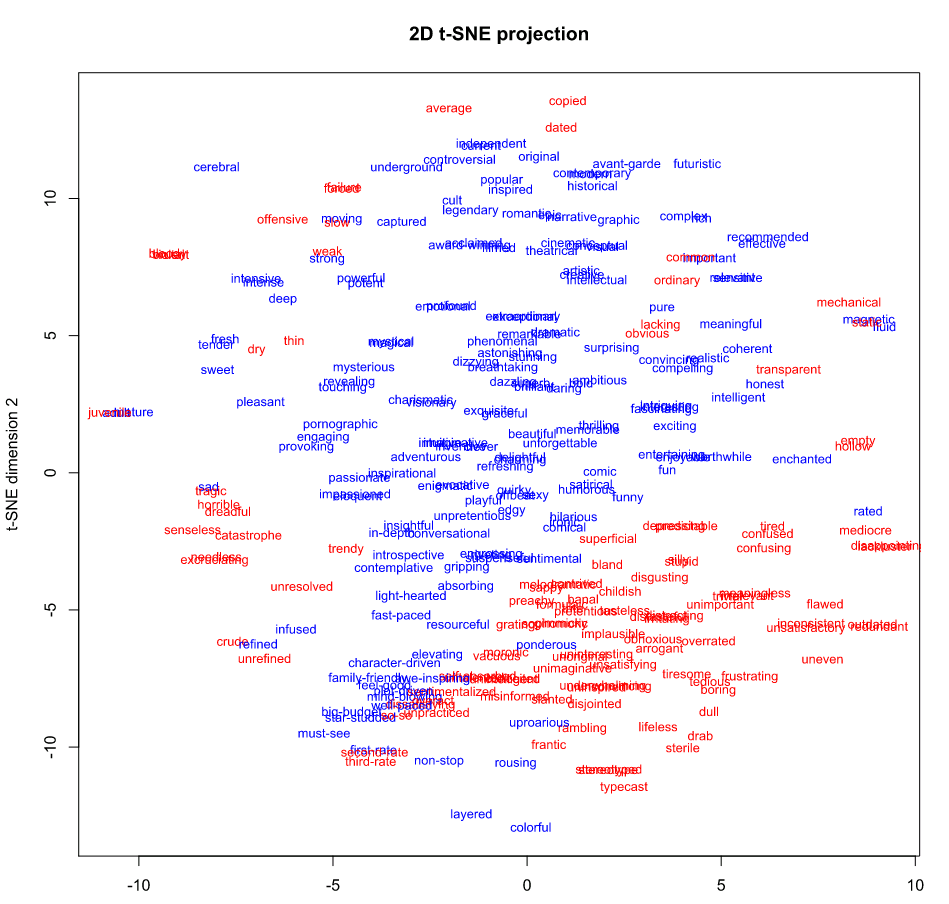
From Figure-3, I find the positive vocabulary and the negative vocabulary are clearly separated into two big clusters, with very little overlap in the plot.
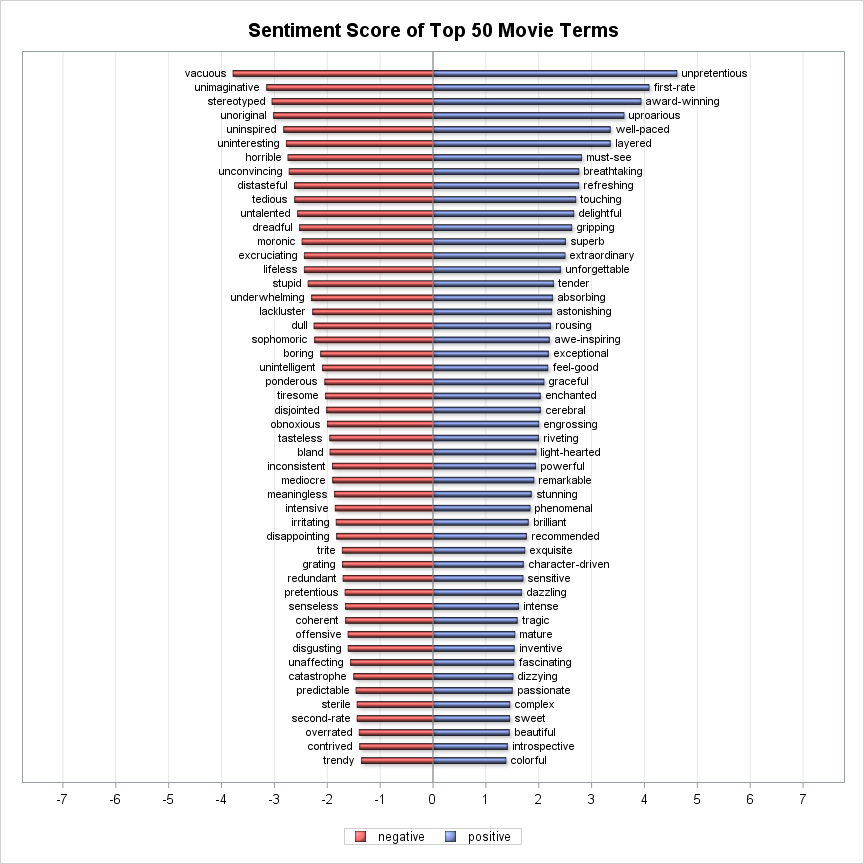
Now, let me check the sentiment scores of the terms. 175 of them were included in my result and Figure-4 displays the top 50 terms of each category. I compared sentiment polarity of my result with the list, 168 of 175 terms are correctly labelled as negative or positive and the overall accuracy is 96%.
There are 7 polarity differences between my prediction and the list as the Table-1 shows.
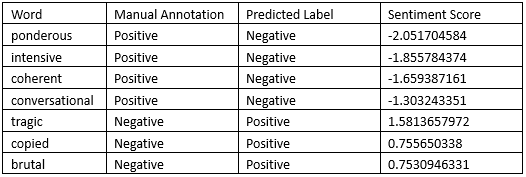
One obvious prediction mistake is coherent. I checked the raw movie reviews that contain “coherent”, and only 25 of 103 reviews are positive. This is why its sentiment score is negative rather than positive. I went through these reviews and found most of them had a sentiment polarity reversal, such as “The Plot - Even for a Seagal film, the plot is just stupid. I mean it’s not just bad, it’s barely coherent. …” A possible solution to make the sentiment scores more accurate is to use more data or add a special manipulation for polarity reversals. I tried first method, and it did improve the accuracy significantly.
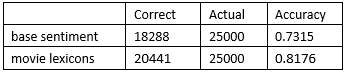
So far, I have evaluated the sentiment scores’ accuracy with public linguistic resources and next I will test the prediction effect with SAS Sentiment Analysis Studio. I ran sentiment analysis against the test data with the domain-independent sentiment rules developed by SAS and the domain-specific sentiment rules constructed by machine learning, and compared the performance of two methods. The results showed an 8% increase in the overall accuracy. Table-2 and Table-3 show the detailed information.
Test data (25,000 docs)

After you get domain-specific sentiment lexicons from your corpora, only a few steps are required in SAS Sentiment Analysis Studio to construct the domain-specific sentiment rules. So, next time you are processing domain-specific text for sentiment, you may want to try this method to get a listing of terms that are positive or negative polarity to augment your SAS domain-independent model.
Detailed steps to construct domain-specific sentiment rules as follows.
Step 1. Create a new Sentiment Analysis project.
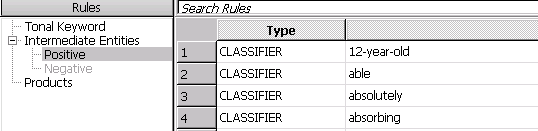
Step 2. Create intermediate entities named “Positive” and “Negative”, then put the learned lexicons to the two entities respectively.
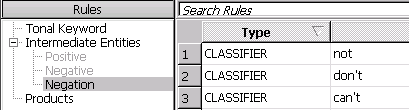
Step 3. Besides the learned lexicons, you may add an entity named “Negation” to handle the negated expressions. You can list some negations you are familiar with, such as “not, don’t, can’t” etc.
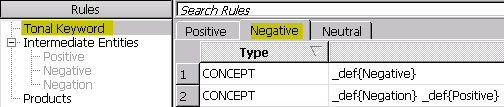
Step 4. Create positive and negative rules in the Tonal Keyword. Add the rule “CONCEPT: _def{Positive}” to Positive tab, and the rule “CONCEPT: _def{Negative}” and “CONCEPT: _def{Negation} _def{Positive}” to Negative tab.
Step 5. Build rule-based model, and now, you can use this model to predict the sentiment of documents.
