Is your LASR implementation running short on memory? Since LASR tables are stored in memory, it can become scarce. So what can we do to minimize LASR table size and still get LASR’s legendary performance? Here are a few strategies on how to shrink LASR tables:
Compression: When compression was first introduced, many people thought it would be the best and only solution for reducing LASR table sizes. However it is actually just one of many approaches. While LASR compression can reduce tables sizes dramatically (94% in a test I did on the MegaCorp sample table), it can affect performance. Compression is easily implemented, so it should be the first strategy you try.
Pivoting: Pivoting transforms rows into columns to save space. See the example below for reference:  Even in this simple example, we were able to cut the number table cells in half (from 12 to 6). However space savings from pivoting can be even more dramatic than that. Imagine pivoting by a simple DIRECTION field (East, West, North, South), This would cut the number of rows by three fourths (75%) since all of the direction amounts would now be stored in a single row. Now imagine privoting by mutliple fields and you can see how cut tables down by 90% or more.Pivoting changes the structure of the table so analysis logic will need to change. However, as an analytic engine, LASR likes wide data. This combined with the reduced table size means that pivoting actually increases LASR performance.
Even in this simple example, we were able to cut the number table cells in half (from 12 to 6). However space savings from pivoting can be even more dramatic than that. Imagine pivoting by a simple DIRECTION field (East, West, North, South), This would cut the number of rows by three fourths (75%) since all of the direction amounts would now be stored in a single row. Now imagine privoting by mutliple fields and you can see how cut tables down by 90% or more.Pivoting changes the structure of the table so analysis logic will need to change. However, as an analytic engine, LASR likes wide data. This combined with the reduced table size means that pivoting actually increases LASR performance.
Star Schema Views: LASR Star Schema Views are implemented similarly to other data management system’s star schemas and offer the same benefits. While Star Schema views carry a modest performance impact, space savings can be dramatic (70%+) if you have many low cardinality categorical fields that can be moved to dimension tables.
Computed Columns: LASR Computed Columns / Calculated Data Items are non-materialized columns defined by expressions. They take up no memory for storage. As compared to a materialized version of the same column, they save 100% of the column space. Computed columns incur no performance penalty and should be used in place of ETL where possible. Some computed column examples are shown below. Note that both numeric and character columns are supported along with conditional logic via SAS DATA Step If-Then-Else syntax.
proc imstat nopreparse;
table lasr1.mega_corp;
compute productName "productname=scan(productdescription,1)";
compute NetProfit "netprofit=Profit - ExpensesStaffing";
compute UnitConditn "if unitlifespan > unitage then unitconditn='Past
Due'; else unitconditn='Good';";
quit;
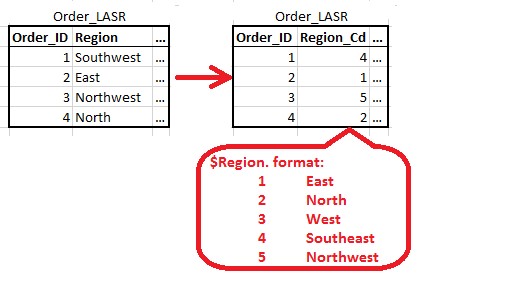
Custom Formats: Custom formats had some performance problems in early releases. Those performance problems are gone now and custom formats can be used to save space by replacing long categorical variables with short formatted code fields. A graphic below shows a 9+ character REGION field beig replaced by a formatted one character Region_Cd field. This saves 8+ bytes per row.
SASHDAT Memory Mapping: SASHDAT memory mapping extends LASR memory by mapping SASHDAT blocks to virtual memory where the OS can swap them in and out of RAM as necessary. This allows for better memory utilization and a more dynamic environment since tables that aren’t being used will be moved out of memory in favor of tables that are being accessed.

3 Comments
Thanks for this useful article.
Thanks for the useful article. You mentioned that star schema is good for low cardinality categorical fields. How about high cardinality?
Typical enterprise star schema cardinality is in the 100-10000 range. Would the performance be severely impacted?
If you have an extremely high cardinality column (say it has as many unique values as the fact table has rows) then splitting it out into a dimension table doesn't buy you anything. It will repeat on the dimension table as much as it would have repeated on the fact table. A better approach for a high cardinality column is a custom format.