This week I'm going to share one of my favorite tips and tricks from my book, Unstructured Data Analysis: Entity Resolution and Regular Expressions in SAS®. If you work with unstructured data, you’ll want a copy of my easy-to-understand guide to entity resolution analytics on your shelf.
This week I'm going to share one of my favorite tips and tricks from my book, Unstructured Data Analysis: Entity Resolution and Regular Expressions in SAS®. If you work with unstructured data, you’ll want a copy of my easy-to-understand guide to entity resolution analytics on your shelf.
The following excerpt explains how to use the SAS procedure PROC HTTP to grab raw data from a website.
It is often the case that we want to leverage publicly available, unstructured, or text data sources for analysis. So, I’m going to show you one way to easily grab data off of a website using PROC HTTP.
PROC HTTP is just one of several methods for acquiring data outside of the local file system or database. And it is an easy method for integration into Base SAS code. I will not go through all the different powerful options available in PROC HTTP. Please refer to the documentation for more details on all the additional ways to use PROC HTTP.
In the below code, I start with a null DATA step to create a macro variable named FileRef that contains a dynamic file reference. Whenever we are extracting from text sources, it is a best practice to ensure the date of extraction is maintained. I have chosen to do this by embedding the extraction date in the file name that I created for the resulting file. Next, the FILENAME statement uses this macro variable to establish the file reference, Source. And finally, I use Source in PROC HTTP as the output file, using OUT=. Note the URL= statement identifies a link to the BBC News feed (The BBC allows all forms of reuse of their content so long as they are properly referenced.).
/*NULL DATA STEP to generate the macro variable with a dynamic file name.*/
data _NULL_;
call symput('FileRef',"'C:\Users\mawind\Documents\SASBook\Examples\CorpNews"||put(Date(),date9.)||".txt'");
run;
filename source &fileref;
/*Execution of PROC HTTP to extract from a web URL, and write to the file designated above.*/
proc http
url="http://feeds.bbci.co.uk/news/technology/rss.xml"
out=source;
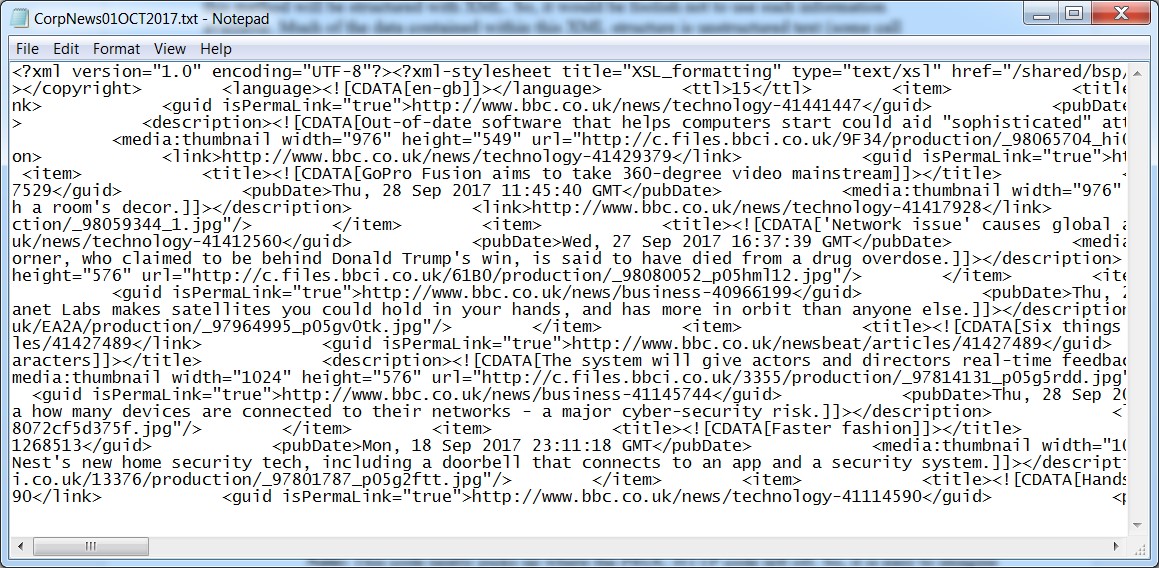
run;After the code runs, you will get a raw text file containing all of the XML content from the source (Figure 1).
Figure 1: Sample of TXT from BBC News RSS Feed
Depending on how the host (BBC News, in this case) decides to maintain that information, your refresh and indexing of it will vary. Luckily, in our example, we can use the <pubdate> tag embedded in the XML to help us track when each headline was published.
Note: You are not constrained to XML when using PROC HTTP. It is merely how a source that I'm allowed to reprint stores data. So, feel free to experiment with pages that don't use XML.
But much of the data contained within webpage XML files is unstructured text (some call this “semi-structured” data). Therefore, you want to be prepared for how to approach entirely unstructured text data—a much more voluminous portion of potential sources.
If you enjoyed this excerpt, you can purchase the book in epub, mobi, or PDF formats through the SAS bookstore and check out all of the other great titles published by SAS Press.