 What?!? You mean a period (.) isn't the only SAS numeric missing value? Well, there are 27 others: .A .B, to .Z and ._ (period underscore). Your first question might be: "Why would you need more than one missing value?" One situation where multiple missing values are useful involves survey data. Suppose you want to distinguish between "did not answer" and "not applicable?" You could use two different missing values to keep track of each category of missing data. In calculating statistics such as means and stand deviations, all of these missing values are treated the same way as missing values. However, you can keep track of the various categories of missing values in procedures such as PROC FREQ. Here is an example:
What?!? You mean a period (.) isn't the only SAS numeric missing value? Well, there are 27 others: .A .B, to .Z and ._ (period underscore). Your first question might be: "Why would you need more than one missing value?" One situation where multiple missing values are useful involves survey data. Suppose you want to distinguish between "did not answer" and "not applicable?" You could use two different missing values to keep track of each category of missing data. In calculating statistics such as means and stand deviations, all of these missing values are treated the same way as missing values. However, you can keep track of the various categories of missing values in procedures such as PROC FREQ. Here is an example:
You have survey data and you have used codes of 999 for "did not answer" and 888 for "was not applicable." You want to see frequencies on both categories of missing data. Here is some code you could use:
proc format; value response .A = 'Did not answer' .B = 'Was not applicable'; run; data Survey; input ID $ Q1-Q5; array Q[5]; do i = 1 to 5; if Q[i] = 999 then Q[i] = .A; else if Q[i] = 888 then Q[i] = .B; end; drop i; format Q1-Q5 response.; datalines; 001 888 2 4 3 2 002 999 4 3 2 1 003 1 2 888 5 5 004 2 999 888 999 3 ; title "Frequency Data"; proc freq data=Survey; tables Q1-Q5 / nocum nopercent missing; run; |
Notice that you can format the values .A and .B to correspond to the two categories of missing values. In the DATA step, you assign .A to values of 999 and .B to values of 888. Finally, you use the TABLES option MISSING so that the missing values appear in the main table. Here is a portion of the output:
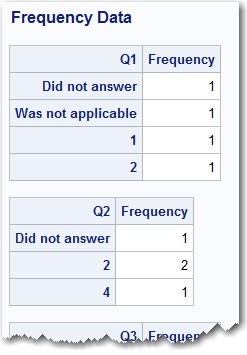
More about these missing values is discussed in my book Learning SAS by Example.
Maybe you can think of other uses for using the extra 27 numeric missing values.





5 Comments
I've used different missing values when trying to debug a program. There were half a dozen places (say) where a particular variable was given its value (or its value modified) and then it was tested to see if it was missing. If it was then it was given a .D (unable to Derive). The dataset was checked for .Ds at the end and then we would fix whatever the problem was.
But on this occasion I couldn't work out which part (or parts) of the (labyrinthine) program were generating the .Ds. So instead I allocated different letters to each part. When I checked the resulting dataset I could then see which parts were generating them, and focus on it. From memory there was one particular section responsible for all but one. I should add that before the variable was modified at each stage it was first tested that it wasn't already missing - if it was then that section would be skipped.
By the way, IF VAR=.D will only return true for .D. But IF MISSING(VAR) will return true regardless of what type of missing value you are using is. Both methods can be useful.
Three special missing values have particular prominence in ODS tables. They appear in template TRANSLATE statements.
translate _val_ = ._ into ' ';
translate _val_ = .I into ' Infty';
translate _val_ = .M into ' -Infty',
When there is no value to display (such as the bottom right corner of an ANOVA table), the procedure outputs ._, which is translated into blank.
For extremely large values (for example, when the denominator approaches zero) the procedure outputs .I and .M. .I is translated to "Infty", and .M is translated into "-Infty".
Hi Ron,
Thank you for highlighting this very useful feature.
I would add that these "special missing" values are case-insensitive, in other words .A is equal to .a .
One of the examples of using the special missing values is presented in my blog post Automatic data suppression in SAS reports,
where I use them in to distinguish missing counts of a cross-tabulation shown as zeros vs. suppressed numbers shown as * ,e.g.
proc format;
value cntf
.S = '*'
. = '0'
other = [comma18.0]
;
run;
Ron, I experimented with special missing values once for a paper on SORTing. I discovered that "._" was the lowest value, then came ".", then came .A-.Z in that order.
Haven't actually applied this information to any project work yet, though.
Andrew, ._ and character _ play special roles when used with the UPDATE statement.