Os algoritmos de mineração de dados podem ser divididos em 4 grupos, a saber: aprendizado supervisionado, aprendizado não-supervisionado, aprendizado semissupervisionado e aprendizado por reforço. Embora os dois primeiros sejam vastamente conhecidos e implementados, os dois últimos não possuem a mesma popularidade. Mas, como veremos a seguir, isso não se deve ao fato de terem aplicação limitada. E, não sendo muito mais complexos que os demais, devem experimentar um crescimento no interesse pelos cientistas de dados.
Este artigo aborda os aspectos que envolvem o uso de do aprendizado semissupervisionado, um conjunto de técnicas analíticas que visa prever o valor de determinado evento (y) a partir de informações disponíveis (x). Enquanto no aprendizado supervisionado todas as observações possuem uma marcação (rótulo) do valor de interesse (y), e no aprendizado não-supervisionado essa marcação é inexistente, no aprendizado semissupervisionado essa marcação está presente em apenas uma parcela dos dados (em geral, na minoria), estando as demais desmarcadas. As ponderações aqui apresentadas se baseiam nos trabalhos de Chapelle, Scholkopf & Zien,(2006); Van Engelen, & Hoos, (2020) e Zhu, C. (2007).
Por que e onde utilizá-lo
Com o avanço tecnológico, a coleta de informações relativas a um determinado evento é relativamente fácil. Contudo, quando se trata de predizer o valor de determinado evento y, é provável que esta informação crucial não esteja acessível, ou, ao menos, não para a totalidade dos dados. Então por que não buscar marcar na base de dados essa informação faltante? Em alguns cenários, a marcação do rótulo do evento que se deseja prever exige custos elevados, que não se justificam haja vista a disponibilidade de técnicas alternativas.
Alguns exemplos em que a marcação dos dados implica em custos financeiros ou operacionais elevados:
- Na identificação de fraude, quando a quantidade de processos que precisam ser fiscalizados excede a capacidade dos auditores e apenas uma amostra dos dados é marcada quanto à presença de fraude, e as demais, seguem sem rótulo.
- No reconhecimento de discurso, uma vez que o custo de gravação é baixo, mas rotulá-lo requer que algum ser humano o ouça e transcreva.
- Classificação de páginas da web as quais podem ser obtidas automaticamente, mas que necessitam de uma leitura humana para marcação do conteúdo.
Um dos motivos que leva à hesitação quanto ao uso dos métodos semissupervisionados é a incerteza de ganho na acurácia dos modelos quando se usa dados não-rotulados em relação ao uso de aprendizagem supervisionada, filtrando apenas as observações rotuladas. De fato, essa questão precisa ser avaliada, especialmente se os métodos supervisionados lograrem bons resultados. Caso contrário, a inserção da aprendizagem semissupervisionada pode promover a melhora da performance dos modelos, desde que os dados não-rotulados contenham informações relevantes para estimar o valor que se deseja prever, e que os pressupostos descritos a seguir sejam observados.
Quais pressupostos
Para o uso dos algoritmos semissupervisionados, alguns pressupostos são esperados:
- Suposição de Suavidade: Se dois pontos são próximos um do outro (possuem características semelhantes), então é provável que eles tenham as mesmas marcações.
- Suposição do Cluster: Se os pontos estiverem no mesmo cluster, provavelmente serão da mesma classe.
- Suposição de Baixa densidade: O limite de separação das classes deve passar por áreas de baixa densidade no espaço de entrada.
- Suposição de Manifold: Os dados estão, aproximadamente, em uma subestrutura de dimensão menor do que a dimensão do espaço de entrada. Essas subestruturas são conhecidas como Manifold.
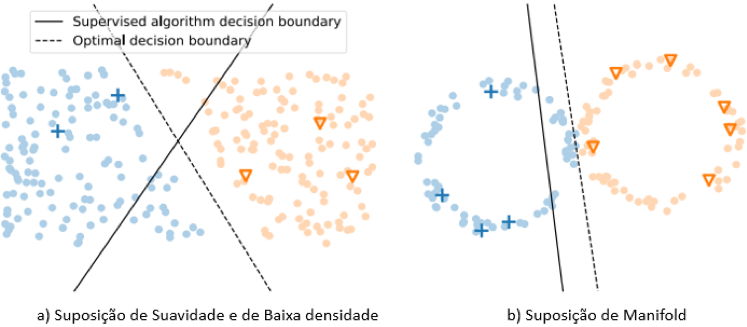
Quais as principais abordagens
-
Self-Training
Consiste em um algoritmo supervisionado que é treinado primeiramente apenas nos dados rotulados, mas que, a partir do output do modelo, é retreinado de maneira iterativa usando dados pré-rotulados e dados que tenham sido pseudorrotulados em iterações anteriores do algoritmo. Assim o autotreinamento usa as próprias previsões para adicionar um rótulo aos dados não marcados. Para isso, define-se um nível de confiança acima do qual acredita-se na previsão e a adiciona ao dado não marcado. Esse processo continua treinando o modelo até que não haja mais previsões acima do nível confiança a serem adicionadas. A maior falha é que o método é incapaz de corrigir seus próprios erros, o que pode gerar previsões que deterioram o modelo a cada iteração.
-
Multi-view Co-Training
O cotreinamento faz uso de múltiplos algoritmos supervisionados sendo que cada um treina separadamente sobre uma diferente “visão” dos dados (diferentes conjuntos de variáveis correlacionadas). Assim, dois ou mais classificadores supervisionados são treinados iterativamente nos dados rotulados, adicionando suas previsões mais confiáveis para o conjunto de dados não-rotulados dos outros algoritmos (com outras visões) em cada iteração. Assim, há uma espécie de troca de rótulos de dados não marcados entre os algoritmos de maneira iterativa, partindo de diferentes “pontos de vista”. É importante que cada “visão” seja suficiente para obter boas previsões, e que as visões sejam independentes do rótulo da classe (assim as previsões dos algoritmos individuais não são fortemente correlacionadas).
-
Generative methods
Os métodos generativos visam identificar a probabilidade, p(x,y), de uma observação x possuir um determinado rótulo y. Conhecendo o parâmetro p(x), torna-se necessário identificar a distribuição da função de probabilidade condicional p(x|y), a qual é uma mistura identificável de k distribuições. Dessa forma, é possível obter a probabilidade conjunta p(x,y) dada por p(x|y) x p(y). Para grandes amostras, todas as distribuições podem ser identificadas, sendo necessária a existência de pontos rotulados em cada classe y para executar tal tarefa. Assim, identificada a distribuição na parcela marcada dos dados é possível utilizar essa informação na marcação dos dados não rotulados.
-
Transdutivo SVM (S3VMs)
O Transductive Support Vector Machines (TSVMs) assume uma relação geométrica entre os valores de x e p(y) em todos os pontos para construir uma estrutura no plano com base na margem dos hiperplanos. A margem de um hiperplano a distância mínima entre o limite de decisão e os pontos de dados mais próximos dele. O objetivo do TSVM é encontrar uma borda de decisão que maximize a margem, encorajando os pontos de dados a serem classificados corretamente, enquanto minimiza o número de pontos de dados não-rotulados que violam a margem. Os dados não-rotulados de diferentes classes são separados por uma grande margem, e aqueles que se encontram dentro da margem são penalizados com base em sua distância até o limite da margem mais próxima.
-
Graph-based methods
Os métodos baseados em grafos visam estimar o rótulo de dados não marcados a partir da informação contida nos seus vizinhos (similares). Para tanto, um grafo é construído no qual os nós representam pontos de dados (rotulados e não-rotulados) que estão conectados uns aos outros por meio de arestas que representam algumas medidas de similaridade entre eles e que variam de espessura conforme similitude. Assim, a informação do rótulo contida em um ponto de dado é propagada para sua amostra vizinha até que a estabilidade global seja alcançada no conjunto de dados completo. A forma geral de funções objetivo contém um componente para penalizar rótulos previstos que não correspondem ao rótulo verdadeiro, e outro para penalizar diferenças nas previsões de rótulos para pontos conectados.
Assim, conforme exposto, a aprendizagem semissupervisionada mostra-se uma alternativa eficiente para classificação de eventos, permitindo o aproveitamento de toda informação disponível ainda que a totalidade dos dados não tenha sido rotulada.
