Diversas urgencias laborales y personales hicieron que dejara de escribir este blog con mis humildes opiniones y aportes técnicos.
Superadas las mismas, aquí estoy de regreso. No les diré que muuuuuuchos seguidores al estilo de Wos pidieron a gritos mi regreso, pero he de decirles que ante mi sorpresa varias personas del mercado informático me preguntaron por qué no seguía escribiendo.
Ya que mencioné a Wos (tremendo cantautor rapero) les cuento que, vueltas de la vida de por medio, lo conocí en la panza de su mamá. Y su aparición me resultó de una utilidad inesperada; puso en evidencia que los millennials ya están jovatos. Para mi sobrino de 10 años y sus amigos, Wos es un ídolo total; mis compañeros millennials… ¡¡¡ no lo conocen !!!.
Para concretar este regreso les contaré que la publicación neuronaBA ha publicado una nota mía titulada "Big Data (y un poco de Mineria de Datos e Inteligencia Artificial)… En un intento de explicación como para que no se duerma".
Por motivos de espacio editorial la dividieron en dos partes y redujeron un poco su tamaño. Realmente lo han hecho muy bien, sin desfigurar su contenido. Pero quisiera en este regreso compartir con Uds. su versión completa.
Big Data (y un poco de Mineria de Datos e Inteligencia Artificial)… En un intento de explicación como para que no se duerma.
Conversaciones en empresas, revistas tecnológicas y no tanto, artículos periodísticos generales, astrólogos, coaches ontológicos, homeópatas, todo el mundo habla de "La Big Data" y "La Inteligencia Artificial". Tal vez el tema le resulte novedoso, sorprendente o le tenga harte (harto en lenguaje inclusivo). Si trabaja en alguna empresa habrá escuchado discutir si "tenemos que ir a la Big Data".
Pero… exactamente… ¿Qué es?
Si buscó en la Web habrá encontrado algunas decenas de explicaciones; tal vez no pueda decidir con cual quedarse. Bueno… aquí va la mía para agregar a su confusión.
Big Data es la capacidad de procesar en paralelo enormes volúmenes de información, de modo tal de poder analizar con mucho detalle el comportamiento de mis: clientes, ciudadanos, proveedores, productos, transacciones, etc, etc, etc.
¿Y para que sirve analizar enormes volúmenes de información?. Para conocer / saber / prever cuestiones tan dispares como:
- ¿Qué clientes están más propensos a aceptar mi nueva oferta de telefonía celular?.
- ¿Qué personas están cometiendo fraude o lavando dinero?.
- ¿En qué lugares debo proveer mayor cantidad de patrulleros?. ¿Mayor cantidad de ambulancias?.
- ¿Qué personas tienen mayor probabilidad de entrar en mora con mi compañía o de abandonarnos como clientes?.
- ¿Esta tomografía muestra un órgano sano o enfermo?.
Dicho de otro modo, analizamos los comportamientos anteriores de muchos casos conocidos para predecir el comportamiento de los casos futuros (obviamente desconocidos).
La pregunta es… ¿Por qué ahora sí y antes no?
MI respuesta es… porque ahora se puede y antes no se podía.
Recorramos juntos el camino…
Hace 40 años cuando comencé a trabajar en el Banco Credicoop, el mainframe IBM 370 Modelo 138 en el que se procesaban las operaciones de los clientes (socios según la concepción cooperativa) tenía 512 KB de memoria. Su valor de compra rondaba los 400.000 dólares.
Por ese dinero hoy puede adquirir (estimativamente) computadores con una capacidad de memoria ¡¡¡ 20 millones de veces mayor !!! (10 Terabytes, enseguida le explico).
(Nota para colegas de tecnología de la información: Si aplica la ley de Moore, verá que se cumple con buena aproximación).
Pero… ¿Cuál es el significado real de aquellos KB y estos TB de memoria?
Le cuento que para que los procesadores de su máquina puedan procesar la información, ésta tiene que estar almacenada en la memoria, que la capacidad de la memoria se mide en bytes y que (simplificando la explicación por razones de espacio) una letra o un número ocupan 1 byte.
Esta memoria tiene la buena característica de ser muy rápida, se la accede en pocas decenas de nanosegundos (un nanosegundo es un segundo dividido en 1000 millones) pero tiene la mala costumbre de borrarse cuando apagamos el computador. Entonces la información se guarda en discos que son más lentos (se los accede en milisegundos), más baratos que la memoria (o sea con mucha capacidad a precio relativamente bajos) pero… cuando los desenchufo no se borran.
Así la información va y viene de los discos a la memoria según se necesite para su procesamiento.
Volvamos a lo nuestro… Utilizando un ejemplo de grandes consumidores de datos, las necesidades de análisis de datos de una empresa de telefonía argentina hace que almacene aprox. 10.000.000.000.000.000 de letras o números, o sea que sus discos tengan una capacidad de 10.000.000.000.000.000 de bytes. Como leer estos números enormes de este modo resulta poco práctico, se generaron múltiplos como sucede con todas las unidades de medida, así:
- 1024 bytes = 1 Kilobyte
- 1024 KB = 1 Megabyte
- 1024 MB = 1 Gigabyte
- 1024 GB = 1 Terabyte
- 1024 TB = 1 Petabyte
- 1024 PB = 1 Exabyte
- 1024 EB = 1 Zettabyte
- 1024 ZB = 1 Yottabyte
O sea que la empresa de telefonía mencionada almacena 10 Petabytes (lo que resulta más fácil de expresar que 10.000.000.000.000.000 bytes).
Nadie analiza tooooooda esa información al mismo tiempo, pero póngale que la parte que quiero analizar ocupa 100 TB. Según expliqué más arriba todo lo que necesitamos es un computador con mucha memoria y procesadores y yastá… pues que no.
Resulta que un computador tiene un techo sobre el cual ya no es posible agregarle más procesadores o memoria.
Permítame explicarle con esta analogía.
- Si quiero cargar 1000 kgs puedo comprarme una rural,
- 2500 kgs una camioneta,
- 9000 kgs un camión,
- 28000 kgs un camión con acoplado y muchos ejes,
- 80000 kgs un camionazo recontragrande con varios acoplados (difícil),
- 2000000 de kgs un camion grande como la cancha de Huracán, ¡¡¡No!!!
Hay un punto en el que ya no puedo hacer crecer más un camión porque no hay ejes, ni chasis, ni rutas que lo soporten. Entonces lo que me queda por hacer, si es que puedo hacerlo, es dividir mi carga en lotes y hacer trabajar a varios camiones al mismo tiempo.
Bueno… con los computadores sucede exactamente lo mismo. La única forma de procesar esos enormes volúmenes de información (Big Data) es dividirla en varios computadores, hacer que estos computadores trabajen en paralelo cada uno sobre la parte de información que le tocó, y luego se consoliden los resultados que cada uno obtuvo para obtener un resultado final.
Así repitiendo la primera parte de mi definición inicial…
Big Data es la capacidad de procesar en paralelo enormes volúmenes de información, de modo tal de poder analizar con mucho detalle el comportamiento de mis: clientes, ciudadanos, proveedores, productos, transacciones, etc, etc, etc.
Entonces a la pregunta ¿Por qué ahora? respondo, porque ahora contamos con computadores con cantidad de procesadores (varias decenas), capacidad de memoria (centenas de Gigabytes) y capacidad de disco (decenas de Terabytes) a precios asequibles; además con la llegada de "la nube" podemos alquilarlos por un rato. Pero fundamentalmente, contamos con la tecnología de software para hacerlos trabajar en paralelo. Sin ese paralelismo no hay Big Data.
Cuando hablo de paralelismo quiero decir desde dos computadores a varios miles trabajando en simultáneo.
El espacio de esta nota no me permite abundar en detalle, pero esas tecnologías de software son (entre otras): Hadoop, Map-Reduce, Tez, Spark, SAS Viya.
Vamos entonces a la segunda parte de mi definición "de modo tal de poder analizar con mucho detalle el comportamiento de mis: clientes, ciudadanos, proveedores, productos, transacciones, etc, etc, etc."
Listo, ya podemos procesar en paralelo, pero… ¿Qué algoritmos (fórmulas de cálculo) utilizamos?
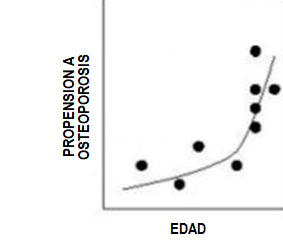
Las 3 técnicas analiticas fundamentales son: Regresiones, Árboles de decisión, Redes neuronales. Se las explico brevemente.
- Regresiones: Se trata de buscar funciones que relacionen los datos que conozco con el objetivo que persigo. Por ejemplo: Buscar una función que relacione la edad, nivel salarial, profesión, estado civil, lugar de residencia y todos los etcéteras que se le ocurran con la probabilidad de que las personas acepten mi nueva oferta de productos, cometan fraude, estén por dejar de ser mis clientes, tengan propensión a tener osteoporosis. De alguna forma las regresiones suponen que el mundo se relaciona mediante funciones matemáticas.
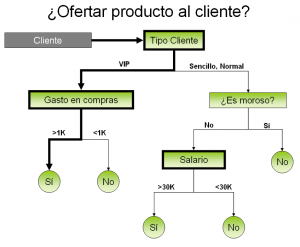
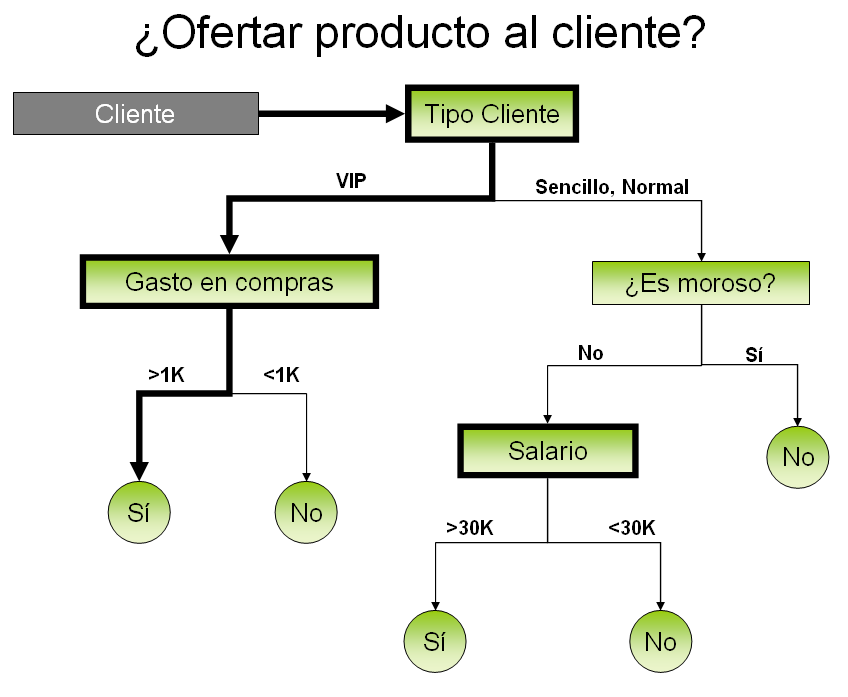
GRAFICO 2 – ARBOL DE DECISION (¿Le ofrezco mi producto a este cliente?) - Arboles de decisión: Se trata de buscar largas cadenas del tipo "Si sucede el evento 1 aumenta la probabilidad de la decision A, si no sucede aumenta la probabilidad de la decision B". Por ejemplo: Si el cliente es VIP aumenta la probabilidad de que acepte mi oferta, si es un cliente sencillo disminuye la probabilidad. Si su gasto previo en compras es mayor a 1000 aumenta la probabilidad de que acepte mi oferta; si no, la disminuye. Los algoritmos descubren cuales son las características relevantes para mi objetivo. En el ejemplo que muestra el Gráfico 2 las variables relevantes son Tipo de cliente, Gastos anteriores, Morosidad, Salario). De alguna forma los árboles de decisión suponen que el mundo se relaciona con enormes cadenas de decisiones del tipo "Si pasa esto, hago tal cosa; si no pasa, hago tal otra".
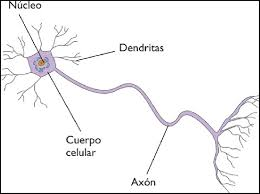
- Redes neuronales: Acá la cosa se pone más peliaguda para explicarlo en pocas palabras. Lo intento. Una red neuronal es una red de neuronas (¡Guauuu Sergio!, ahora sí entendieron todos). Cada neurona es un elemento de procesamiento independiente. Su funcionamiento está inspirado en cuestiones elementales del conocimiento que tenemos sobre el funcionamiento del cerebro humano (ver Gráfico 3.A).
Cada neurona recibe varios valores de entrada, cada valor de entrada es multiplicado por el peso de la conexión que une a la neurona en cuestión con su predecesora, los productos así obtenidos son sumados. Luego si esa suma supera un valor umbral, nuestra neurona dispara un valor de salida; si no supera el umbral no dispara nada (ver Gráfico 3.B).
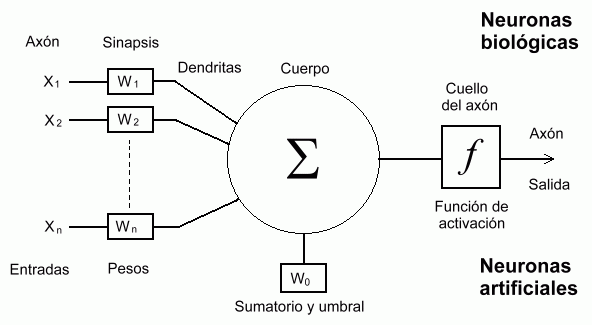
¿Hacia dónde dispara nuestra neurona ese valor de salida?. Pues a la neurona a la que está conectada aguas

abajo. O sea a la neurona que le sigue. Esta a su vez recibe varios valores de entrada que se multiplican por los pesos de las conexiones… y así sucesivamente repetimos la historia. O sea armamos una red de neuronas organizadas en capas, cada neurona de una capa está conectada a todas las neuronas de la capa siguiente hasta que en la última capa obtenemos el resultado buscado.
Por ejemplo, el Gráfico 3.C muestra una red neuronal con 3 neuronas en las que ingresamos el nivel salarial, saldo de la cuenta y tipo de ocupación de un solicitante de crédito, tiene una sóla capa intermedia de neuronas y en la capa de salida nos predice si será buen o mal pagador.
¿Adonde reside la magia?. La magia se produce en el establecimiento del peso de las conexiones entre las neuronas. En nuestra jerga decimos que los algoritmos "entrenan" a la red neuronal a partir de casos cuyo resultado conocemos. Ese "entrenamiento" establece los pesos de las conexiones para obtener el resultado buscado y una vez "entrenada", utilizamos la red neuronal para que prediga el comportamiento de los casos que no conocemos (¿Qué clientes están más propensos a aceptar mi nueva oferta de telefonía celular?. ¿Qué personas están cometiendo fraude o lavando dinero?, ¿Esta tomografía muestra un órgano sano o enfermo?.
Como puede ver, la cosa se complica un poco.
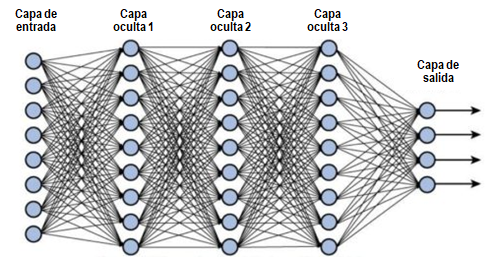
Termino mi intento de breve explicación diciendo que hay redes neuronales de muchas capas intermedias lo que aumenta su complejidad de implementación y su poder de predicción. El Gráfico 3.D muestra un esquema de red compleja.
Las tres técnicas que expliqué buscan lo mismo por diferentes caminos: Analizar la información que describe el comportamiento en el pasado para predecir el comportamiento presente y futuro.
Hay otra gran cantidad de algoritmos, entre otros: Random forest, Gradient boosting, Redes neuronales recurrentes, Redes neuronales convolucionales. Casi todos son variantes de las regresiones, árboles de decisión y redes neuronales que explique muuuuuy brevemente más arriba y todas comparten una característica fundamental: ¡¡¡ Son paralelizables !!!, o sea pueden explotar el procesamiento en paralelo con el que ahora contamos para "poder analizar con mucho detalle el comportamiento de mis: clientes, ciudadanos, proveedores, productos, transacciones, etc.".
Podemos decir que el conjunto de estas técnicas de análisis constituyen lo que llamamos "Mineria de Datos" durante largo tiempo y luego cuando el objetivo se hizo más ambicioso "Inteligencia Artificial".
Y así llegamos al final de la historia que concluiré repitiendo mi definición de Big Data: Big Data es la capacidad de procesar en paralelo enormes volúmenes de información, de modo tal de poder analizar con mucho detalle el comportamiento de mis: clientes, ciudadanos, proveedores, productos, transacciones, etc, etc, etc.
Mensaje comercial
Si mi explicación le resultó útil (o sea está pensando… ¡ahhhh! así era la cosa) y tal vez se esté preguntando ¿cómo incorporo esta tecnología a mi empresa?, le cuento que:
- Puede recurrir al diverso conjunto de herramientas que ofrece el mercado.
- Puede utilizar herramientas disponibles en la modalidad open source o…
- Puede tomar la mejor decisión y contactar a SAS, empresa para la que trabajo.
SAS provee soluciones de Big Data e Inteligencia Artificial poniendo foco en su facilidad de uso (amigabilidad) para que los usuarios de negocio puedan desarrollar procesos analíticos sin necesidad de recurrir al código de programación.
No le conté que para procesar los datos, primero hay que prepararlos, lo que toma bastante tiempo y trabajo. Tampoco le conté que una vez procesados hay que explonerlos de forma tal que sus resultados brinden beneficios tangibles.
Las soluciones SAS abarcan las tres etapas mencionadas: La preparación de los datos, su procesamiento analítico y su visibilización eficaz.
Esto no significa que si utiliza SAS deba descartar el uso de herramientas open source, todo lo contrario. Es foco principal de SAS la integración y complementación con el mundo open source.
Despedida
Me resulta difícil explicar en un texto corto cuestiones como éstas que dan cómodamente para escribir uno o varios libros (hay muchos ya escritos).
Si mi explicación le resultó de utilidad, por favor hágamelo saber para darme ánimo para escribir más notas como ésta (y de paso le hago leer su opinión a mi gerente lo que aumenta la probabilidad de mejorar mi salario).
Si mi explicación no le gustó, por favor también hágamelo saber para intentar mejorar.
En cualquier caso, le agradezco el tiempo que dedicó a leer esta nota.
Respuesta a la trivia 1: 47 años y medio.
Respuesta a la trivia 2: Será un cubo de una cuadra por lado.
