PythonからSAS Viyaの機能を利用するための基本パッケージであるSWATと、よりハイレベルなPython向けAPIパッケージであるDLPyを使用して、Jupyter NotebookからPythonでSAS Viyaの機能を使用してセマンティック・セグメンテーション(Semantic Segmentation)を試してみました。
大まかな処理の流れは以下の通りです。
1. 必要なパッケージ(ライブラリ)のインポートとセッションの作成
2. 画像データ内容の確認とセグメンテーション用データセットの作成
3. モデル構造の定義
4. モデル生成(学習)
5. セグメンテーション(スコアリング)
1. 必要なパッケージ(ライブラリ)のインポートとセッションの作成
swatやdlpyなど、必要なパッケージをインポートします。
%matplotlib inline # SWAT パッケージのインポート import swat as sw import sys # DLPy パッケージのインポート import dlpy from dlpy.network import * from dlpy.utils import * from dlpy.applications import * from dlpy.model import * from dlpy.images import * from dlpy.layers import * from matplotlib import pylab as plt from matplotlib import image as mpimg |
次にSAS ViyaのインメモリーエンジンであるCAS(Cloud Analytic Services)に接続しセッションを作成し、使用する関数が含まれているグループ(アクションセット)をロードします。
s = sw.CAS(host_name, port) s.loadactionset('image') s.loadactionset('deepLearn') |
2.画像データ内容の確認とセグメンテーション用データセットの作成
分析対象の画像データとそれに対するマスク画像データ内容を確認してみましょう。
まずは、分析対象の画像データを読み込み表示してみます。
raw = ImageTable.load_files(conn=s, path='/home/sasdemo/data/segmentation_data/raw') raw.show() |

s.table.fetch(raw, to=2) |
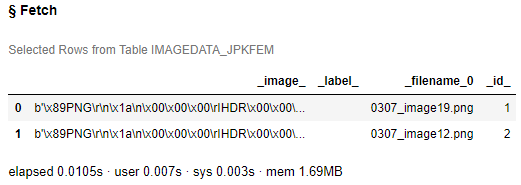
_image_:画像データ(binary)
_filename_0:画像ファイル名
_id_:ID値
次に、マスク画像データを読み込み表示してみます。
マスク画像には [0, 1, 2] のみが含まれているので、真っ黒に表示されます。ちなみに、0:プレイヤー、1:ボール、2:背景、です。
mask = ImageTable.load_files(conn=s, path='/home/sasdemo/data/segmentation_data/mask') mask.show() |

s.table.fetch(mask, to=2) |
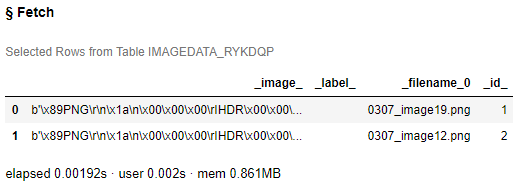
_filename_0の内容の通り、対象画像データファイル名と対するマスク画像ファイル名は同じにしてあります。
それでは、これら2種類の画像を統合し、セグメンテーション用のデータセットを作成しましょう。
DLPyに含まれるcreate_segmentation_table()関数を使用すると簡単に作成することができます。
tbl = create_segmentation_table(s, path_to_images='/home/sasdemo/data/segmentation_data/raw', path_to_ground_truth='/home/sasdemo/data/segmentation_data/mask') |
作成されたデータセットの内容を確認してみます。
tbl.fetch(to=2) |
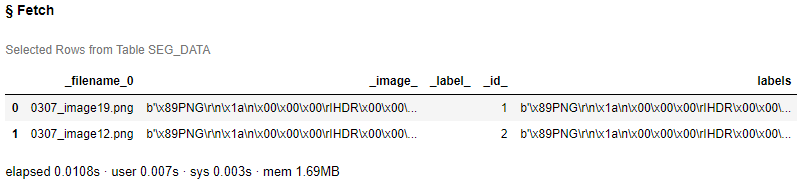
_filename_0:画像ファイル名
_image_:画像データ(binary)
_id_:ID値
Labels:マスク画像データ(binary)
ご覧の通り、画像ファイル名ごとに、1行に対象画像データとマスク画像データが格納されていることがわかります。
作成されたセグメンテーション用のデータセットに含まれる画像をDLPyに含まれるdisplay_segmentation_images()関数を使用して表示してみましょう。
display_segmentation_images(s, tbl, n_images=4, segmentation_labels_table=tbl) |

今度は、マスク画像もちゃんと表示されています。
この後は、対象画像データに加えて、それらを左右反転させた画像も追加した上で、上記手順で作成したデータに、データ分割時に使用するインデックス(idx)列も追加したデータセットを使用します。
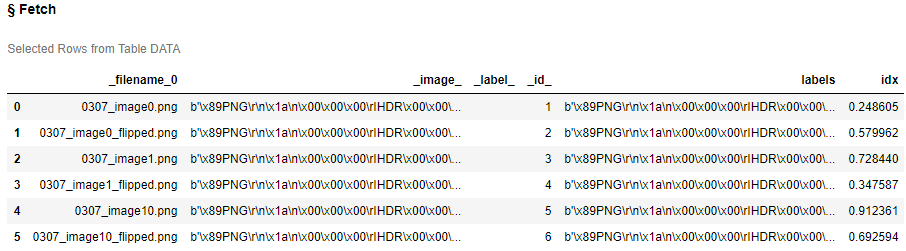
以下が使用するデータセット内容です。
s.table.fetch('data', to=2, sasTypes=False) |
display_segmentation_images(s, 'data', n_images=4, segmentation_labels_table='data') |

idx列の値に基づきデータを分割します。学習用(70%)、検証用(20%)、テスト用(10%)
train = s.CASTable('data', where = 'idx >= 0.3') len(train) |
115
valid = s.CASTable('data', where = 'idx < 0.3 and idx >= 0.1') len(valid) |
33
test = s.CASTable('data', where = 'idx < 0.1') len(test) |
22
3.モデル構造の定義
セマンティック・セグメンテーションに使用する代表的なネットワークアーキテクチャであるU-Netを使用します。
DLPyに含まれるUNet()関数を使用してモデル構造を簡単に定義することができます。
model = UNet(s, n_classes=3, n_channels=3, bn_after_convolutions=True) |
定義された構造を確認してみましょう。
model.print_summary() |
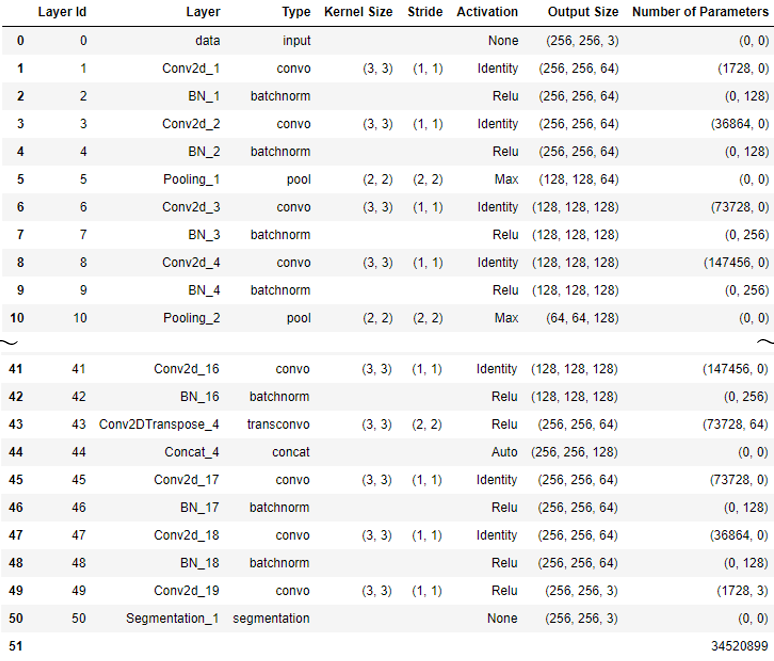
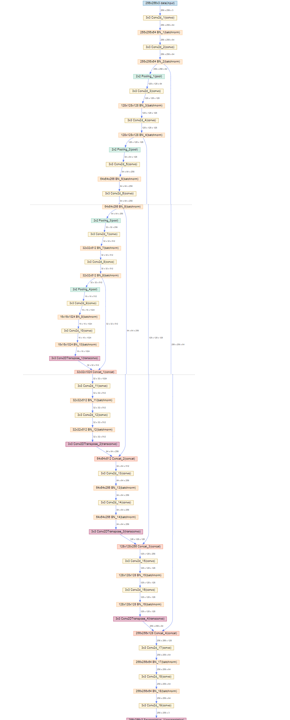
DLPyに含まれるplot_network()関数でビジュアライズすることもできます。
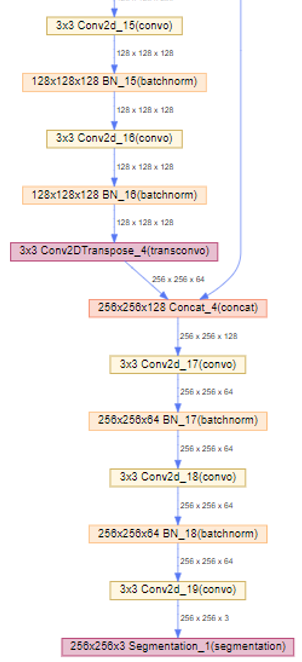
model.plot_network() |
一部を拡大
4.モデル生成(学習)
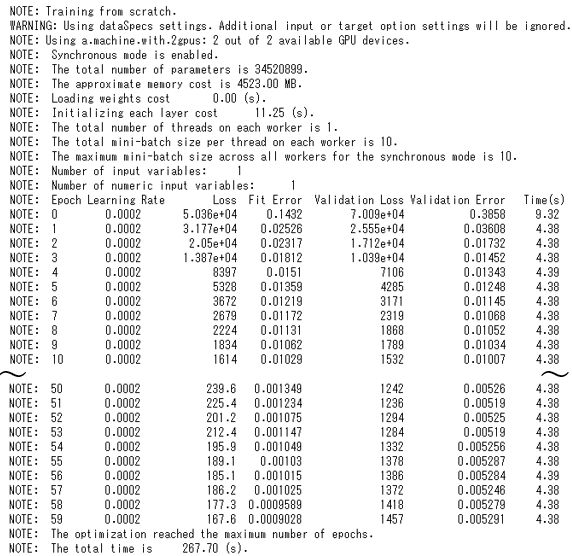
まず、学習用のパラメータを設定します。miniBatchSize = 10 、Max epochs = 60、最適化手法:ADAM、開始学習率= 2e-4、など
solver = AdamSolver(lr_scheduler=StepLR(learning_rate=0.0002, step_size=30, gamma=0.8), clip_grad_max = 100, clip_grad_min = -100) optimizer = Optimizer(algorithm=solver, mini_batch_size=10, log_level=2, max_epochs=60, reg_l2=0.0005, seed=13309) dataspecs=[dict(type='image', layer='data', data=['_image_']), dict(type='image', layer='Segmentation_1', data=['labels'])] |
上記パラメータで学習させます。
以下のように“gpu = 1”を指定すると、使用可能なすべてのGPUデバイスが使用されます。
model.fit(data=train, valid_table=valid, optimizer=optimizer, data_specs=dataspecs, n_threads=1, record_seed=54321, force_equal_padding=True, gpu=1) |
5.セグメンテーション(スコアリング)
作成されたモデルにテストデータを当てはめてスコアリングを実行します。
スコアリング時もGPUを使用するように指定しています。
model.predict(test, gpu=1) |
予測結果を画像に変換します。
def compile_segmentation_predictions(): cvars = ['origimage', 'c0'] for i in range(1, 256*256): list.append(cvars, 'c' + str(i)) cvarspgm = "length origimage varchar(*); origimage=_image_; c0=input(_DL_PredName0_, 12.); " for i in range(1, 256*256): cvarspgm += 'c' + str(i) + '=input(_DL_PredName' + str(i) + '_, 12.); ' r = s.table.view( name='oview', tables=[dict(name=model.valid_res_tbl.name, computedvars=cvars, computedvarsprogram=cvarspgm, varlist={'_DL_PredName0_', '_filename_0'})], replace=True) renamed=0 s.image.condenseimages(table='oview', width=256, height=256, casout=dict(name='final_images_predicted', replace=True), numberofchannels=1, depth='bit32', copyvars=['origimage', '_filename_0']) compile_segmentation_predictions() |
NOTE: 22 out of 22 images were processed successfully and saved to the Cloud Analytic Services table final_images_predicted. |
最後に、予測結果の画像を出力して確認してみましょう。
DLPyに含まれるdisplay_segmentation_results()関数を使用して、元の画像、マスク画像、予測結果画像を並べて確認することができます。
display_segmentation_results(s, model.valid_res_tbl, n_images=2, segmentation_labels_table=model.valid_res_tbl, segmentation_prediction_table='final_images_predicted', prediction_column='_image_', filename_column='_filename_0', fig_size=(15,10)) |

DLPyパッケージを使用することで、より簡潔なコーディングで、セマンティック・セグメンテーション(Semantic Segmentation)が実施可能であることを感じ取ってもらえたでしょうか!?
※DLPyの詳細はGithubサイトをご覧ください。
※Enterprise Open Analytics Platform「SAS Viya」を知りたいなら、「特設サイト」へGO!
