この記事はSAS Institute Japanが翻訳および編集したもので、もともとはIvor G. Moanによって執筆されました。元記事はこちらです(英語)。
データ準備の概念と重要性
「データ準備」とは、アナリティクスやビジネスインテリジェンス(BI)で利用するためのデータを収集/処理/クレンジングする工程に含まれる全てのタスクを指します。したがって、データ準備には、アクセス、ロード、構造化、パージ、結合(ジョイン)、データタイプの調整、フィールド値の整合性チェック、重複のチェック、データの統一化(例:1人の人物に2つの誕生日が存在する場合)などが含まれます。
データの量やソースの数が増えるにつれ、適切なデータ準備を行う取り組みは、コストと複雑性がともに増大していきます。そのため、データ準備は今、市場を形成しつつある新たなパラダイムとなっています。また、データ準備は事実上、セルフサービス型のデータ管理の取り組みと化しています。従来のデータ管理プロセスは、ある程度まではデータ統合および準備を実行できますが、今では、ダイナミックかつ詳細な作業や最終段階の作業に関しては、データ準備ツールを用いてセルフサービス方式で実行されるようになりつつあります。
明らかなことは、データを整形し、アナリティクスに適した状態にする上でデータ準備がますます重要になりつつある、ということです。今では、以前よりも多くの企業がデータドリブン(データ駆動型)を実現しています。それらの企業はデータに基づいて意思決定を行いますから、「データに素早くアクセスし、分析に適した状態に準備できること」が極めて重要です。Hadoopなどのビッグデータ環境は、「それらの環境からデータを移動することが不可能」ということを意味します(が、それは問題とはなりません)。その代わり、「アナリティクス向けにデータを準備する工程の一環として、ビッグデータを適切な場所で適切に処理し、その結果のデータを他のソースと組み合わせること」が重要となります。
したがって、データ準備は、あらゆるアナリティクス・プロジェクトの不可欠な構成要素と言えます。適切なデータを取得し、それを適切な状態に準備することによってこそ、アナリティクスの疑問に対して優れた答えを得ることが可能になるのです。質の低いデータや不適切に準備されたデータを使用すると、分析結果が「信頼に足るもの」になる可能性は低下してしまいます。
アナリティクス・ライフサイクルにおけるデータ準備を理解する
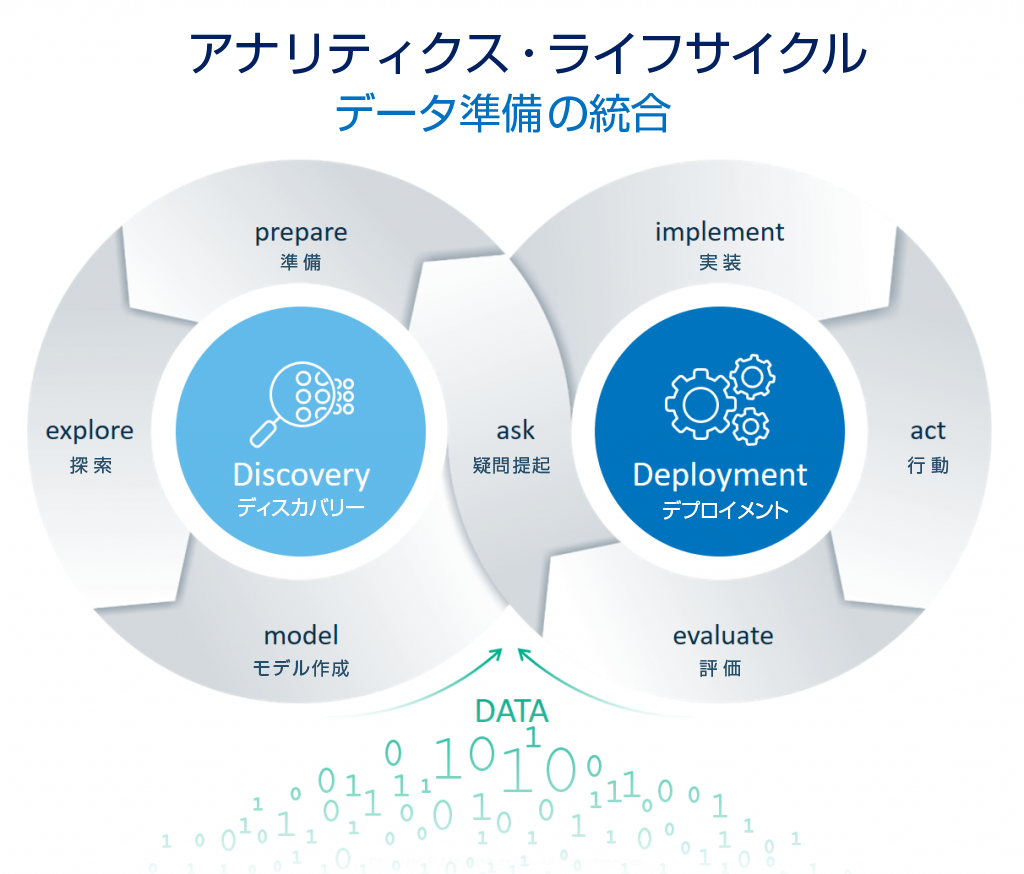
アナリティクス・ライフサイクルには「ディスカバリー」および「デプロイメント」という2つの主要なフェーズが存在します。「ディスカバリー」プロセスは、イノベーションを生み出すビジネス上の疑問を提起することによって推進されます。したがって最初のステップは、ビジネスにおいて何を知る必要があるかを定義することです。その後、ビジネス上の疑問は「問題を説明する表現」へと変換され、その結果、予測的アナリティクスを用いてその問題を解決することが可能になります。
そして言うまでもなく、予測的アナリティクスを利用するためには、適切に準備された適切なデータが必要不可欠です。Hadoopや高速化・低価格化するコンピューターといったテクノロジーの進歩により、従来では考えられなかったほど大量かつ多様なデータを蓄積し利用することが可能になっています。しかしながら、この動向は、多種多様なフォーマットのソースデータを結合する必要性や、生データを “予測モデルへの入力として利用できる状態” に変換する必要性を増大させたにすぎません。コネクテッド・デバイスが生成する新しいタイプのデータ(例:マシンセンサー・データやオンライン行動のWebログなど)の出現により、「データ準備」段階は以前にも増して難しい課題領域となっています。多くの組織は依然として、「データ準備タスクに過大な時間を費やしており、場合によっては[全作業時間の]最大80%を占めている」と報告しています。
データ準備は継続的なプロセスである
データ探索では、対話操作型かつセルフサービス型のビジュアライゼーションツール群を活用します。これらのツールは、統計知識を持たないビジネスユーザーから、アナリティクスに通じたデータサイエンティストまで、幅広いユーザーに対応している必要があります。また、これらのユーザーが関係性/トレンド/パターンを洗い出し、データに関する理解を深めることを可能にしなければなりません。言い換えると、このステップ(=探索)では、プロジェクト初期の「疑問提起」段階で形成された疑問やアプローチを洗練させた上で、そのビジネス課題を解決する方法についてアイディアの開発とテストを行います。ただし、より照準を絞ったモデルを作成するために変数の追加/削除/結合が必要になる可能性もあり、その場合は当然、「データ準備」を再び実行することになります。
「モデル作成」段階では、分析モデルや機械学習モデルを作成するためのアルゴリズムを使用します。その目的は、データ内に潜む関係性を浮き彫りにし、ビジネス上の疑問を解決するための最良のオプションを見つけ出すことです。アナリティクス・ツールは、データとモデリング手法をどのように組み合わせれば望ましい結果を高い信頼性で予測できるかを特定するために役立ちます。常に最高のパフォーマンスを発揮する唯一万能のアルゴリズムは存在しません。そのビジネス課題を解決するための “最良” のアルゴリズムが何であるかは、そのデータによって決まります。最も信頼性の高い解を見つけるためのカギは実験を繰り返すことです。適切なツールでモデル作成を自動化することにより、結果が得られるまでの時間が最小化され、アナリティクス・チームの生産性が向上します。そして、ここでも再び、さらなるデータが追加される可能性があります。
「実装」段階へ
もちろん、モデルの作成が済んだら、それらをデプロイ(=業務システムに組み込んで運用)する必要があります。しかし、その後も「データ準備」の取り組みは停止しません。モデルの良否はそれが利用するデータに左右されるため、モデル(およびデータ)については鮮度を維持し続けなければなりません。データ準備とデータ管理は、極めて継続的なプロセスなのです。
