Recently I have been thinking about data preparation, but not just any kind of data preparation.
I have been thinking about the preparation required for advanced analytics and predictive models. Recently, I had to explain the process of how to create this data and this proved to be somewhat challenging given a lot of these concepts were new to business people. I initially talked through it which seemed to be ineffective, but then my team suggested a whiteboard approach which made things a lot easier to digest. There are some very specific requirements for the data sets for this type of modelling. For example, if you are predicting a customer’s propensity to take up an offer, each customer has to be represented on a single row. The data also need to include predictors (which will be used to make the predictions) and a target variable (which is the outcome that will be predicted).

The problem is that, as most analysts quickly discover, “nice” data sets rarely exist. Data sets are rarely well-populated, with accurate and relevant data in the correct fields. More often than not, you have to spend weeks or even months trying to get the data into a useable format before you can provide useful insights. You could argue that business users should be responsible for data quality, especially in a self-service world, but that does not really help at the time.
Most analysts therefore rapidly learn data preparation skills alongside being able to manipulate data effectively.
A neglected skill-set
It is interesting, though, that many articles on data science focus on the modelling aspects and tend to ignore the data preparation elements: The process of creating the data set. Perhaps the authors assume that this process is basic and elementary, but bad data preparation can lead to disastrous outcomes especially if used in a business framework. More realistically, data preparation is the foundation of analytics: The best, and some would say only, way to speed up the analytics process is to reduce the data preparation time.
In practice, though, what needs to be done to create a data set for a predictive model? As a first step, it needs an observation and a performance window. An observation window is used to choose the period for the predictor variables and the performance window is used to define the target variable.
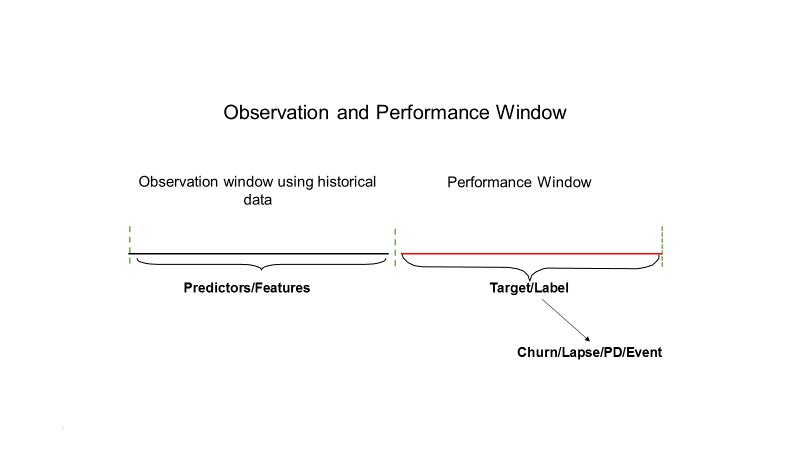
With historic data, we need to identify one-off events that occurred during the observation window, and decide whether to include these events in the model. An example of this could be a special type of marketing promotion.
Modernizing the Analytics Life Cycle includes speeding up supporting processes. Analytics agility demands intuitive data preparation. Tune in to this webinar to learn how.
In some cases, the target variable is already defined in the data, such as a field indicating whether a customer responded to an offer. However, sometimes the target must be defined based on events using business logic. For telco churn prediction, for example, you could define churn as a customer with no activity for three months.
Suppose we are developing a propensity-to-respond model to increase take-up rates. Data sources might include:
- Historical campaigns with outcomes;
- Socio demographic data and Customer demographic;
- Customer product data;
- Customer transactional data; and
- Credit bureau data.
Once we have sifted out the irrelevant information, we then have to apply domain knowledge to get to know the data and be on the lookout for discrepancies. We also need to clean the data.
- Frequency tables and plots are a great way to identify missing data, outliers, incorrect data and other data quirks. We should also look at the distribution of continuous variables like age and income. This step may be dull, but it should never be ignored. For missing data, we need to check what proportion is missing, and examine the imputations.
- You need to check the data for validity and reliability, by going straight to the source. Does your data set represent reality? Check a few examples on the system. Again, dull, but important. You should then cross-check columns for consistency. You may find that certain variables have inconsistent information.
 It is also important to validate the summarised data against other data and make sure the numbers are aligned. They will probably never fully match up, but this is acceptable if you can explain the differences rationally. To enrich models further, you can then add relevant variables like behavioural information. For example, in a Telco Churn prediction model, number of complaints in the past 6 months or average top up amount over the last 12 months.
It is also important to validate the summarised data against other data and make sure the numbers are aligned. They will probably never fully match up, but this is acceptable if you can explain the differences rationally. To enrich models further, you can then add relevant variables like behavioural information. For example, in a Telco Churn prediction model, number of complaints in the past 6 months or average top up amount over the last 12 months.
Lastly, once you have created the training data set for the model development process, you can use the same process to develop the validation data sets to assess model performance. Some models need an out-of-time sample requiring specific domain knowledge. You must also consider whether the model input data is readily available for scoring in a production environment.
Seeing patterns where none exist
Finally, when creating data sets for model-building it is best to remember, as Michael Shermer put it, that:
“Humans are pattern-seeking story-telling animals, and we are quite adept at telling stories about patterns, whether they exist or not.”
Humans are adept at telling stories about patterns, whether they exist or not #DataPreparation Share on X