PythonからSAS Viyaの機能を利用するための基本パッケージであるSWATと、よりハイレベルなPython向けAPIパッケージであるDLPyを使用して、Jupyter NotebookからPythonでSAS Viyaのディープラーニング機能を使用した時系列予測を試してみました。
大まかな処理の流れは以下の通りです。
1.必要なパッケージ(ライブラリ)のインポート
2.Sin波データの生成
3.セッションの作成
4.RNN向け時系列データセットの作成
5.モデル構造の定義
6.モデル生成(学習)
7.予測
1.必要なパッケージ(ライブラリ)のインポート
swatやdlpyなど、必要なパッケージをインポートします。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import swat.cas.datamsghandlers as dmh from swat import * import dlpy from dlpy import Sequential from dlpy.layers import * from dlpy.model import Optimizer, AdamSolver, Sequence %matplotlib inline |
2.sin波データの生成
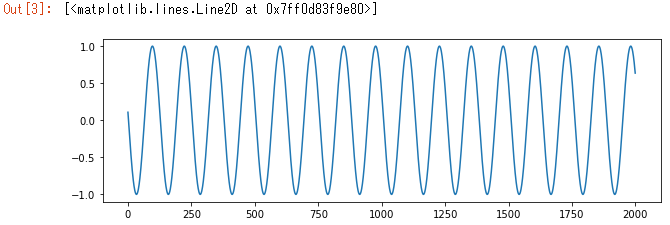
numpyを使用してsin波データを生成します。
np.random.seed(2) T = 20 L = 2000 N = 100 x = np.empty((N, L), 'int64') x[:] = np.array(range(L)) + np.random.randint(-4 * T, 4 * T, N).reshape(N, 1) data = np.sin(x / T).astype('float64') fig, ax = plt.subplots(1,1,figsize=(10,3)) ax.plot(data[0, :]) |
pprint.pprint(data) |
array([[ 0.10819513, 0.05837414, 0.00840725, ..., 0.7099113 , 0.67382421, 0.63605292], [-0.38941834, -0.34289781, -0.29552021, ..., -0.88241219, -0.85779535, -0.83103446], [-0.23924933, -0.28747801, -0.33498815, ..., 0.42537143, 0.37960774, 0.33289522], ..., [-0.24740396, -0.19866933, -0.14943813, ..., -0.80219643, -0.77135332, -0.73858223], [ 0.99749499, 0.99978376, 0.9995736 , ..., 0.7304872 , 0.76370638, 0.79501668], [-0.99749499, -0.99271299, -0.98544973, ..., -0.81955143, -0.84716555, -0.87266219]]) |
3.セッションの作成
SAS Viyaに接続し、セッションを作成します。
conn = CAS(host, port, user, password) |
4.RNN向け時系列データセットの作成
SAS Viyaのディープラーニング(RNN)向けの学習用データセットは、DLPyを使用することで、簡単に作成することができます。
4-1.最初の配列内sin波データをPandas Seriesとして収納
one_sine = pd.Series(data[0,:], name='sine') |
4-2.Pandas SeriesをSAS ViyaのCASテーブル(インメモリーテーブル)としてロード
sine_tbl = dlpy.TimeseriesTable.from_pandas(conn, one_sine) |
DLPyのTimeseriesTable.from_pandas()メソッドを使用すると、Pandas SeriesやDataframeをSAS ViyaのCASテーブル(インメモリーテーブル)としてロードすることができます。
4-3.データセット内列項目のフォーマット
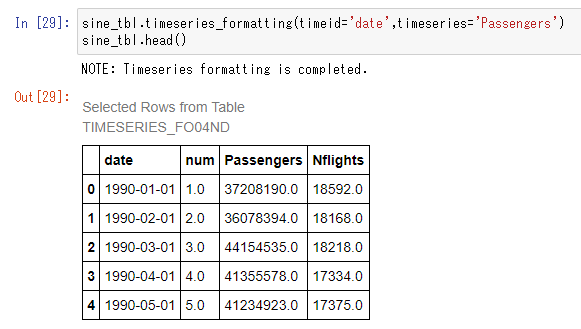
sine_tbl.timeseries_formatting(timeid='index',timeseries='sine') |
DLPyのtimeseries_formatting()メソッドを使用すると、時間軸が含まれる列と予測対象値が含まれる列の適切な型変換を行うことができます。
例えば、Timeid=に指定した時間軸の項目が文字列の場合に、数値変換を行ったり、文字列をパース後に、書式を指定した上で日付変換などを行えます。
今回使用しているSin波データでは、型変換の必要は特にないため、この処理は割愛できます。
4-4.時系列データ値を累積
# sine_tbl.timeseries_accumlation(acc_interval='・・・') |
DLPyのtimeseries_accumlation()メソッドを使用すると、Timeidに指定した列が日付属性の場合には、必要に応じて累積間隔を指定して時系列データ値を累積することができます。
今回使用のsin波データではtimeidは日付ではなくindexであり、累積の必要もないので、このメソッドを使用する必要はありません。
累積単位(acc_interval=)として以下を指定可能:
'year', 'qtr', 'month', 'week', 'day', 'hour', 'minute', 'second'を指定可能
(例)
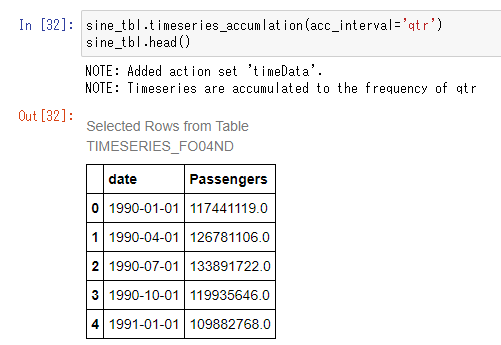
以下は、上記時系列データに対して、累積間隔を'qtr'(四半期)単位に設定したものです。
1990年1月~3月のデータが1990年1月として、1990年4月~6月のデータが1990年4月として、累積されています。
4-5.1期間ずつズラした時系列データ+予測値(ターゲット)を持つデータセットの作成
seq_len=に指定された値(100)のスライディング・ウィンドウを持つsin波データの時系列のサブシーケンスを作成します。1データレコード目(1~100),2データレコード目(2~101),3データレコード目(3~102)…のように1期間ずつズラしたデータ+予測値列、1データレコード目は101番目の値、2データレコード目は102番目の値、…のような行を持つデータセットを生成します。
sine_tbl.prepare_subsequences(seq_len=100, target='sine') sine_tbl.head() |
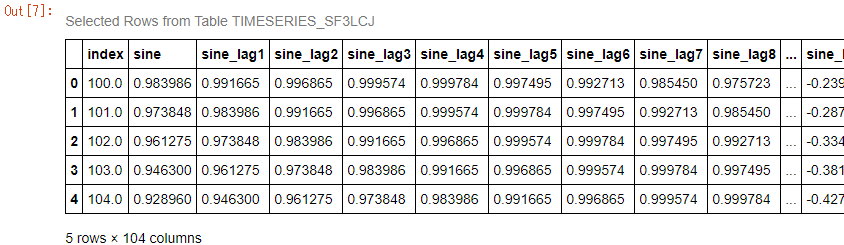
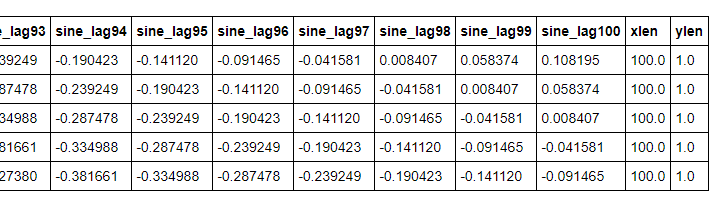
DLPyのprepare_subsequences()メソッドを使用すると、上記のように、1期間ずつズラした時系列データ+予測値(ターゲット)を持つデータセットを簡単に作成することができます。
4-6.データ分割
学習用、検証用、テスト用にデータを分割します。
生成した最初の配列に含まれる2,000個のsin波データに基づき生成された、2,000データレコードを持つ学習用のデータセットを学習用(0-1549)、検証用(1550-1749)、テスト用(1750-1999)に分割します。
validation_start = 1550 testing_start = 1750 train_tbl, valid_tbl, test_tbl = sine_tbl.timeseries_partition(validation_start=validation_start, testing_start=testing_start) |
NOTE: Timeseries formatting is completed. NOTE: Added action set 'timeData'. NOTE: timeseries subsequences are prepared with subsequence length = 100 NOTE: Training set has 1450 observations NOTE: Validation set has 200 observations NOTE: Testing set has 250 observations |
DLPyのtimeseries_partition()メソッドを使用すると、簡単にデータを分割することができます。
以上のような便利なメソッドを活用することで、学習用データを効率的に生成することができます。
5.モデル構造の定義
RNNのモデル構造を定義します。
DLPyを使用すると、Kerasと同等な簡潔なコーディングでネットワーク構造を定義することができます。
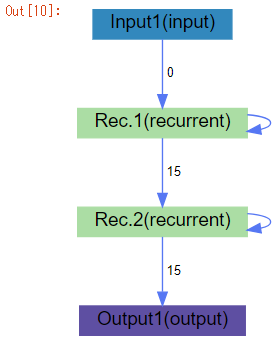
model1 = Sequential(conn, model_table='lstm_rnn') model1.add(InputLayer(std='STD')) model1.add(Recurrent(rnn_type='LSTM', output_type='samelength', n=15, reversed_=False)) model1.add(Recurrent(rnn_type='LSTM', output_type='encoding', n=15, reversed_=False)) model1.add(OutputLayer(act='IDENTITY')) model1.print_summary() |

ネットワークをビジュアライズします。
model1.plot_network() |
最適化パラメータなど必要なパラメータ情報を設定します。
optimizer = Optimizer(algorithm=AdamSolver(), mini_batch_size=32, seed=1234, max_epochs=100) # The attribute sequence_opt of train_tbl contains all the essential sequence modeling information # It includes: input_length, target_length, token_size seq_spec = Sequence(**train_tbl.sequence_opt) train_tbl.inputs_target |

6.モデル生成(学習)
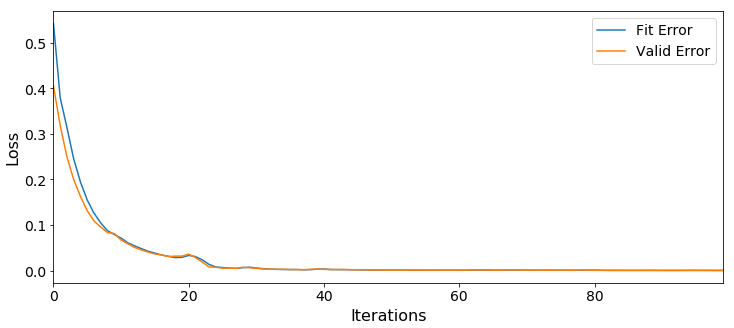
設定したネットワーク構造とパラメータでモデルを生成し、その学習履歴を表示します。
result = model1.train(train_tbl, model='lstm_rnn', model_weights=conn.CASTable('rnn_weights', replace=True), valid_table=valid_tbl, optimizer=optimizer, sequence=seq_spec, **train_tbl.inputs_target) result.OptIterHistory[['FitError', 'ValidError']][0:].plot(figsize=(12,5)) ax = plt.gca() ax.get_xaxis().set_tick_params(labelsize=14) ax.get_yaxis().set_tick_params(labelsize=14) ax.legend(['Fit Error', 'Valid Error'], loc='upper right', prop={'size': 14}) ax.set_xlabel('Iterations',fontsize=16) ax.set_ylabel('Loss',fontsize=16) |
7.予測
作成したモデルにテストデータを当てはめて、予測を実行し、結果を表示します。
r2 = model1.score(test_tbl, model = 'lstm_rnn', init_weights = 'rnn_weights', copy_vars=['index', 'sine'], casout=dict(name='predicted', replace=True)) localtest = conn.CASTable('predicted') localtest = localtest.fetch(to=localtest.shape[0], maxrows = localtest.shape[0])['Fetch'] fig, ax = plt.subplots(1,1,figsize=(16,8)) ax.plot(one_sine.index[:testing_start], one_sine.iloc[:testing_start], linewidth=2, color='blue') ax.plot('index','_DL_Pred_', data = localtest, linestyle='--', color='red', linewidth=2) ax.get_xaxis().set_tick_params(direction='out', labelsize=14) ax.get_yaxis().set_tick_params(labelsize=14) ax.set_ylim([-1.5, 1.5]) ax.legend(['History Value', 'Forecasted Value'], loc='upper right', prop={'size': 14}) |
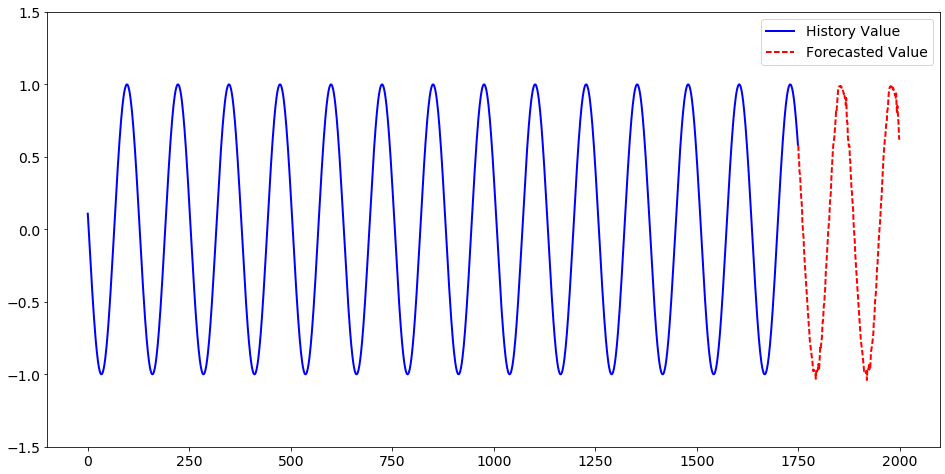
以上のように、SAS Viyaのディープラーニングでは、CNNを用いた画像認識だけではなく、RNNを用いた時期列予測に関しても、DLPyを使用することで、データの準備~モデリングに至る作業をより効率的に実施可能なんですね。
※DLPyの詳細に関しては、Githubサイトをご覧ください。
※上記デモ内容は、SAS Viya特設サイト内の「機械学習」と「オープン」のサイトにてデモ動画も公開しています。
※オープン・AIプラットフォーム「SAS Viya」を知りたいなら、「特設サイト」へGO!
