2014
およそ2014年からSAS on Hadoopソリューションを本格展開してきました。時代背景的には、2014頃は依然として、業態の特性からデータが巨大になりがちで、かつそのデータを活用することそのものが競争優位の源泉となる事業を展開する企業にHadoopの活用が限られていたと思います。その頃は、すでにHadoopをお持ちのお客様に対して、SASのインメモリ・アナリティクス・エンジンをご提供するというケースが大半でした。
その後、急速にHadoopのコモディティ化が進んだと感じます。
2015
2015頃になると、前述の業態以外においてもビッグデータ・アナリティクスの成熟度が上がりました。データ取得技術の発展も伴い、これまで活用していなかった種類や量のデータを競争優位性のために活用を志向するようになり、蓄積および処理手段としてのHadoopの選択が加速します。この頃になると、数年前には必ずあったHadoopそのものの検証ステップを踏まない企業が増えてきます。データ量、処理規模、拡張性、コスト効率を考えたときに妥当なテクノロジーがHadoopという結論になります。ビッグデータはデータのサイズだけの話ではありませんが、筆者の足で稼いだ統計によると、当時大体10TBくらいが、従来のテクノロジーのまま行くか、Hadoopを採用するかの分岐点として企業・組織は算段していたようです。この時期になると、従来のテクノロジーの代替手段としてのHadoopの適用パターンが見えてきました。
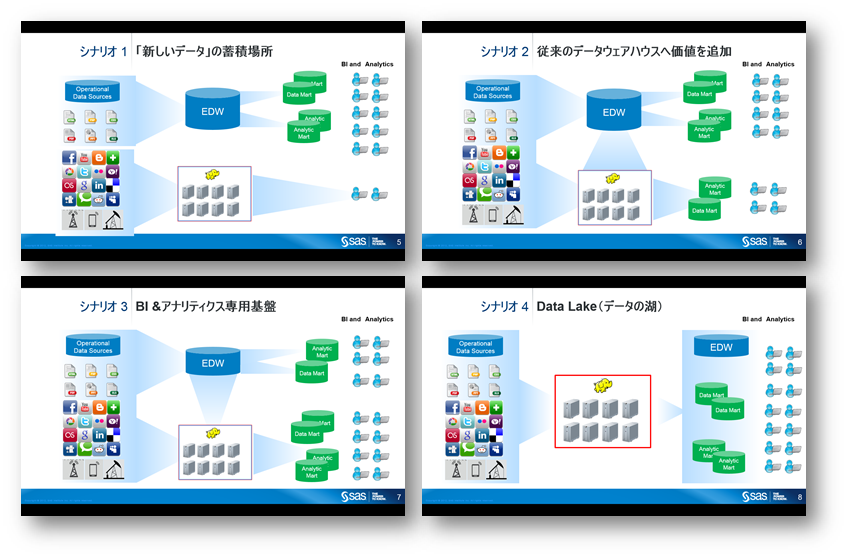
- 新しいデータのための環境
- 従来捨てていた、あるいは新たに取得可能になった新しいデータをとりあえず蓄積して、何か新しいことを始めるためのある程度独立した環境として、コスト効率を考慮してHadoopを採用するパターン
- 既存のデータウェアハウスへ価値を付加(上の発展形であることが多い)
- 新たなデータを使用してHadoop上で加工し、アナリティクス・ベーステーブルにカラムを追加し、アナリティクスの精度を向上
- ETL処理負荷やデータ格納場所のHadoopへのオフロード
- BI & アナリティクスの専用基盤
- SQLベースのアプリケーションだけをRDBMSに残し、その他の機械学習、ビジュアライゼーションなどSQLが不向きな処理をすべてHadoop上で実施
- 多くは、インメモリアナリティクスエンジンと併用
- データレイク
- (筆者の意見としては)いざ新しいデータを使用しようと思ったときのスピード重視で、直近使用しないデータも含めて、全てのデータを蓄積しておく。よくあるのが、新しいデータを使用しようと思ったときには、まだデータが蓄積されておらず、利用開始までタイムラグが生じてしまうケース。その時間的損失すなわち利益の喪失を重要視し、そのような方針にしている企業が実際に当時から存在します。
2016
海外の事例等では数年前から見られましたが、2016になると、日本でも以下の傾向が見られます
- 既存Hadoopをそのコンセプトどおりスケールアウトしていくケース
- グローバル・データ・プラットフォームとして、複数のHadoopクラスターを階層的に運用するケース
- AI、機械学習ブームにより機械学習のためのデータの蓄積環境として
- IoTの流れにより、ストリーミング処理(SASでいうと、SAS Event Streaming Processingという製品です)と組み合わせて
まさに、Hadoopがデータプラットフォームとなる時代がやって来たと思います。その証拠に、SAS on Hadoopソリューションは、日本においても、金融、小売、通信、サービス、製造、製薬といったほぼ全ての業種において活用されています。
Hadoopの目的は、従来型のBI・レポーティングではなく、アナリティクス
このような流れの中で、Hadoopの採用には一つの確固たる特徴が浮かび上がっています。もちろん弊社が単にITシステムの導入をゴールとするのではなく、ビジネス価値創出を提供価値のゴールにしているというバイアスはあるのですが。。。
- Hadoopの導入目的は、ビジネス価値を創出するアナリティクスのためであることがほとんどである
- したがって、Hadoopに格納されるデータには主にエンドユーザーがアナリティクス観点の目的志向でアクセスするケースがほとんどである
つまり、ある程度の規模のITシステムではあっても、Hadoopに格納されるデータはアナリティクスの目的ドリブンでしかアクセスされません。主たるユーザーは、分析者やデータ・サイエンティストです。彼らが、「使いたい」と思った瞬間にアクセスできる必要があるのです。このようなユーザーサイドのリクエストは、従来のBIすなわちレポーティングのような固定化された要件定義をするような依頼ではないため、その都度従来のようにIT部門と要件をすり合わせて、IT部門にお願いするという方法では成り立ちません。その数日、数週間というリードタイムが意思決定を遅らせ、企業の業績に悪影響をもたらすからです。あるいはIT部門の担当者を疲弊させてしまいます。つまり、アナリティクスにおいては、分析者・データサイエンティストが自分自身で、Hadoop上のデータにアクセスし、必要な品質で、必要な形式で、必要なスピードで取得するために自由にデータ加工できる必要があるのです。
SASを使えば、ビジネスユーザーはHadoop上での必要なデータ準備のために、限られたITリソースに頼る必要は、もはやありません Share on Xこのあたりの話については、下記でも紹介していますので、是非ご覧ください。
【ITmedia連載】IT部門のためのアナリティクス入門
【関連ブログ】
これが、Hadoopにおいて、セルフサービス・データマネージメント(データ準備)ツールが不可欠な理由です。SASはアナリティクスのソフトウェアベンダーとして、このHadoop上でITスキルの高くない分析者・データサイエンティストでも自分自身で自由にデータを取得できるツールを開発し提供しています。それが、SAS Data Loader for Hadoopです。
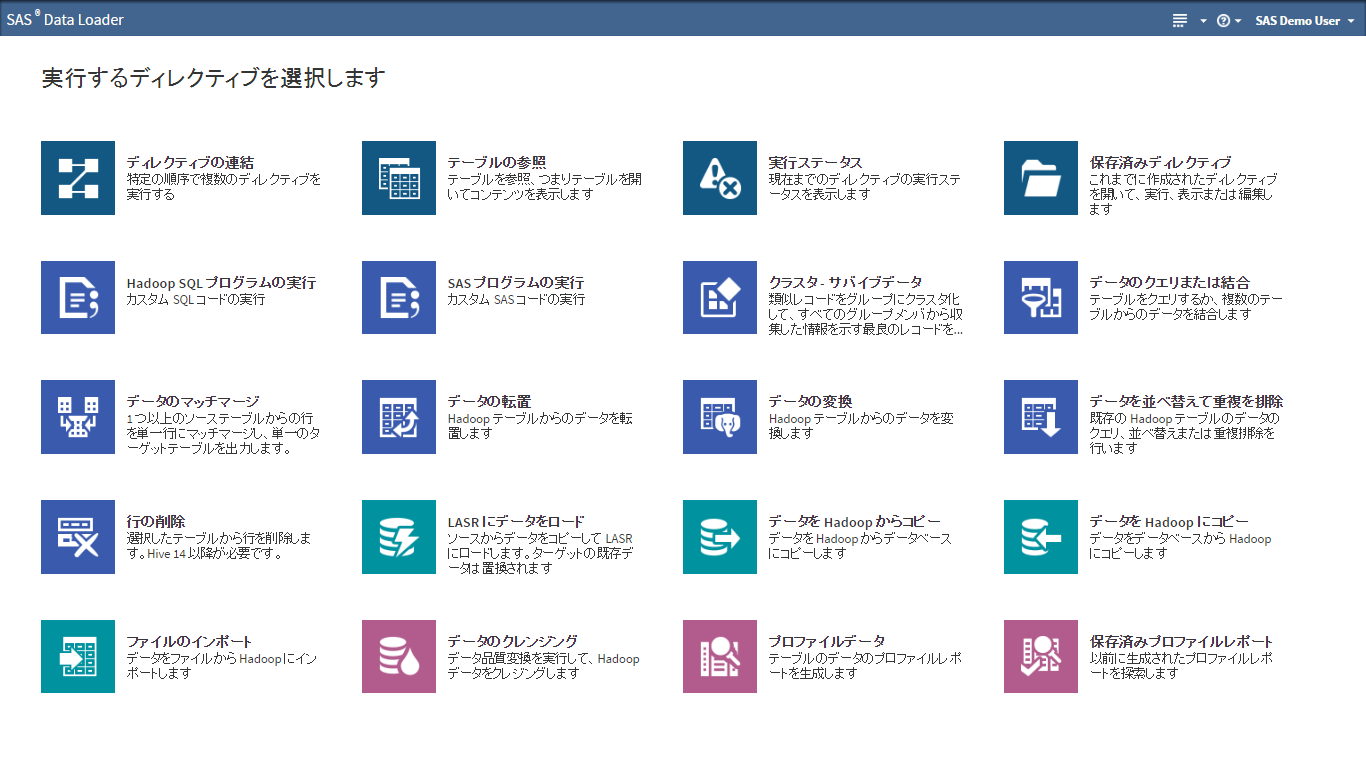
SAS Data Loader for Hadoop最新版リリース
さて、このSAS Data Loader for Hadoopの最新バージョンがリリースされ、関連するSAS Data Management製品もアップデートされました。今回は、その特徴の概要をご説明します。
【日本語字幕】動画によるSAS Data Loader for Hadoop 3.1紹介&デモンストレーション
データアクセス機能の強化
従来のSqoopとOozieを使用したJDBCアクセスに加えて、いわゆるSAS/Access機能を活用可能になったため、以下のデータソースへのアクセスをこのSAS Data Loader for Hadoopでも提供可能になりました。
- Amazon Redshift
- DB2
- Greenplum
- Hadoop
- HAWQ
- Impala
- Microsoft SQL Server
- MySQL
- Netezza
- ODBC
- Oracle
- PC Files
- PostgreSQL
- SAP HANA
- Teradata
- the PI System
- Vertica
ガバナンスの強化
セルフサービス・データ準備作業で作られたデータ加工プロセスをデプロイしたい(バッチ処理化、スケジュール化したい)というユースケースに対応し、強化しました。SAS Metadata アーキテクチャと統合された他、Data Integrationツールである、SAS Data Integration Studioのジョブに、SAS Data Loader for Hadoopで作成した処理を埋め込むことが可能になった他、Data Lineage機能との統合もされたため、バッチ処理化、スケジュール化、影響分析が容易になりました。また、それにより、権限設定などのセキュリティ機能も向上しています。
【参考】
Using a SAS Data Loader for Hadoop Saved Directive in a Job
コラボレーション機能の強化
アーキテクチャを見直し、SASのWebアプリケーションアーキテクチャに統合されたため、複数のユーザーで処理やレポートを共有しやすくなりました。
アダプティブ・データマネジメントとは
このように、SASのデータマネージメントソリューションは、ユーザーの利用シーンに応じたユーザビリティや機能を提供します。相手がビッグデータであるかないかに関わらず、データサイエンティストが主導することの多い、探索的な要素の強いセルフサービス型のデータマネージメントのシーン、そして、IT部門が担当することの多い、データおよびデータ加工プロセスが管理されたバッチ処理のシーン、SASはそのどちらにも対応しており、かつ、それらをシームレスに連携することができ、セキュリティ機能や開発時のコラボレーション環境を提供します。セルフサービス型で作成されたデータ加工プロセスの一部は、かならずガバナンス配下でスケジュール実行することになります。このように、従来の様に、IT部門が使うための、データ統合やマスターデータ管理などの業務に特化した用途ではなく、ビジネスユーザーが使うことまで視野に入れた、利用コンテキストに応じて必要な機能を網羅的に提供できるのが、アダプティブ・データマネージメントです。
[Tweet "分析者による発見・探索時のセルフサービス・データ加工とIT部門による管理されたデータ統合など状況に応じたデータ管理機能を提供すること、それがアダプティブ・データマネジメントです"]
SAS Data Integration Studioの強化
SAS Data Integration Studioでは、新しいインメモリアナリティクスプラットフォームであるSAS Viya上のデータの読み書きに対応しています。また、Amazon S3(PROC S3), sFTP, Amazon Redshiftへのアクセス、および、Amazon Redshiftでのin-database処理のサポートなど、クラウドデータソースのサポートも強化しています。
【参考】
Using the Cloud Analytic Services Transfer Transformation
Using the sFTP Transformation to Securely Access and Transfer Data
SAS 9.4M4
これらのアップデートは、最新のメンテナンスリリースである、SAS9.4M4で提供されています。SAS9.4M4の新機能全体に関しては、こちらWhat's new Documentの「fourth maintenance release」と記載の箇所をご参照ください。
