Datenmodellierung ist sicher eine der komplexesten Aufgaben beim Aufbau eines Data Warehouse (DWH). Dies liegt vor allem daran, dass in der Phase der Modellierung unterschiedlichste Analyseanforderungen zu berücksichtigen sind. Und teilweise ändern sich diese Anforderungen schneller, als man mit dem Datenmodellieren vorankommt. Aktuelle Gründe für ständige Änderungen sind zum Beispiel DSGVO, IRFS17-Anforderungen, Solvency II, Integration externer Daten in interne Analyseprozesse, Firmenzusammenschlüsse, Änderungen der Geschäftsprozesse, neue Produkte und Dienstleistungen etc. Es gibt also viele Gründe, bei der Datenmodellierung flexibel zu sein.
Eine klassische DWH-Datenmodellierung geht aber davon aus, dass in den verschiedenen Schichten die zu einem bestimmten Zeitpunkt verwendeten Datenmodelle fix sind. Das mag für einen Data Mart durchaus sinnvoll sein, weil dieser – bezogen auf eine konkrete Fragestellung – eine eher „statische“ Sicht auf die Daten bedient. Um die Anwendungen maximal nutzen zu können, sollten ein Data Mart und die zugehörigen Applikationen daher einen zeitlich befristeten, unveränderten Zustand haben.
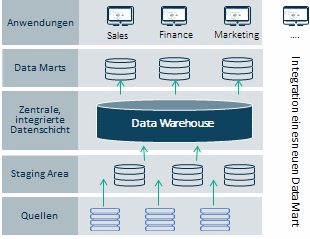
Betrachtet man jedoch die ersten Datenschichten, häufig Operational Data Store (ODS), Staging Area oder Integration Layer genannt, dann handelt es sich hier um eine erste Übernahme der Daten aus den verschiedenen internen und/oder externen Quellen. Wenn neue Daten oder Anforderungen eines neuen Data Mart kommen, dann müssen die Datenstrukturen eventuell angepasst werden. Dies gestaltet sich mit den bisherigen Methoden wie Dritte Normalform (3NF) oder Stern-Schema schwierig. Auch müssen diese Änderungen im DWH widergespiegelt werden, das daher auch laufenden Änderungen unterliegt.
DataVault: Mischung vieler bekannter Methoden
3NF ermöglicht die Verteilung von Informationen zu einer Entität über mehrere Tabellen. Das Stern-Schema bietet Optionen zur Denormalisierung und Zusammenfassung nach Fakten und Dimensionen.
Ein DataVault besteht aus den Elementen Hub, Satellit und Link. Ein Hub nimmt möglichst die eindeutige ID einer Entität beziehungsweise eines Business Object auf. Eine Entität kann dabei ein Kunde, ein Vertrag, ein Schaden, ein Gebäude oder eine Fahrzeugklasse sein. Satelliten nehmen beschreibende Informationen zu den Entitäten auf. Weiterhin können Informationen, die selten bei einer Entität vorkommen, platzsparend in einen Satelliten „auslagert“ werden. Zum Beispiel könnte man bei einer Kfz-Versicherung die Zubehörliste von Fahrzeugen in einen Satelliten auslagern, weil die Anzahl häufig variiert. Eine weitere Unterscheidung kann man mit volatilen und nicht-volatilen Daten machen. So ist bei Personaldaten ein Satellit mit kaum bis wenig wechselnden Informationen, wie etwa Geburtsdatum oder Geschlecht, denkbar. Die Menge an Satelliten ist nicht begrenzt.
Neue Information in den Satelliten
Tritt der Fall ein, dass neue Informationen angebunden werden, erstellt man lediglich einen neuen Satelliten. Ein aktuelles Beispiel hierfür sind die Anforderungen der europäischen Datenschutz-Grundverordnung (DSGVO). Hier sollte zu jeder Entität mit personenbezogenen Daten hinterlegt sein, warum man diese speichert. Die Begründung könnte ein berechtigtes Interesse wie ein Vertrag sein oder dass die Person der Speicherung und Verarbeitung zugestimmt hat. Weiterhin könnte man hinterlegen, wo man zusätzliche DSGVO-relevante Informationen findet. Viele DWHs haben hierfür keine Felder vorgesehen. Eine Erweiterung ist schwer. Ein DataVault-System fügt einen Satelliten hinzu, und schon sind die Informationen ablegbar – ab diesem Zeitpunkt.
Eine Entität wird also im Hub gespeichert. Hubs werden dann über Links verbunden, so dass man Verträge, Schäden, Versicherte etc. zusammenbringt. Ein Satellit darf auch an einem Link hängen und enthält beschreibende Informationen oder historische Daten zu dieser speziellen Verbindung.
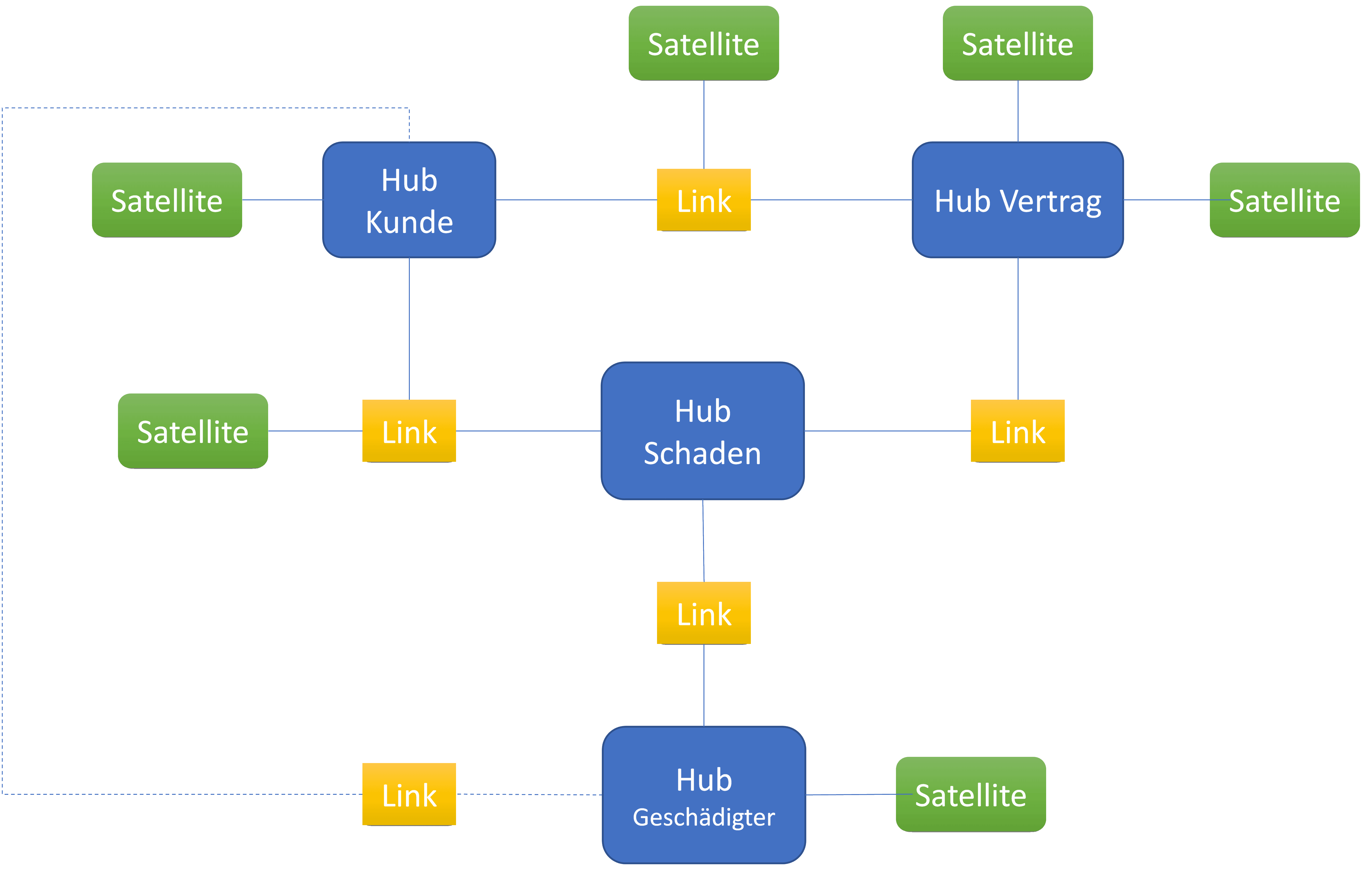
In diesem Fall ist noch zu entscheiden, ob man einen Link zwischen Hub „Kunde“ und Hub „Geschädigter“ benötigt. Wird diese Relation in Analysen berücksichtigt, dann macht es Sinn, diesen Link zu haben. Wichtig hierbei ist, dass es nicht die „eine“ Wahrheit gibt. DataVault-Modelle lassen sich vielfältig modellieren. Das Laden der Datenmodelle übernehmen häufig generierte Programme, die auf Basis von Metadaten erstellt werden (bei SAS klassisch SAS Macros). Ein Verfahren, das viele SAS Base-Entwickler kennen.
Allgemein kann das Vorgehen folgendermaßen beschrieben werden:
- Beschreibung der Quelldaten
- Erstellung einer DataVault-Beschreibung
- Definition, wie die Daten aus dem Quellsystem 1:1 in das DataVault zu laden sind. Transformationen finden hier nicht statt – diese erfolgen in den nachfolgenden Schritten.
- Entweder werden nun aus dem DataVault Data Marts einschließlich entsprechender Businesslogiken erstellt, oder man nutzt die Möglichkeit von virtuellen DWHs, um aus den dynamischen DataVaults ein System zu machen, das die Änderungen durch Views an die weiteren Schichten weiterleitet. Dabei bleiben bestehende Views unverändert, so dass bisherige Ladeprozesse für Data Marts nicht angepasst werden müssen. Als Produkt eignet sich hierzu der SAS Federation Server sehr gut, da er eine skriptbasierte Erstellung von Views erlaubt, wie es bei DataVaults üblich ist.
- Werden vereinfachte Modelle inklusive Businesslogik zur Weitergabe an mehrere Data Marts benötigt, dann erstellt man einen entsprechenden Business-Vault.
Idealfall für agile Entwicklung
DataVault erfreut sich in letzter Zeit großer Beliebtheit. Dies liegt vor allem daran, dass ein Datenmodell nicht erst komplett durchmodelliert werden muss, bevor man es anwenden kann. Es ist ausreichend, wenn man genau die Daten erfasst hat, die man für sein erstes Projekt benötigt. Damit ist DataVault auch ideal für eine agile Entwicklung im analytischen Umfeld.
Nach der Modellierung einer Entität – zum Beispiel Kunde – und dem Hinzufügen der beschreibenden Daten können die ersten Berichte und Analysen angefertigt werden. Sobald die nächste Entität – zum Beispiel Vertrag – modelliert ist, können alle Analysen bezogen auf „Kunde“, „Vertrag“ und „Kunde + Vertrag“ analysiert werden.
Ein weiterer Grund für die Beliebtheit von DataVault ist, dass auch Fachbereiche der Modellierung leicht folgen können, weil die Entitäten nah an ihren Anforderungen modelliert werden. So kann im Vergleich zu 3NF oder dem Stern-Schema der Fachbereich viel leichter in die Modellierung involviert werden.
Und so sieht das in der Praxis aus
Nach der Theorie möchte ich nun Niko von unserem Partner 29Forward befragen, der schon ein entsprechendes System bei einem Kunden mit SAS umgesetzt hat.
Niko, schön dass Du Dir die Zeit genommen hast, uns etwas von Deinem Projekt zu erzählen. Kannst Du bitte zu Beginn kurz das Business beschreiben, welches mit dem Projekt bedient wird?
Ja, sehr gern. Unser Kunde war eine mittelständische Bank in Nordrhein-Westfalen. Da es erst mal um die Datenbasis ging, war unser direkter Auftraggeber das BICC.
Warum brauchte der Kunden ein neues Datenmodell?
Zunächst einmal wegen „gewachsener“ Strukturen. Es gab keinen sog. Single Point of Truth. Viele Berichte an den Fachbereich wurden nicht aus einem DWH gespeist, sondern durch händische Eingaben oder Dokumente am bestehenden Datenpool vorbei. Das bestehende DWH war eher ein Abbild des Kernbanksystems ohne Verbindung zu anderen operativen Systemen. Das war im Laufe der Zeit so unübersichtlich geworden, dass eine klare Lösung hermusste.
Warum hat man sich für DataVault als Modellierungsmethode entschieden?
Hauptsächlich, weil DataVault so gut skaliert. Man kann mit einer kleinen Modellierung anfangen, das Modell aber auf dem Weg auch direkt erweitern und um weitere Informationen ergänzen. Die Schlankheit der Objekte und grundlegende Einfachheit sprachen auch dafür. Zuletzt dann auch die Tatsache, dass man DataVault automatisch hervorragend parametrisiert erstellen kann. Und das wiederum geht mit SAS sehr gut.
Warum hat man sich für SAS als Tool entschieden? Beschreib doch bitte auch, welche Produkte zum Einsatz kommen und warum genau diese Produkte genommen wurden.
SAS war im Unternehmen bereits im Einsatz – und zwar in Form von SAS Base 9.4, SAS Office Analytics Server und SAS Visual Analytics. Programmiert haben wir mit dem SAS Enterprise Guide, weil man hier komfortabel Ergebnisse prüfen, Logs auswerten und Tabellen beladen kann.
Welche Vorteile hat aus Deiner Erfahrung die Nutzung von SAS im Zusammenhang mit DataVault-Systemen?
Bei dem Projekt haben wir mit sehr einfachen Mitteln ein komplettes DataVault mit 62 Hubs, 72 Links und 169 Satelliten gebaut. Die Steuerung des Vault und auch einer neu erstellten Stage 0 erfolgte komplett über eine Excel-Datei, in der alle Informationen enthalten waren. Beim Laden eines Vault gibt es (zumindest auf diesem Layer) eigentlich keine Abhängigkeiten. Dennoch musste der Stage 0 Layer so integriert werden, dass ein reibungsloses Laden gewährleistet war, sobald die Daten aus den Quellsystemen zur Verfügung gestellt wurden. Auch diese Abhängigkeitsinformationen waren in der Excel-Datei hinterlegt. Dieses Herzstück wurde dann von wenigen, sehr gut durchdachten SAS Programmen begleitet, die im Batch jede Nacht die Beladung des RawVault übernommen haben. Ein Programm konnte jeden Hub beladen; das Gleiche galt für Links und Satelliten. Voraussetzung dafür waren SAS Macro und eine durchdachte Parametrierung. Im Vault werden Schlüssel stets über einen Hash-Wert abgebildet. Dafür kennt SAS bereits die Funktion SHA256, die zudem das Risiko einer Hash Collision deutlich reduziert. Da der Betrieb später eine reibungslose Beladung des DWH sicherstellen muss, kann man die SAS Programme auch direkt mit einem Monitoring ausstatten; Fehlerfälle lassen sich dann beispielsweise mit einem Mailing darstellen. Runtimes und geladene Observations haben wir direkt in eine übersichtliche SAS Tabelle gesteckt. Mit einfachen SQL-Strukturen lässt sich zudem das Entstehen von Hash Collisions überwachen.
Würdest Du Dein nächstes DataVault-Modell wieder mit SAS machen?
Ja, auf jeden Fall. Es gibt noch einige Fallstricke, aber da wir die jetzt kennen, wird es umso leichter. Zum Beispiel werden Hash-Werte im EG manchmal als „missing“ dargestellt. Sie fehlen aber nicht.
Was würdest Du evtl. anders machen?
Wir haben das initiale Datenmodell auf dem semantischen Modell des Business angefertigt. Im weiteren Verlauf haben wir gelernt, dass die Daten aber nicht so stringent und einfach vorliegen oder uns sogar zu Kapriolen zwingen. Dazu gehört, dass Datenlieferungen gänzlich ohne Datumsfelder erfolgten oder Daten erst vereinigt werden mussten. Daher kann man den Weg zwar so gehen, aber einfacher ist es sicherlich, wenn man sich einzelne Bereiche aussucht und diese gezielt abarbeitet.
Gibt es noch weitere Tipps, die Du anderen DataVault-Entwicklern mit auf den Weg geben möchtest?
Kenne deine Metadaten und erstelle Dir eine möglichst einfache Übersicht dazu. Und egal, ob die Informationen dazu aus einem Modellierungstool oder händisch eingegeben werden: Ein Prüfprogramm vor dem Einlesen ist stets seine Entwicklungszeit wert. Es gibt so viele harte Regeln im Vault, da kann man einiges prüfen.
Für Beladungsanalysen ist es hilfreich, dass man im Satelliten den zugehörigen Business Key auch speichert.
Als abschließenden Tipp kann ich noch verraten, dass es hilfreich ist, alle Quellen frühzeitig zur Verfügung zu haben und mit einem guten Auge zu analysieren. Dann bleiben einem Überraschungen erspart, und man muss nicht im Projekt darauf warten.
Vielen Dank, Niko, für Deine Zeit und dass Du Deine Erfahrungen mit uns geteilt hast. Ich wünsche Dir weiterhin viel Erfolg und Spaß bei der Nutzung von SAS bei Deinen DataVault-Projekten.







