There aren’t many things that keep me awake at night but let me share a recent example with you. I’ve been grappling with how to help a local SAS team respond to a customer’s request for a “generic enterprise analytics architecture.”
As background, this customer organization had recently embarked on an initiative to re-engineer their entire data landscape involving a multi-year contract with a technology provider to deliver a new landscape involving multiple data stores (Hadoop and merchant RDBMS), ETL tooling and metadata management. It was evident that a lot of thought had been put into this new landscape, reflected in the myriad of design patterns and data flow documents that were shared with us. Their objective was clear: build infrastructure to deliver data with known provenance, (preferably high) quality and lineage with accompanying governance.
patterns and data flow documents that were shared with us. Their objective was clear: build infrastructure to deliver data with known provenance, (preferably high) quality and lineage with accompanying governance.
The organization already uses SAS technology and solutions which have been deployed by individual departments and units and it is encouraging that the customer was keen to solicit a SAS opinion on a new, vendor-neutral analytics architecture which naturally would be built upon the revised data landscape.
What is an analytics architecture?
Except, in my mind, it’s not so easy to describe an analytics architecture in the same way that you can represent the flow of data across the enterprise. A quick trawl on the Web unearths plenty of diagrams of what I regard as primarily data architectures with a sprinkling of analytic terms that don’t really address the challenge. You’re welcome to disagree with me here and indeed the enterprising local SAS team used their initiative to source some anonymized real-world architectures deployed by other customer organizations to fulfill the original requirement.
Here’s my take on this requirement. At a high level, the graphic below does an excellent job of highlighting the three key activities in an analytics lifecycle. Indeed this customer’s investment sequence makes sense, which I presume was, “Let’s get our data sorted, then we can re-visit how we deploy our analytics.” For me, the challenge remains on how to represent the remaining two activities in a generic, vendor-independent way.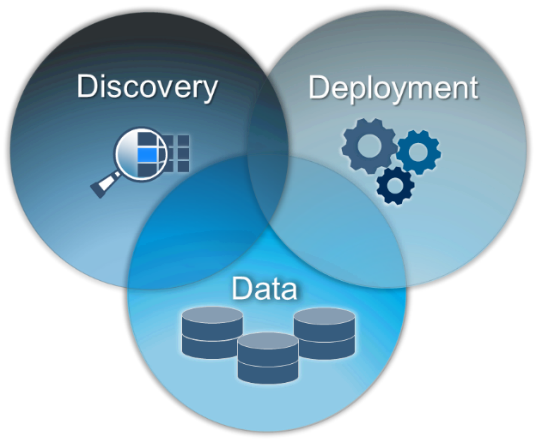
As a related aside, in my experience, organizations focus on implementing the discovery activity but tend to ignore the deployment component or leave it as an exercise for later. This can be a major pitfall because unless you can make decisions based on analytics insight, the impact is lost.
Increasingly, I find the bottleneck to analytics modernization is related to deployment and the inability to quickly and efficiently implement the results of analytics into core business activity. Rather like how the Channel Tunnel was built (that’s to say digging teams started from both France and England), when you perform analytics, you need to keep an eye on how you are going to deploy the eventual result.
Design principles for an analytics architecture
So, rather than answer the original exam question to define a generic analytics architecture, my approach is to offer the following design principles (tailored here for a Hadoop infrastructure):
- Implement GUI interfaces rather than programming to aid productivity and allow new users to quickly embrace new tooling (mindful that some analyst roles will continue to prefer the coding paradigm).
- Minimize data movement for analytics. Aim to perform analytics against data in situ.
- Wherever possible leverage the Hadoop platform to deliver parallelism of analytic processing.
- Perform analytic processing in-memory, since it generally will be faster than other methods. In-memory may impose constraints on the size of data set, which can be accommodated.
- Consider the complete analytics lifecycle from creation to deployment. Avoid conversion of predictive models or business rules when deploying for execution. When selecting analytical tooling, consider how models can be deployed: if the tool doesn’t support deployment of models/logic without change, then consider alternatives.
- Use in-built Hadoop facilities wherever possible. Note there is no guarantee that in-built facilities are inherently superior to commercial products. You need to perform due diligence in such selection, mindful of principles #1-4 above.
- Encourage commercial tooling to use standard Hadoop capabilities (why reinvent the wheel if you can use in-built facilities?). As an example of this ethos, SAS Data Loader for Hadoop employs Apache Sqoop and Oozie components for some operations.
In addition, I recommend combining those design principles with a set of common-sense questions, which should be posed for every use case:
- Data volume – two dimensions: how much data is there to analyse & what is the anticipated size of the result set?
- Where is the input data located? (Enterprise Data Warehouse, Hadoop, operational data source or elsewhere?)
- End user requirement: do you need a product (GUI) or simply a programming API?
- Is the data at rest or in motion?
- What’s the arrival rate? 00s events/sec is very different from millions events/sec.
- How quickly do you need the result? Milliseconds, overnight?
- What analysis is needed and an assessment of its complexity?
- What platform is needed? MPP or SMP? Based on volume, complexity & target completion period.
- Where will you deploy the result?
- How will you deploy analytic output (score/model/business rule) on the target system?
Specifically for the deployment activity, I offer another shorter set of considerations:
- Recognize the potential need to cater for batch, real-time & in-motion (streaming).
- Know the difference between responding in real-time and analytic processing on data in-motion.
- Understand characteristics of the data before you can deploy.
- Realize that Hadoop is unlikely to be used for anything other than batch (today, at least).
- Aim to deploy business rules or analytic models as-is, whenever possible (avoid recoding which introduces delay, complexity and potential for error).
- Consider the task in-hand: match the complexity of analytics/rules to the transaction volume/desired response time.
These tips are neither comprehensive nor exhaustive but they’re a good start. Granted, this isn’t an architecture per se, but armed with these guidelines, I think any experienced architect has a better chance of delivering an effective design.
With reference to the original request, I’m pleased to say the customer is happy with what we’ve delivered and the work effort now is to decide how to integrate existing departmental SAS deployments into the new enterprise environment. It’s probable I was over-thinking the generic aspect of the requirement which was eventually solved by some lateral thinking by my SAS colleagues. That said, I remain convinced that a meaningful analytics architecture is best crafted around existing and prospective uses cases, underpinned by a set of design principles.
To learn more, download the white paper, "Operationalizing and Embedding Analytics for Action." And if you have any thoughts or experiences of putting an analytics architecture together, I'd love to hear about them in the comments.

1 Comment
In these days of Brexit, I like your metaphor for two teams (IT and business) starting on opposite sides of the (information) channel and hoping that they come together in an optimized, or at least rudimentally functional middle. Less sure about having the entire organization dependent on GUI's as this would inevitably slow down some innovations. Fully agree that moving analytics closer to the data is key to performance, efficiency and consistent organizational strategy execution.
Nice one, Paul!