Working out where Hadoop might fit alongside, or where it might replace components, of existing IT architectures is a question on the minds of every organization that is being drawn towards the promises of Hadoop. That is the main focus of this blog along with discussions of some of the reasons they are drawn towards Hadoop.
For the past 12 months, I have spent a great deal of time speaking to organizations that were either thinking about adopting Hadoop as a data platform or were already well underway with their Hadoop journey. During this time, I have heard two core arguments as to why people want to adopt Hadoop: cost and agility. Perhaps unsurprisingly if you talk to those that have implemented, they often tout the same two things as the benefits of having adopted Hadoop. Lets dig into both.
Cheaper in many ways
The most frequent argument I hear is that using Hadoop as a data platform is economically efficient. I am consistently told that the cost of the software and support, per node or CPU, is significantly cheaper than almost every relational database management system (RDBMS) on the market by those who have adopted it. In addition, they tell me that the commodity hardware used by Hadoop is always a lot cheaper than the hardware organizations are advised to use in support of an RDBMS or a specialty appliance. One reason for the cost reduction is that redundancy is built into the system with Hadoop, so you do not need to worry too much about things such as redundant power supplies or disks, as a failed node in Hadoop is not a big deal.
In addition, many Hadoop users cite the fact that you can just upgrade disk and memory on nodes pretty much independently of the software licenses and other formalities as a major benefit. Likewise, I'm told, if an organization wants more CPUs in their Hadoop cluster, to aid with increased processing capability, it would not result in a rather significant and unrequired additional RDBMS license cost so incremental upgrades do not break the IT budget and are pretty predictable.
In adopting Hadoop as a data platform, organizations are hoping to slow down the burgeoning RDBMS growth, which is now starting to be a significant cost for many organizations, or to entertain the idea of taking the RDBMS out of much of the picture as data volumes grow except where it is really needed. Hadoop is seen as the route to cost effectively implement a data platform that is capable of handling the current explosion in data volumes and the continued acceleration of data that is expected with the Internet of Things.
Not all the organizations I have worked with have an eye to the future. Many feel they can get great cost savings from Hadoop by changing the way they handle todays data volumes.
Beyond the storage, software and hardware costs, there is an oft cited view that you can lower the cost of managing your data by implementing Hadoop. Users claim it is easier to load data into Hadoop as it can be loaded independent of format and structure. Often refered to as schema on read, the feeling is that this means there is no delay in data modelling and "flow building" to make data availible for those who are going to consume it. While for certain users this might be appealing and true, for the majority there will still need to be some schema produced that they can consume downstream, so the cost will still exist to some degree. But agility will be enhanced, which leads us to our next point.
Greater agility
When we talk about agility there are really two dimensions I have heard:
- Hadoop provides a way to start using the vast amount of unstructured and semi-structured data that organizations have ,which many feel does not make economic sense to handle in an expensive RDBMS even if they could handle it well there.
- The schema on read capability is also an agility story. The intention of this functionality is to shift modelling efforts to the point of consumption. Schema on read allows IT to work with business users to define the model as the business issue arises, rather than solving for it up front. The agility comes because IT does not need to update a big, central model and then build the flows of data in before they can meet the business need. In most cases meeting the business need requires a specialized schema anyway (even if it materialized through a view/virtualization). The schema on read means that new data can be moved into Hadoop and exposed to the business without too big of an effort or a massive time lag.
The jury is still out in my mind regarding these changes, but there are many businesses that are seriously exploring this option with business agility as the core driver.
Three use cases for Hadoop as a data platform
While every organization is different, I have observed a few common scenarios in action for Hadoop. Typically, these occur when organizations have focused on using Hadoop as a data platform alongside the traditional approach that most organizations have in use today.
- Hadoop as a new data store.
- Hadoop data platform as an additional input to the enterprise data warehouse.
- Hadoop data platform as a basis for BI and analytics.
Let's look at each use case and how IT teams might assess suitability. Different models will work best for different organizations. I am not sure there is a right or a wrong answer at a generic level.
1. Hadoop as a new data store
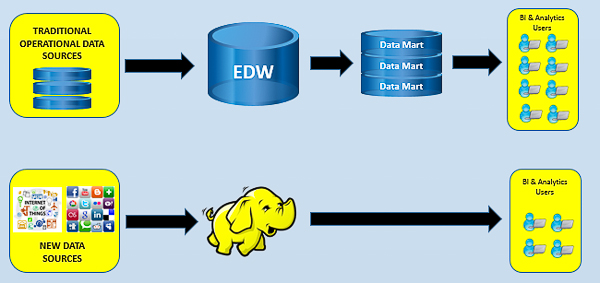
In this scenario, organizations are looking at Hadoop to handle new types of data that are not yet currently under the control of the Enterprise Data Warehouse (EDW). This includes unstructured data, semi-structured data or data that is “not yet known to be useful.” Organizations like this approach as it does not impact existing warehouse or mart efforts but it allows them to use a low cost approach for extracting value from data that they already have but might not be using.
In general, organizations deploying this approach see Hadoop as a way to support innovative business strategies that require new data, or as a way to get existing unstructured and semi-structured data into one governed location at the lowest cost. When you dig beneath the surface of this type of approach there are often only a small number of users operating against Hadoop.
2. Hadoop data platform as an additional input to the enterprise data warehouse
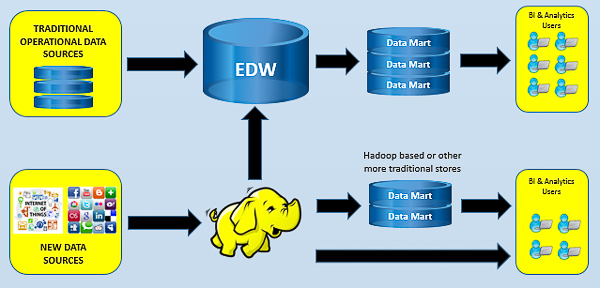
In this scenario, I see organizations using Hadoop to handle new types of data, as in the last scenario, but then feeding the newly discovered insights into the Enterprise Data Warehouse (EDW) for mass consumption. In this model, Hadoop is used as the low cost platform to uncover new insights from unstructured, semi-structured and not yet known to be valuable data. The existing EDW process is not impacted but extra data flows are often put into place from Hadoop when there is something valuable discovered that needs exposing to the masses. Essentially, Hadoop complements the rest of the data strategy and the EDW remains the single source of data for most users even if they access it via a downstream mart. The side effect of this is that the EDW will grow and that often results in extra costs in that part of the landscape.
Earlier, I mentioned that when something valuable was found in Hadoop it may be added to the EDW. In this scenario, many organizations are discovering things that are useful through the use of business intelligence (BI) and analytics. Sometimes that BI and anayltics is executed directly against Hadoop and sometimes organizations have done some data transformation back out of Hadoop into an RDBMS or other valid data store where people will then work.
This is why some companies have more structured marts in Hadoop, as depicted in this image, for analysis (The marts could be stored in HIVE, Cloudera Impala, Pivotol HAWQ or even an applicance/RDBMS/SAS). With the technologies that are available today this seems like overkill to me, but it is a scenario I have seen. The number of users against Hadoop in this case is increased over the first scenario but the data being put into Hadoop may still not be exposed for the masses.
The real idea here is to contain the cost of a burgeoning EDW by simply not throwing all the new data directly into it but waiting until you know the data is useful for the masses. Secondly the hope seems to be that this new environment will provide the organization a very low cost way to incubate innovative business strategies that often require massive volumes and varieties of data which once proven might be supported in a more "robust" and costly EDW. The ultimate goal is to move only what is valuable to the relatively expensive EDW store while not disrupting what is in place today.
3. Hadoop data platform as a basis for BI and analytics
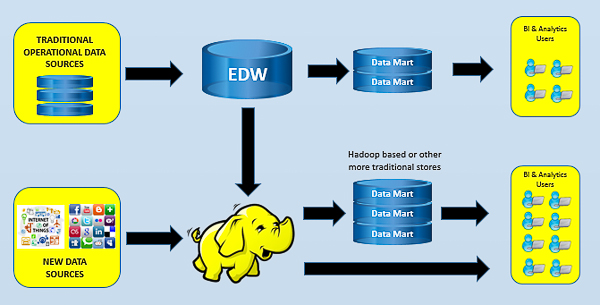
In this scenario organizations are adopting Hadoop with the view to make it the main store for all things BI and analytics. EDW processes are largely untouched but extra flows are added to copy a lot of EDW data into Hadoop, where it will be complemented with additional data that never flows through the EDW. This can result in a reduction in the size of the EDW or simply a slowing of the growth.
What this means is that the EDW can continue to support important tasks like regulatory reporting. In addition, any systems in place that currently require the EDW will continue to operate without any real change. However, most BI and analytics tasks beyond that might start to be moved to operate on the Hadoop store. Many organizations find benefit in analyzing from Hadoop because it contains more cross system data than the EDW and greater data volumes with far more history. Plus, it can contain data at a more detailed transactional level as opposed to the highly aggregated view we often see in the EDW.
Because of this it is possible to run reporting processes across huge volumes of data with more history and to develop analytical models at a greater level of data granularity with more history, perhaps for later operational deployment to an EDW or other operational application. What is essentially happening here is that companies are looking to offload analytical processing and reporting from the EDW towards Hadoop. Hadoop becomes the single source for most users even if they access it via a downstream mart.
Looking ahead
These three scenarios show how Hadoop is being put into play around the existing EDW processes or to handle new emerging data sources. If you like, these are the three least controversial scenarios. I am often asked which one is the right one. While some people might quickly come up with an answer, especially if they have a vested interest in one part of these diagrams, I believe the right answer lies in what you are trying to achieve, what your data will be being used for and what your plans are for the next years. What is certain is that Hadoop will have a role to play!
So what about this concept of a "data lake" you have no doubt heard about? You'll have to read my next blog to get my view on that, but it is clearly something many organizations are looking at as a future state architecture although I have not yet seen it widely deployed unlike the three scenarios above.
If this blog was interesting be sure to look at the previous two blogs in the seried that can be read by following the links below:
- Hadoop Market Growth: Breaking out of the Silicon Valley Bubble
- How Hadoop emerged and why it gained mainstream traction
In addition you can read what the independent industry analyst TDWI says about utilizing big data analytics with Hadoop.

3 Comments
Haddop definetely complements and in many ways it enriches your EDW. Companies still need structured data for their analysis needs.
Very interesting and relevant article.
I should point out that the ultimate goal is a decision-driven business. DWH and "Big" Data (Hadoop) are mere tools to answer different kind of questions.
Both toolsets should naturally coexist, but I believe the real challenge fur businesses is the implementation of a data science practice and the valuation of data as a strategic asset.
Without this practice, there are quite some data governance chaos ahead (eg the data lake "promise").
Pingback: 3 ways to use Hadoop without throwing out the DWH