Jakość danych syntetycznych zależy przede wszystkim od jakości modelu, który je wygenerował, oraz – rzecz jasna – reprezentatywności i jakości danych pierwotnych. O ile ta druga kwestia, jako dobrze znana każdemu analitykowi danych, nie wymaga dalszego komentarza, o tyle kwestii jakości modelu warto poświęcić dodatkową uwagę.
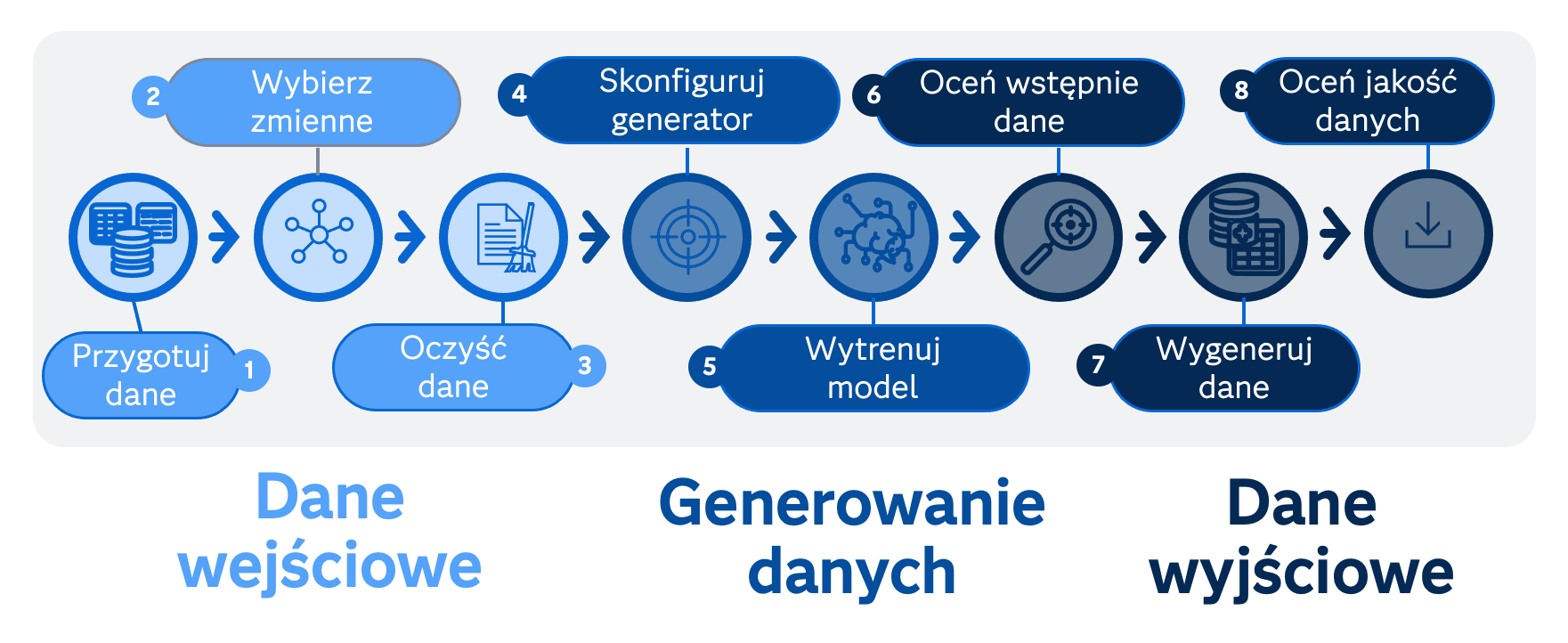
Rysunek 1. Procedura generowania danych syntetycznych z uwzględnieniem oceny jakości danych.
W zasadzie mamy tu na myśli nie tylko sam model (algorytm) sensu stricto, ale raczej całą procedurę, która umożliwi nam wygenerowanie dobrej jakości danych syntetycznych. Ich pozyskiwanie wymaga bowiem dodatkowych kroków weryfikacyjnych, takich jak wszechstronne porównanie wyników modelu z danymi z realnego świata (danymi pierwotnymi). Przykładowe etapy takiej procedury zaprezentowano schematycznie na rysunku 1 oraz w postaci praktycznej implementacji diagramu przepływu (flow) w narzędziu SAS Studio na platformie SAS Viya na rysunku 2.
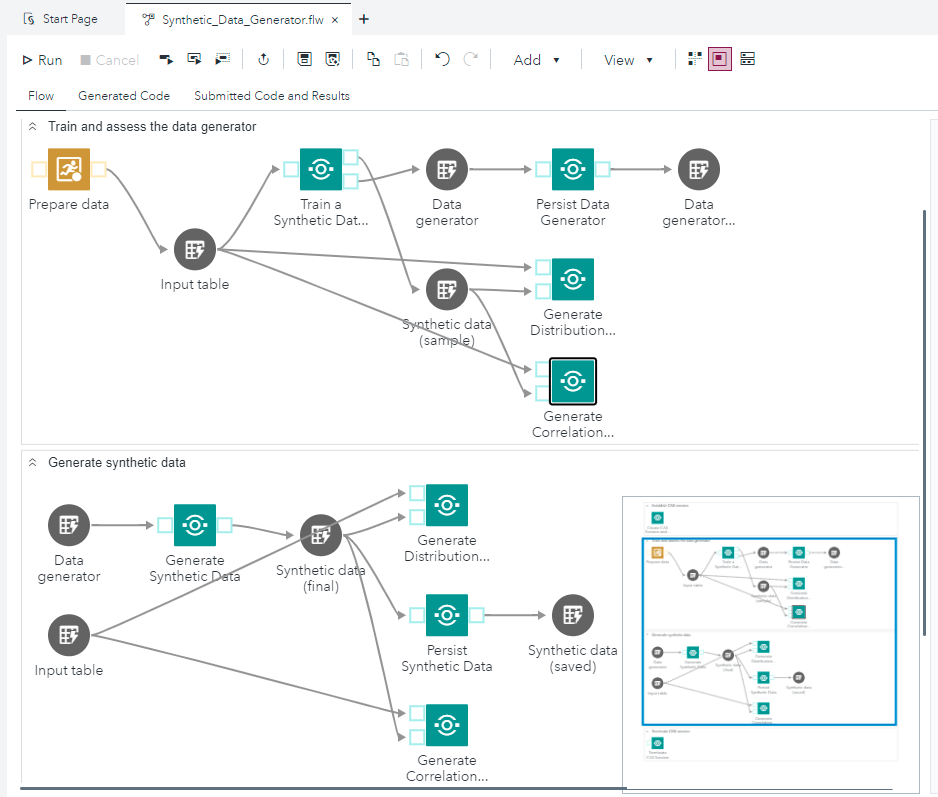
Rysunek 2. Przykład praktycznej implementacji generatora GAN na platformie SAS Viya przy użyciu gotowych węzłów udostępnianych przez SAS w serwisie Github.
Model SMOTE
Jeżeli chodzi o metody generowania danych syntetycznych, obecnie najpopularniejsze są dwie techniki bazujące na odmiennych założeniach, znajdujące zastosowanie do rozwiązywania specyficznych problemów zidentyfikowanych w rzeczywistych (pierwotnych) danych. Pierwszą z nich jest SMOTE (Synthetic Minority Oversampling Technique) zaproponowana w 2002 roku (Nitesh V. Chawla i in.)[1] – metoda nadpróbkowania (oversampling) stosowana przede wszystkim do rozwiązywania problemu niezbilansowanych zbiorów danych. Idea tej metody jest prosta: losowo wymieramy próbkę i jej k najbliższych sąsiadów pochodzących z tej samej klasy (grupy, warstwy), po czym generujemy syntetyczne obserwacje poprzez interpolację między wybraną próbką i jej sąsiadami. Uzyskujemy w ten sposób obserwacje zbliżone do pierwotnych, choć różniące się w szczegółach. Ideowo metodę tę przedstawiono na rysunku 3.

Rysunek 3. Idea metody SMOTE.
Sieci GAN
Druga metoda, o potencjalnie wszechstronniejszym zastosowaniu, wykorzystuje sieci GAN (Generative Adversial Network) – w tym przypadku w pełnym tego zwrotu rozumieniu wykorzystujemy generatywną sztuczną inteligencję do tworzenia danych syntetycznych (które w szczególności mogą być użyte do… trenowania modeli generatywnej AI). Metoda ta została zaproponowana w 2014 roku (Ian Goodfellow i in.)[2], a więc jest o kilkanaście lat młodsza od techniki SMOTE. Oryginalnie wykorzystywano ją z dużym sukcesem do przetwarzania obrazów (w tym generowania realistycznych translacji, wypełnień (inpainting) itp.), lecz z czasem pewne jej modyfikacje zaczęto stosować do generowania syntetycznych danych w standardowej postaci tabelarycznej.
W szczególności model CPCTGAN (Correlation-Preserving Conditional Tabular GAN) został stworzony w celu jak najlepszego przezwyciężenia typowych problemów związanych z przetwarzaniem danych w postaci tabelarycznej – takich jak konieczność jednoczesnego modelowania zmiennych dyskretnych i ciągłych, wielomodalne wartości niegaussowskie w obrębie każdej zmiennej ciągłej czy istotne niewyważenie zmiennych kategoryzujących – a przy tym zachowania podstawowego kryterium jakości danych, jakim jest odzwierciedlenie współczynnika korelacji (liniowej) między parami zmiennych w zbiorze pierwotnym. W tym podejściu ocena jakości danych (etapy: 6 i 8 na rysunku 1) sprowadza się więc przede wszystkim do analizy rozkładów i korelacji między zmiennymi. Jak pokazuje praktyka, metoda ta jest w stanie wygenerować dane syntetyczne w praktyce nieodróżnialne – z punktu widzenia tych kryteriów – od danych rzeczywistych.
Proces uczenia
Jeśli pominąć szczegóły, o których wyżej mowa (będące odpowiedzią na wyzwania danych w postaci tabelarycznej), zasadnicza idea modeli opartych na sieciach GAN jest o tyle interesująca, iż można ją wyrazić w języku teorii gier, sprowadzając jej przebieg do rywalizacji dwóch graczy – Generatora i Dyskryminatora – która trwa do momentu osiągnięcia równowagi. Generator i Dyskryminator to dwie sieci neuronowe odgrywające w tej rozgrywce odrębne, choć istotnie uzupełniające się, role. Generator generuje syntetyczne dane w oparciu o podany na wejściu szum (dane losowe z wybranego rozkładu a priori, zwykle jest to szum gaussowski) i nigdy nie „widzi” danych rzeczywistych. Jego zadaniem (ostatecznym celem) jest wygenerowanie danych syntetycznych o cechach danych rzeczywistych (pierwotnych). Z kolei Dyskryminator, wytrenowany zarówno na danych rzeczywistych jak i syntetycznych (pochodzących od Generatora), szacuje prawdopodobieństwo tego, że dane podane mu na wejściu są rzeczywiste lub syntetyczne (nierzeczywiste), w ostatecznym rozrachunku mając za zadanie odrzucenie (czyli niejako dyskryminację – w rozumieniu statystycznym również: oddzielenie) danych syntetycznych. Jest więc de facto sigmoidem dającym odpowiedź trochę na wzór regresji logistycznej używanej chociażby do budowy kart scoringowych (które też są odmianą klasyfikatora/dyskryminatora uczącego się odróżniać dwie populacje, np. w bankowości czy marketingu klientów „dobrych” od „złych”). Trenowanie Generatora odbywa się na podstawie błędu Dyskryminatora, a całość rozgrywki sprowadza się do osiągnięcia punktu siodłowego (stanu równowagi między Generatorem a Dyskryminatorem) w grze typu minimax. W sposób schematyczny przebieg całego procesu od strony operacyjnej przedstawiono na rysunku 4.
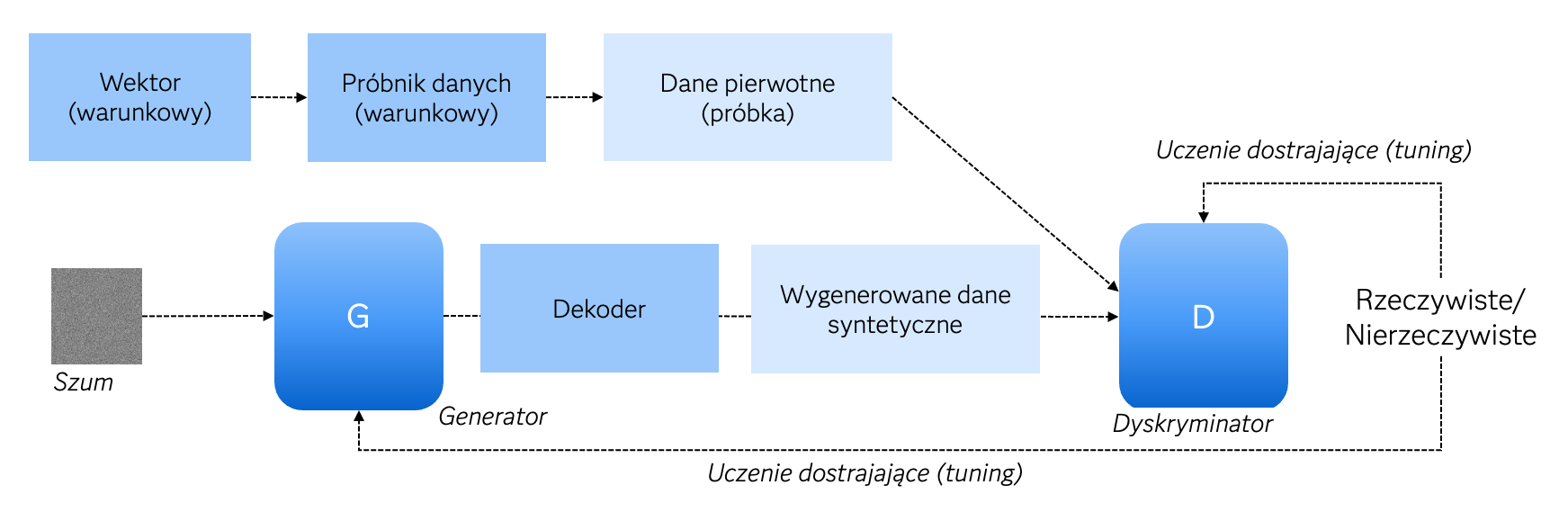
Rysunek 4. Schemat działania generatora danych syntetycznych opartych na sieciach GAN.
Dane syntetyczne bez kodowania
Modele SMOTE oraz CPCTGAN dostępne są na platformie SAS Viya. W celu ułatwienia ich praktycznych zastosowań, firma SAS przygotowała gotowe do wykorzystania w narzędziu SAS Studio węzły (nodes), z których użytkownicy platformy SAS Viya mogą budować własne przepływy danych w podejściu low-code/no-code. Węzły te wraz z towarzyszącymi im instrukcjami dostępne są w serwisie Github:
- Generowanie danych syntetycznych przy użyciu metody SMOTE
- Trenowanie generatora danych syntetycznych przy użyciu sieci GAN
- Generowanie danych syntetycznych przy użyciu sieci GAN
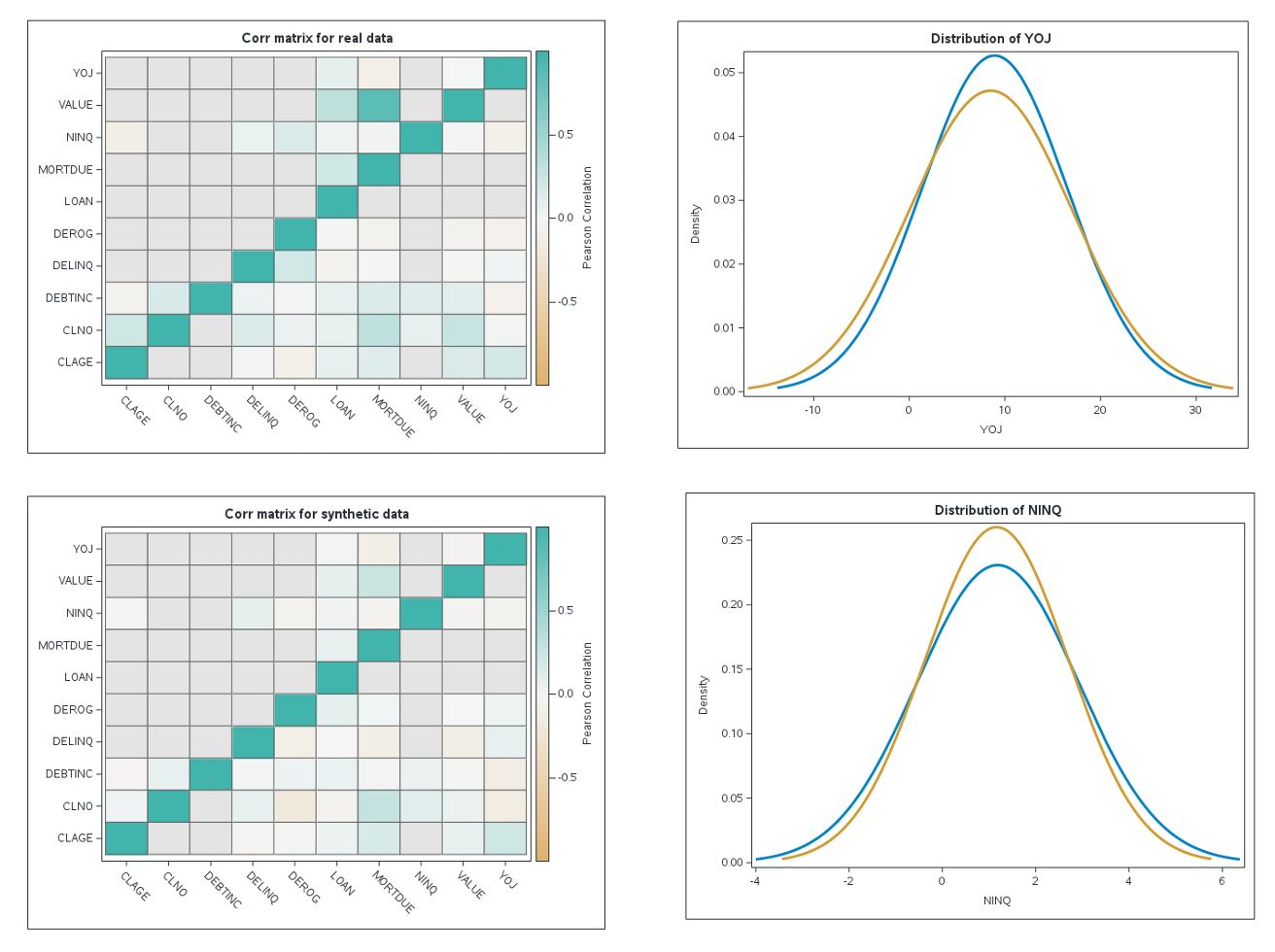
Rysunek 5. Przykładowy zestaw danych wynikowych dla metody opartej na sieciach GAN.
[1] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., ... & Bengio, Y. (2014). Generative adversarial nets. Advances in neural information processing systems, 27.
[2] Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer, W. P. (2002). “SMOTE: Synthetic Minority Over-sampling Technique.” Journal of Artificial Intelligence Research 16:321–357
