When I decided to major in Statistics, my dad was worried that I wouldn’t be able to find a job except with the town demographics services.
When I got my masters’ degree, 10 years ago, and I was looking for a job, if I said I liked dealing with data and numbers to find patterns, I would get the response “The business side doesn’t deal with finding patterns, that’s the data analysts’ job”. There were only a few data analysts around (and it often sounded like they were all shut up in a room together, and not allowed out).
Today, when I tell our customers that I have a degree in Statistics and I have worked with Neural Networks and open source tools, they get all starry-eyed and excited.
Times have changed. But one thing has not. Over that whole period — in fact, for over 40 years, now — SAS has been working with machine learning.
Today, however, machine learning is shifting from algorithm-based (think decision trees, neural nets, and random forests) to process-based (get actual decisions from machine learning). I think there are three key elements to a successful Analytics 4.0 strategy in a company:
Let’s think of a practical example: the approval of a loan. This is normally based on a combination of analytics and business strategies. Small disclaimer here: this blog won’t discuss regulatory or privacy issues, although these are key aspects to address when implementing ANY of the above!
The modeling works like this:
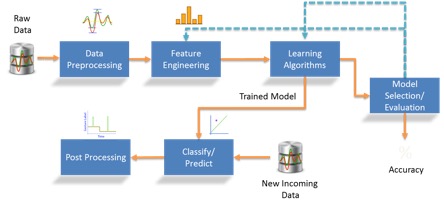
This process happens offline: the learning algorithms step might take advantage of supervised algorithms like regressions, decision trees, random forests, gradient boosting, neural nets, and others. When a model is selected, an API of the overall process is generated, including steps like variable transformation, and imputation of missing data. This can be used in real time by a front-end application, to provide new data. When the model performance decays, or simply after a defined period, data scientists restart the process and select a new model. Is the machine learning? Yes, because of the way the learning algorithms work: automatically and iteratively.
But is this artificial intelligence? Not yet. What happens when we add that?
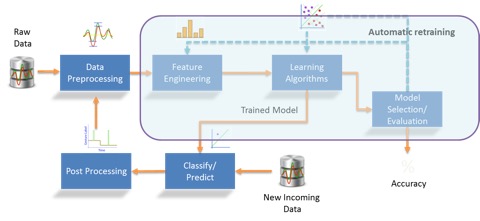
Now, the process of model selection is automated. The system goes through the initial training process again, considering new data made available during a particular time period. Ideally, a new algorithm, with different variables, might be selected as a result of this process. This scenario is suitable if the outcome of the label we’re investigating makes itself known within the period (for example, it is not possible to know immediately whether a customer will default). This cannot be “continuous learning”, because we have to wait until the label value becomes available before we can update the models. We can, however, make learning as frequent and automatic as possible, so that data scientists only have to make sure that the model is still accurate.
The idea of continuous learning means that the information for the machine to learn must available immediately, and there is also a ‘learning window’ of data to use. This ‘window’ calls for a different type of real-time execution: not a triggered, one-in-one-out observation, but a streaming, window-listening scenario where the engine waits and listens for events as they happen. Obviously, the two types of logic complement each other.
An example of continuous learning is constant unsupervised learning, where the clusters that separate customer groups (or transactions) keep learning and adjusting with every new transaction. Unstructured data provides a more complex example, particularly if we try to simulate human learning, for example, adjusting a conversation to the audience. For a loan approval, the artificial agent may be on the phone to a customer about the loan application, and adjusting the decisions on the approval, price, and loan amount, based on models, rules, and continuous learning from the ongoing dialogue. We can visualize this as:
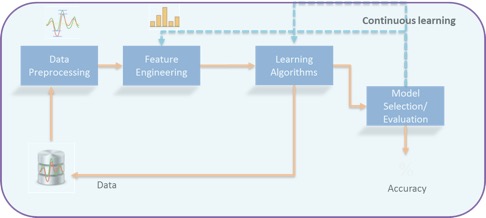
Does this mean we don’t need data scientists anymore?
Does this mean we don’t need data scientists anymore? Not at all. Quite the reverse: we need them more than ever, as they will have to set up this scenario and ensure that the process operates efficiently and correctly. We also need them because not all data and analyses are suitable for continuous learning.
Does this mean we don’t need data scientists anymore? #MachineLearning #DataScientist Share on XDoes this sound interesting? I certainly think it is! SAS can help your organization move towards an analytics economy. If you’d like to learn more, you can contact me directly via email or social network or visit us at www.sas.com, communities.sas.com, blog.sas.com, http://developer.sas.com and support.sas.com.
This blog post was first published June 14th 2017 on www.biblogg.no.
