 In Part 1, Udo provided SAS code to replicate the example in Hyndman's blog. Below, he shows the results of out-of-sample testing, and draws some conclusions on the computational efficiency of this approach.
In Part 1, Udo provided SAS code to replicate the example in Hyndman's blog. Below, he shows the results of out-of-sample testing, and draws some conclusions on the computational efficiency of this approach.
Out-of-sample Testing
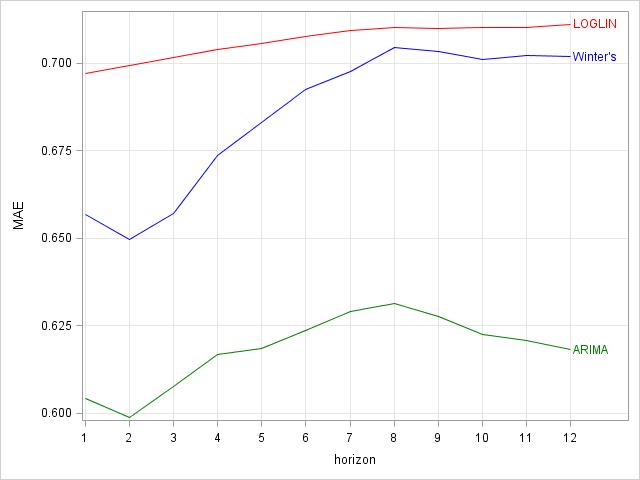
In addition to the example shared by Hyndman, out-of-sample data was used to illustrate the final performance of the winning model. The last 12 month of A10 were used as out-of-sample data, which changes the MAE plot above, as less data is available for cross-validation (again, ARIMA is the preferred model):
The new cross validation plot:
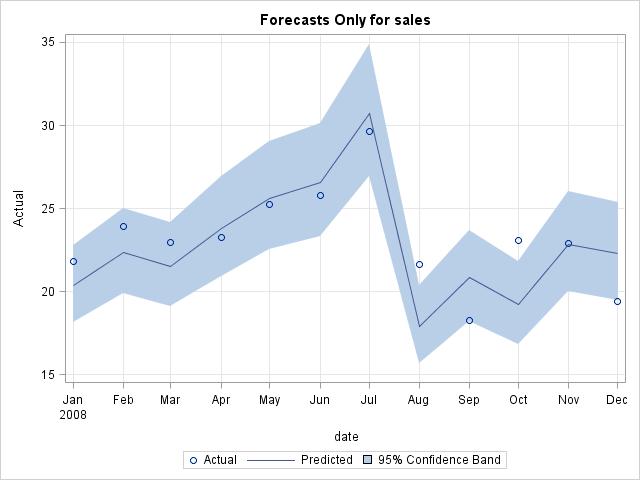
Forecast plot:

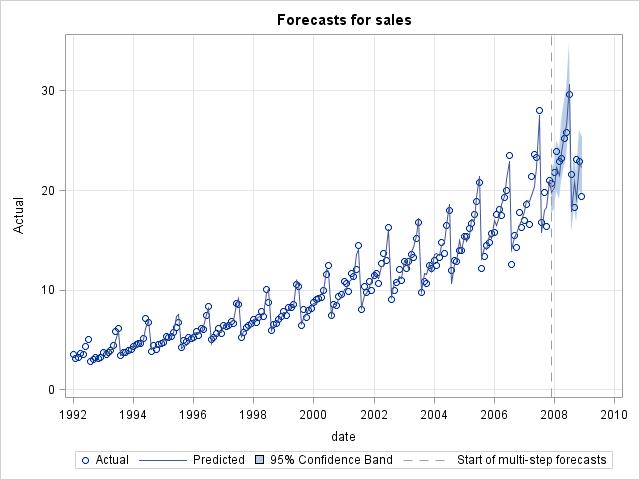
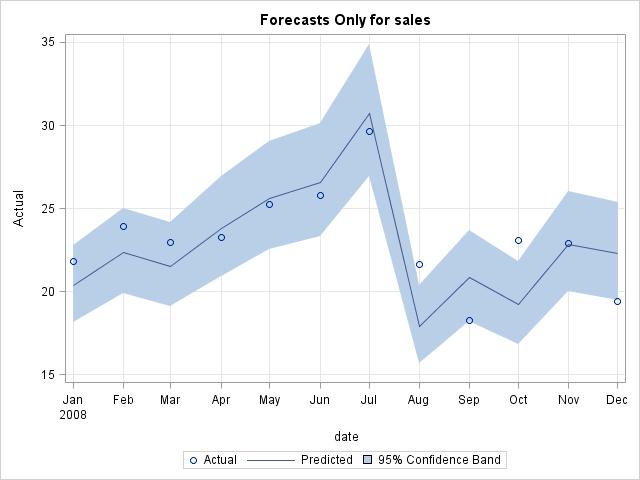
Forecast region only plot:
Conclusion
Time series cross-validation as suggested by Hyndman can be implemented using SAS High-Performance Forecasting today. Cross-validation is a computationally intensive approach to assessing forecast model performance, so this needs to be taken into account when trying to apply it on large scale data. Nevertheless, each iteration of cross-validation (for each lead time) can be run independently, so a multi-threaded approach might improve the overall run-time (by running on several processors in parallel). It should also be noted that in this example the forecasting models candidates are already known, which might not be the case in large-scale environments for all series at hand.

{kind=link}
{kind=link}
{kind=link}
1 Comment
Pingback: Rob Hyndman on Time-Series Cross-Validation - The Business Forecasting Deal