Data virtualization simplifies increasingly complex data architectures
Every few months, another vendor claims one environment will replace all others. We know better. What usually happens is an elongated state of coexistence between traditional technology and the newer, sometimes disruptive one. Eventually, one technology sinks into obsolescence, but it usually takes much longer than we expect. Think of TV and radio – or podcasts and radio – and how they've coexisted for years.

The result is an increasing complex environment – "heterogeneous architectures" – built up from years of accretion and acquisition of database systems, applications and middleware. Instead of replacing, we create increasingly purpose-built environments for the most predominant use cases. This makes things run faster or more efficiently, but it also means we have to maintain multiple environments customized for different purposes. Sometimes that requires new skills that aren't easy to find. For example, running data quality processes in memory will speed performance – but generally we have less memory available than disk space. So the cost of running in-memory is often factors greater than disk. There will always be a cost argument for maintaining both an on-disk and an in-memory environment, custom built for different uses.
What becomes more important is agility and the ability to reuse skills, rules and processes in different environments. At SAS, we call this managing data where it lives, beyond conventional boundaries. SAS Data Management, for example, runs in the optimal execution environment, moving the processing to the data for improved performance, governance and productivity.
In response to this fragmented environment and need for agility, there's a dramatic rise in data virtualization, because it provides a virtual, secure view of your data without moving it. As a result, IT can be more agile in giving business users an abstracted view of data. Abstracted data layers help streamline modernization efforts because data sources can be modified without changing any of the business logic in the calling applications. By using abstracted views of data, for example, I can pull my demographic data from Hadoop instead of Oracle. The marketing people using an application based on the extract are none the wiser, because they're looking only at the view and are not concerned about the data's physical location.
SAS Federation Server: Data virtualization, data masking and data quality in one
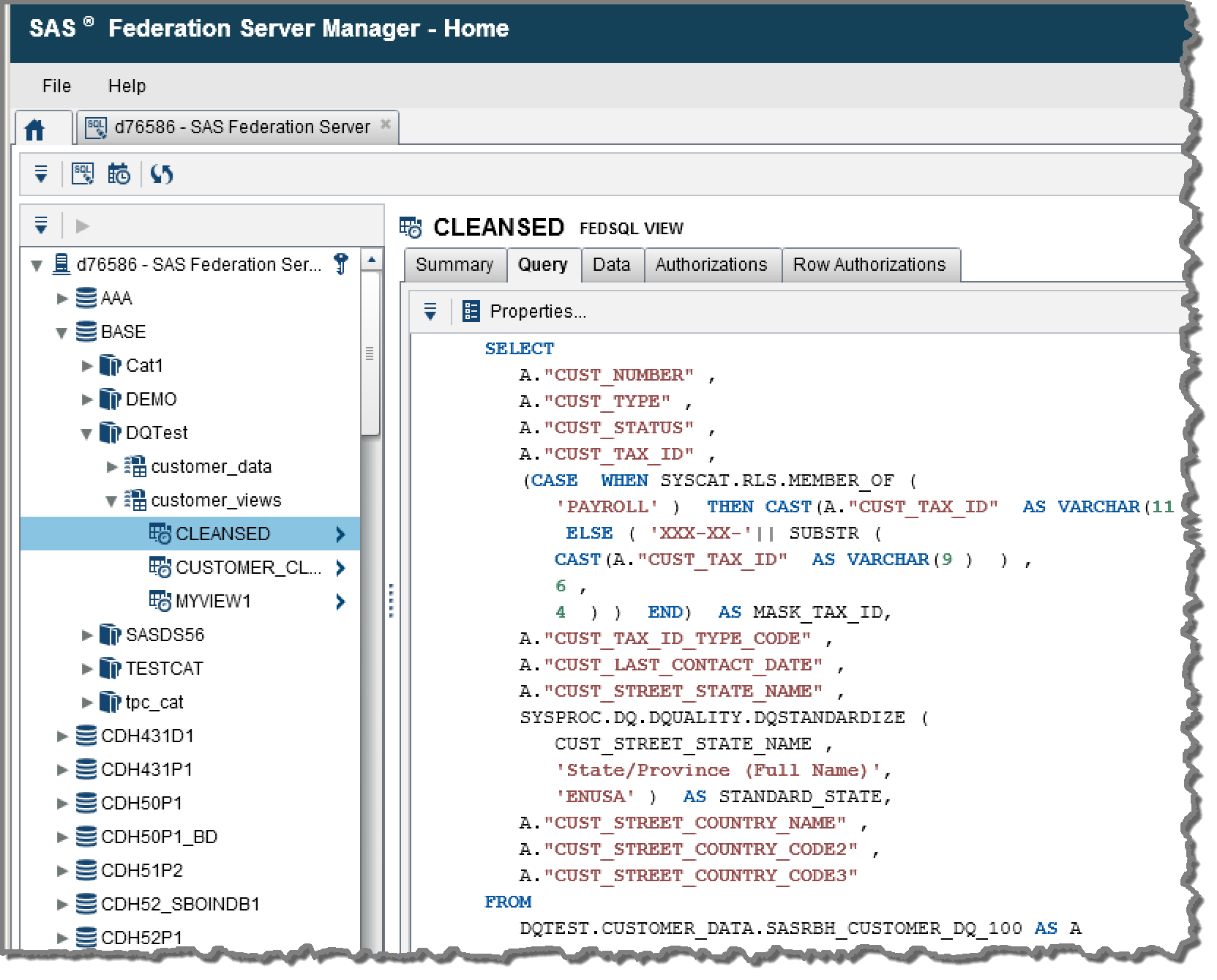
SAS provides data virtualization capabilities via SAS Federation Server. In addition to dynamic data masking, this solution also provides in-memory caching and a centralized area to monitor and create queries. In its most recent release, Version 4.2, it delivers better performance, security, integration and trust.
- Improved performance with native Hadoop driver, DS2 code push-down execution. With this version, SAS added a native Hadoop driver (via Hive) and Impala support via ODBC. Those familiar with SAS DS2 code can run scoring, data manipulation and other functions inside the database (as long as the appropriate SAS Code Accelerators or in-database technologies are present).
- Better security with dynamic data masking. With rampant data breaches becoming more severe every day, security is now more important than ever. SAS improved the role-based hashing and encryption capabilities in SAS Federation Server by adding several data randomization functions. To illustrate: A customer service rep might only be allowed to see a random set of SSN digits while a loan officer can view the actual number.
- Simplified integration with SAS solutions with shared metadata. Many companies talk about shared metadata. But SAS is one of the few that has a portfolio of solutions spanning data management and analytics with the ability to view lineage across both domains. This means the same users, groups and logins can be shared. It also reduces the time to value for integrating with existing SAS Analytics solutions.
- Higher accuracy with on-demand data quality. Parsing, match-code generation, gender analysis and identification analysis are just a few of the data quality functions that can now be called in real time as the view is generated. So the marketing team consuming data gets trusted data with standardized state codes and verified addresses. In the past, this might have happened in a staging area with a different process. Now SAS can use the same prebuilt data quality rules and run them inside an event stream, in real time inside of a virtual view, or in a batch process that runs over night.
Data virtualization via SAS Federation Server is another arrow in the quiver of tools for enterprise architects and data professionals to bring to bear as they navigate today's increasingly complex data environments. To learn more, download this 60-second scoop.






