Bigger doesn’t always mean better. And that’s often the case with big data. Your data quality (DQ) problem – no denial, please – often only magnifies when you get bigger data sets.
Having more unstructured data adds another level of complexity. The need for data quality on Hadoop is shown by user feedback in the latest TDWI Best Practices Report "Hadoop for the Enterprise." 55% of the respondents plan to integrate DQ in the next three years. So how to take care of big data quality?
Well, there is good news. You don’t have to learn Java and implement complex MapReduce code to fix quality issues in the data within a Hadoop cluster. SAS Data Loader for Hadoop comes with data quality directives that help business users detect and repair data problems quickly and easily.
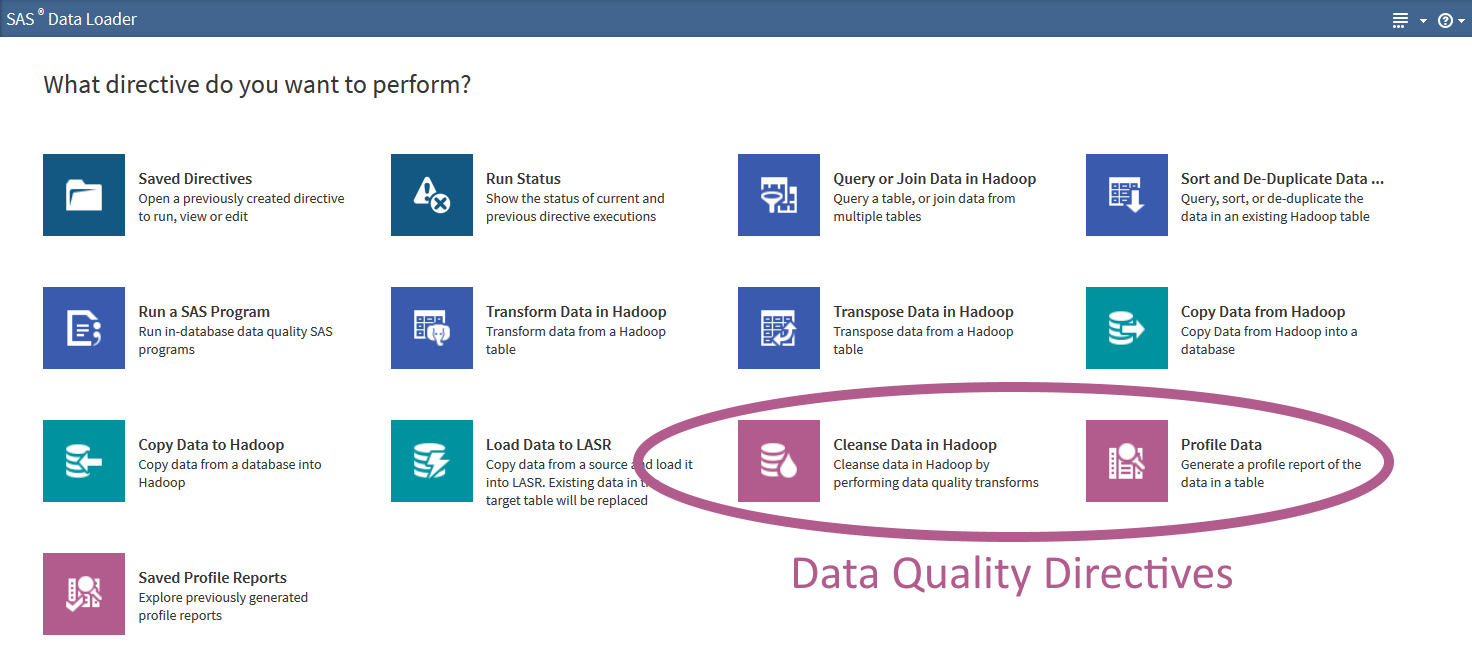
As a first step, it is a good idea to profile the data set to get an understanding of how bad the situation is and which columns need some rework. The "Profile Data" directive in SAS Data Loader for Hadoop presents the result as an easy-to-understand report.
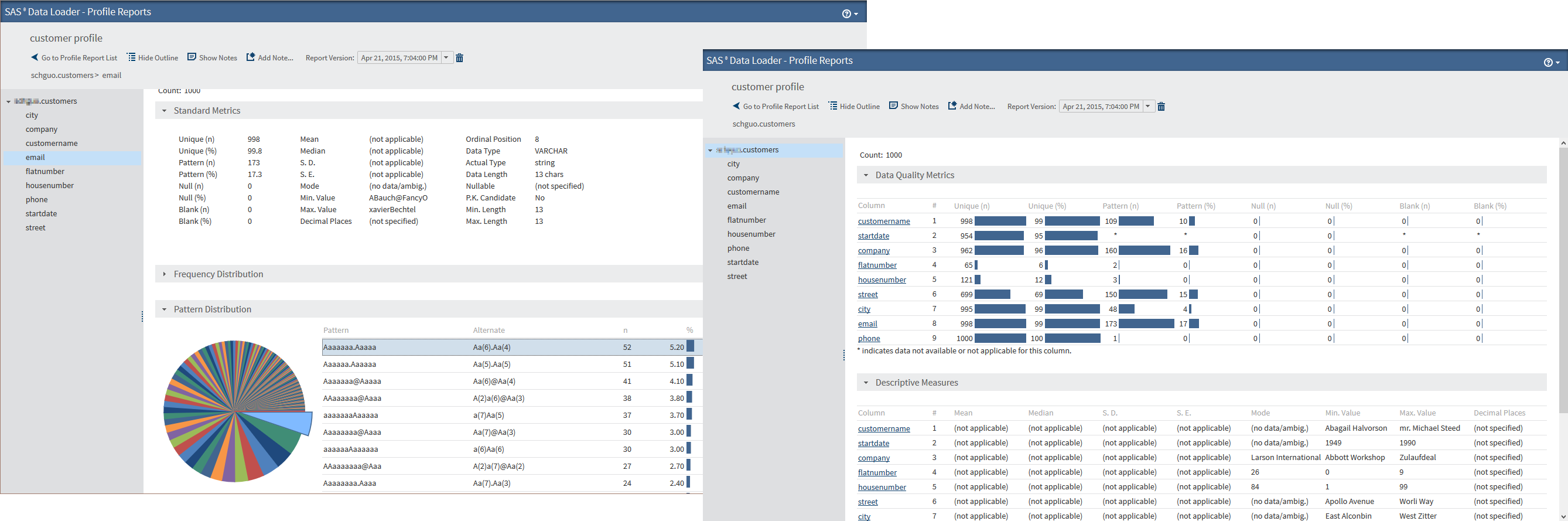
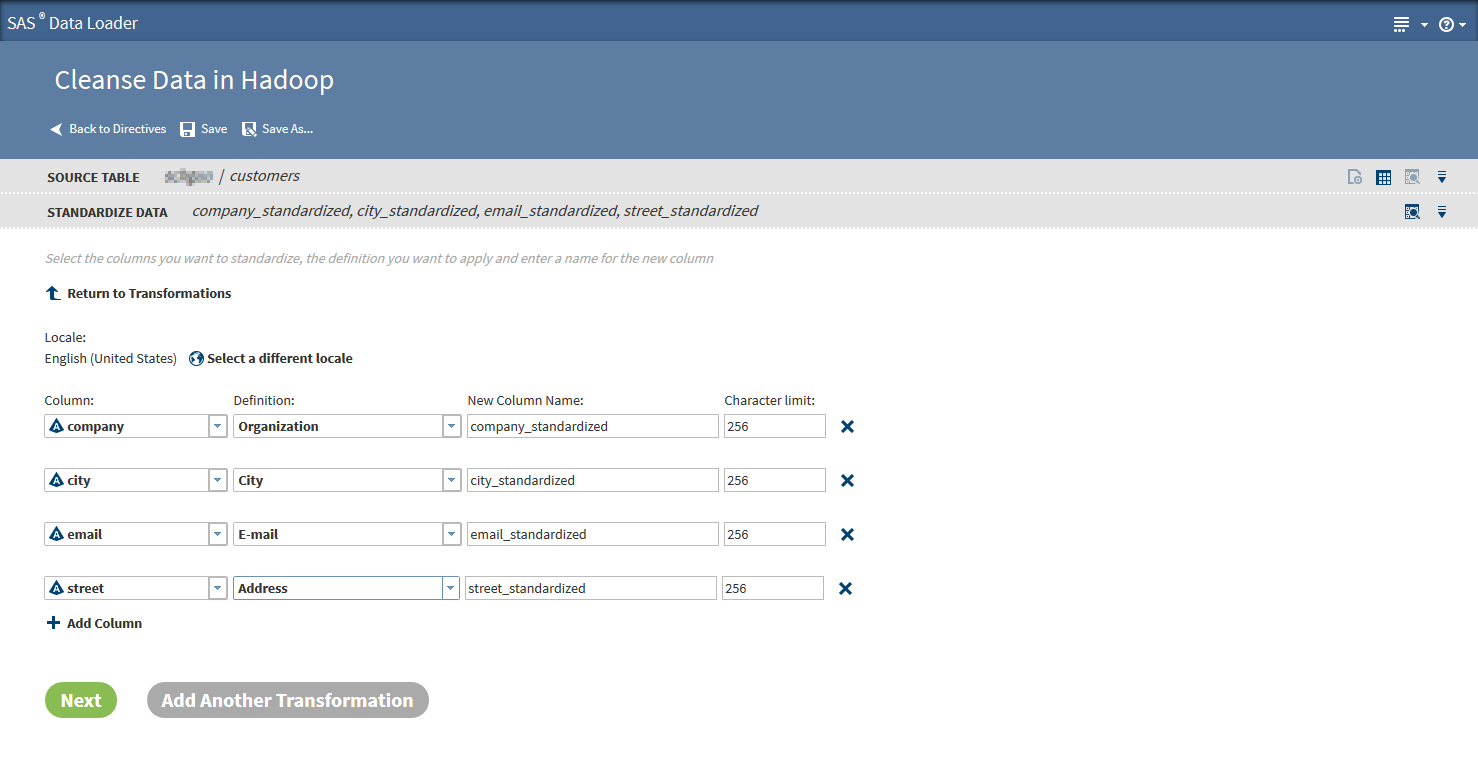
The profiling report helps you understand the strengths and weaknesses of your data. After you define the data quality issues, the "Cleanse Data in Hadoop" directive offers many functions to automatically clean the flawed entries. It is possible to combine the transformation steps, and each one will ask for specifics when configured.
Since the actual cleaning of the data is done within the Hadoop cluster, this directive will work even on extremely large amounts of data. It’s fast, too. All processing is distributed and in parallel.

The SAS Quality Knowledge Base (used on the Hadoop data nodes to clean the data) contains a vast amount of information and logic that define data management operations performed without any data movement. For example, the Quality Knowledge Base knows that the name “Andrea” is probably a female name in Germany, but might be a male name in Italy. It knows what emails and phone numbers look like in the (many) supported locales and is able to correct the format without any manual intervention.
It's also possible to reliably separate first name and last name or street, number, postal code and city into their own columns. That makes it much easier to perform reporting or analytics on this data.
Based on HTML 5, the modern, intuitive user interface can also be used from mobile devices. After all, what’s more fun than spending a day on the beach with your tablet, cleaning your 5 TB customer database?
If you are a longtime SAS programmer, you can always launch the data quality functionality out of Base SAS code as well. This way you can make data quality part of your (big data) ETL (or, more appropriately, ELT) processes.
If you want more information regarding data quality on Hadoop, visit SAS Data Quality and the SAS Data Loader for Hadoop. While you're there, sign up for a free trial of SAS Data Loader for Hadoop, and learn how to make big data quality a reality.

3 Comments
Guido,
A useful reminder that data quality is a key success factor in big data analytics, however, it is also worth remembering that there are different aspects/dimensions to data quality. The approach described can help with invalid data and also, to a limited extent, can provide a means to overcome some aspects of missing data. The data quality dimension that these tools will struggle to address, and is arguably the most important, is data accuracy.
Data that is valid and appears plausible will not necessarily be flagged up as a data quality problem if it is inaccurate. Therefore, analysis using such data may produce spurious outputs. This indicates that you will still need to undertake some form of data accuracy sampling in order to confirm that analysis outputs are correct.
Julian Schwarzenbach
Hi Julian,
you are right - taking care of DQ in Data-Prep is no substitute for validating data later on in the analytical process.
Actually both are equally important and it turns out that dealing with large amounts of data (trying to avoid Big Data here.. ;) can become an issue in the data preparation phase. The Data Loader for Hadoop can help here a lot and speed up things. This saved time can be better used in the later phases of the analytical process - e.g. validating results as you correctly suggested.
Cheers,
Guido
Pingback: Data Management y hadoop: claves para una integración de datos exitosa - SAS Colombia