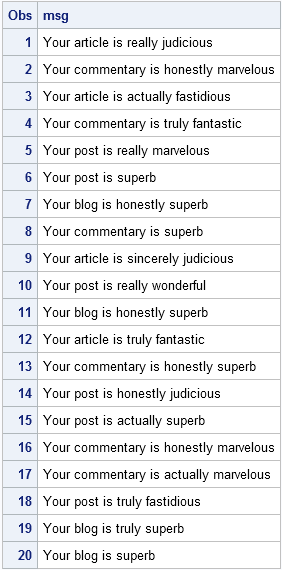
Survey says sampling still sensible

In my previous post, I discussed sampling error (i.e., when a randomly chosen sample doesn’t reflect the underlying population, aka margin of error) and sampling bias (i.e., when the sample isn’t randomly chosen at all), both of which big data advocates often claim can, and should, be overcome by using all the data. In this