Na tym etapie nasza organizacja posiada już określone cele biznesowe dla programu Data Governance (krok 0) oraz rozpoczęła zarządzanie pojęciami biznesowymi, które opisywał krok 1.
Krok 2: śledzenie przepływu danych w organizacji
Data Governance to nie tylko rozumienie znaczenia danych - to także świadomość, w jaki sposób te dane i informacje są przez organizację przetwarzane, w jakich systemach funkcjonują oraz jakim transformacjom są poddawane. Każda organizacja posiada podstawy tego typu perspektywy Data Governance. W najprostszej postaci są to najczęściej rozproszone w organizacji zbiory metadanych towarzyszące systemom informatycznym, hurtowniom danych, repozytoriom raportowym lub samym wizualizacjom i raportom. Nie zawsze zakres informacji gromadzonych we wspomnianych metadanych jest dostatecznie szeroki, aby objąć zarówno opis techniczny, jak i opis merytoryczny dla danych, ale jest to bardzo dobry początek, który warto wykorzystać.
Skonsolidowanie technicznych aspektów przepływu danych w organizacji możliwe jest dzięki wykorzystaniu narzędzia SAS Lineage.
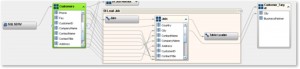
W oparciu o mechanizmy gromadzenia i ekstrakcji metadanych z szerokiego zakresu dostępnych źródeł tworzone jest jedno wspólne repozytorium informacji opisujących przepływ danych pomiędzy systemami informatycznymi. Możliwe jest pozyskanie metadanych między innymi z:
- narzędzi do projektowania modeli danych (np. Erwin lub Rational Rose)
- baz danych oraz repozytoriów Big Data
- narzędzi ETL wraz z informacjami o dokonywanych przekształceniach danych
- narzędzi analitycznych i raportowych, gdzie informacje są wizualizowane i udostępniane użytkownikom (np. światy obiektów SAP Business Objects)
- serwera metadanych SAS wspólnego dla wszystkich elementów platformy analitycznej.
Niezależnie od zróżnicowania wykorzystywanych przez organizację narzędzi, możliwe jest doprowadzenie do prześledzenia drogi, którą dane pokonują w infrastrukturze informatycznej. Następnie możliwe jest połączenie ich z już zdefiniowanymi i opisywanymi pojęciami biznesowymi (wspomniany powyżej krok 1).
Tworząc połączenie pomiędzy światem abstrakcyjnych definicji merytorycznych, a światem technicznej reprezentacji danych, uzyskujemy zdolność do ich śledzenia, analizy pochodzenia danych i odnajdywania ich rzeczywistego źródła w organizacji. Czynności te są proste, nie wymagają realizowania wielkich projektów, a co najważniejsze są aktualnym i automatycznie tworzonym obrazem sposobu wykorzystywania informacji przez organizację.
Poprzez zrealizowanie tego kroku organizacja uzyskuje następujące korzyści:
- umiejętność śledzenia pochodzenia danych np. w raportach, co znacząco przekłada się na ich sposób wykorzystania i zaufanie odbiorców oraz coraz częściej jest wymogiem regulacji i zasad funkcjonowania podmiotów np. na rynkach finansowych
- umiejętność oceny wpływu zmian w systemach informatycznych na przepływ informacji, wymagane zmiany w systemach raportowych i systemach wspierania decyzji
- minimalizację ryzyka błędnej interpretacji lub niewłaściwego wykorzystania danych, dzięki szczegółowej historii ich pochodzenia w powiązaniu ze znaczeniem biznesowym i przeznaczeniem danych
Zapraszam także do lektury ostatniego wpisu z tej serii, w którym omówimy co zrobić, gdy inicjatywa Data Governance została już uruchomiona. Zachęcam także do zapoznania się z produktami SAS Data Governance.


2 Comments
Pingback: Data Governance - pierwsze kroki - część 1 z 4 - Bright Data
Pingback: Data Governance - pierwsze kroki - część 4 z 4 - Bright Data