Data and Analytics Innovation using SAS & Spark - part 2

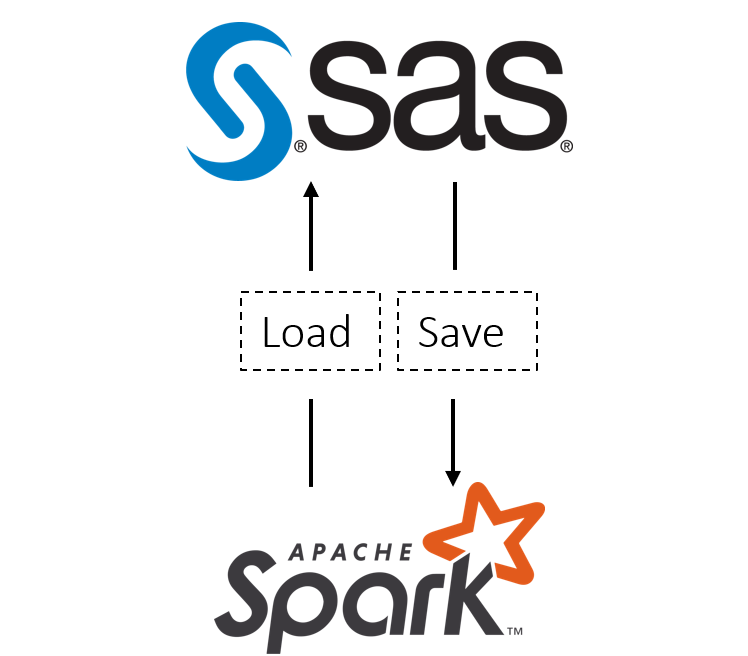
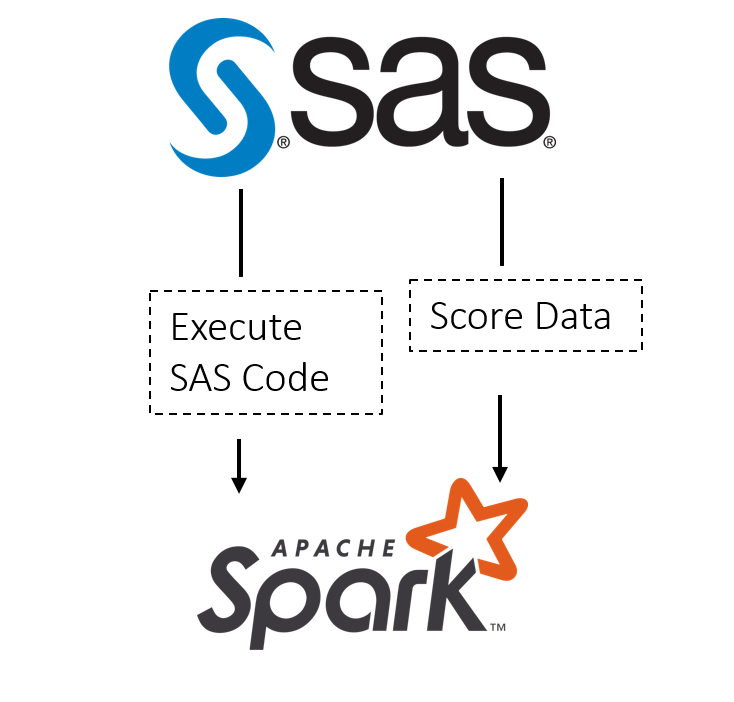
In part 1 of this post, we looked at setting up Spark jobs from Cloud Analytics Services (CAS) to load and save data to and from Hadoop. Now we are moving on to the next step in the analytic cycle, scoring data in Hadoop and executing SAS code as a